はじめに:LLMの「理解」は錯覚だった?
ChatGPTやClaudeなどの大規模言語モデル(LLM)と対話していると、まるでAIが文章の意味を「理解」しているかのように感じることがあります。しかし、これは錯覚です。
このページでは、LLMの仕組みを「物理」と「数学」の視点から解体し、なぜコンテキストの拡張が難しいのか、そしてどのような対策があるのかを、初心者にもわかりやすく解説します。
- メカニズムの解体 ― 「理解」の錯覚を捨て、条件付き確率の現実を見る
- O(N²)の壁 ― 自己アテンションとハードウェアが引き起こす計算量爆発の数学的制約
- エンジニアリングの突破口 ― 今日の現実的対策(RAG/分割)と明日のアーキテクチャ(SSM/線形アテンション)
1. LLMは「理解」していない ― 条件付き確率マシン
錯覚と現実
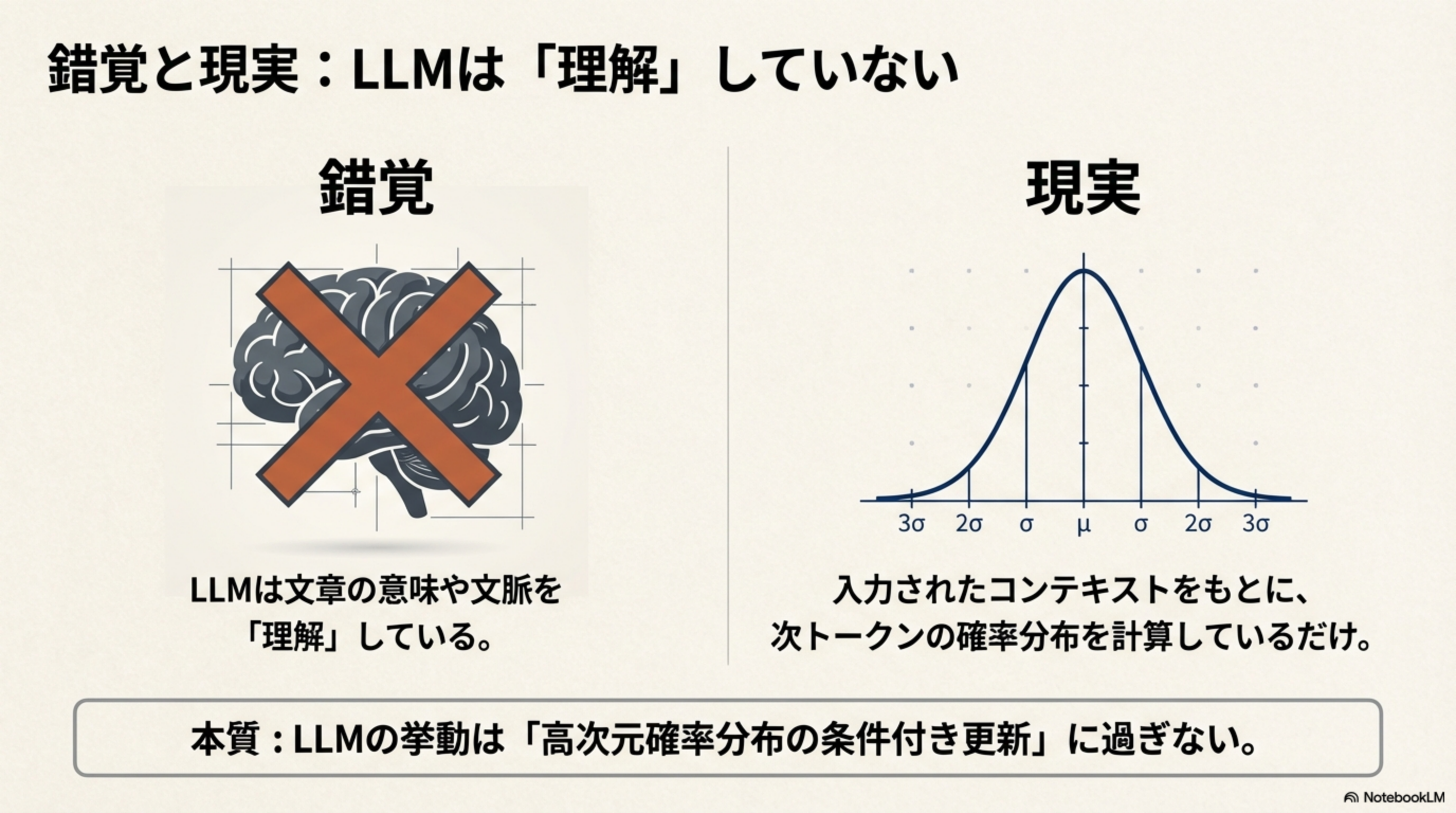
多くの人は「LLMは文章の意味や文脈を理解している」と思い込んでいます。しかし、現実はもっとシンプルです。
錯覚(よくある誤解)
LLMは文章の意味や文脈を「理解」している。人間のように考えて回答を生み出している。
現実(実際の仕組み)
入力されたコンテキストをもとに、次トークンの確率分布を計算しているだけ。
LLMの挙動は高次元確率分布の条件付き更新に過ぎません。「理解」ではなく「統計的な次の単語予測」が行われているのです。
たとえ話:超高性能な「しりとりマシン」
LLMを理解するために、こんなたとえを考えてみましょう。あなたの前に、何兆もの文章を読んで育った「しりとりマシン」がいます。このマシンは「しりとり」のように、前の言葉(コンテキスト)に基づいて「次に来そうな言葉」を確率的に選んでいるだけです。しかし、あまりにも大量のデータから学習しているため、結果として「理解しているかのように見える」回答が出てくるのです。
2. コンテキスト追加の真のメカニズム
「コンテキストを追加すれば、LLMの理解が深まる」と思いがちですが、これも正確ではありません。実際に起きているのは次のことです。
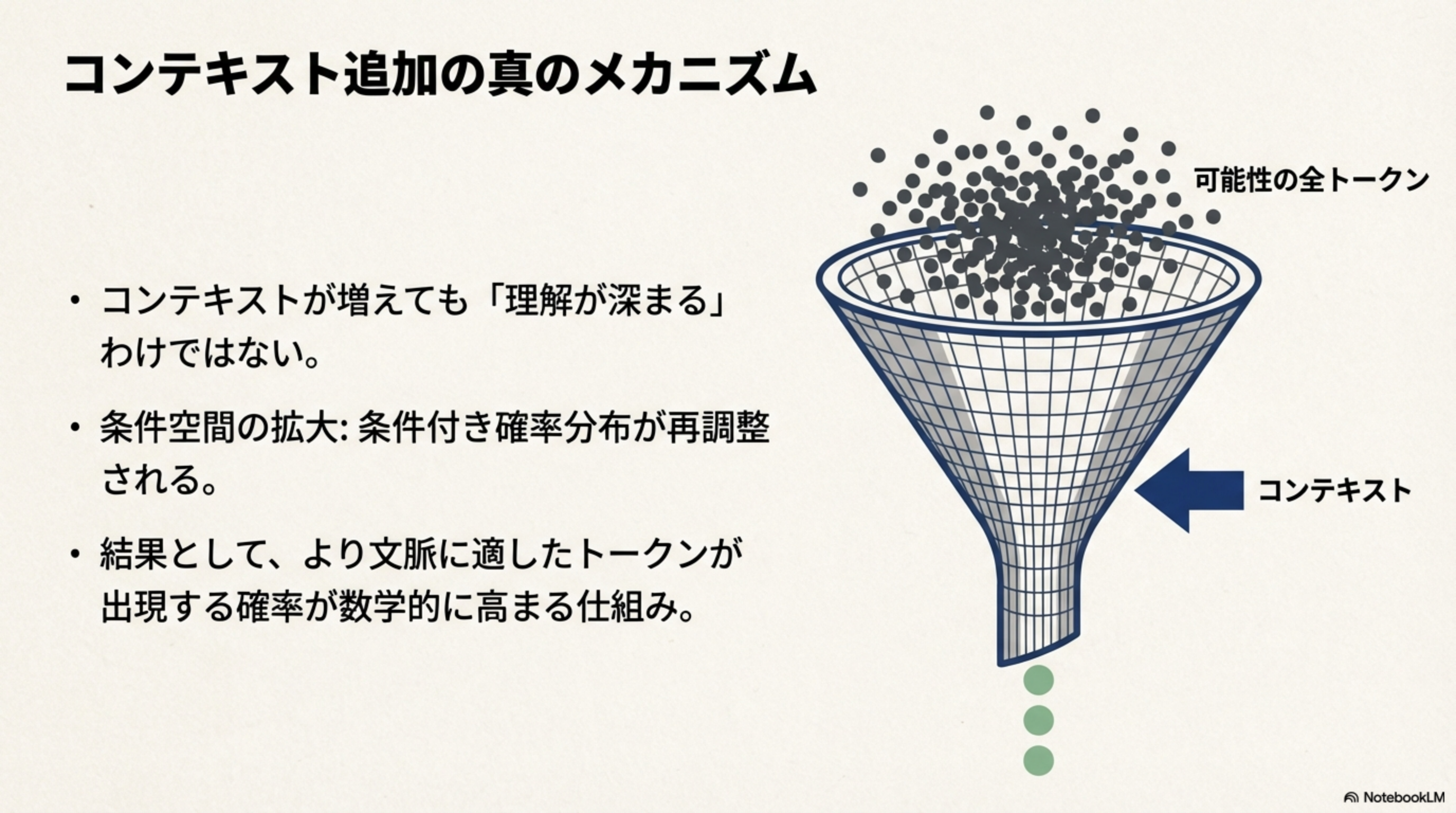
- コンテキストが増えても「理解が深まる」わけではない
- 条件空間の拡大:条件付き確率分布が再調整される
- 結果として、より文脈に適したトークンが出現する確率が数学的に高まる仕組み
「東京の天気は」という入力だけでは、次のトークンの選択肢は「晴れ」「雨」「曇り」などが均等に近い確率です。しかし「2024年1月1日の東京の天気は」とコンテキストを追加すると、学習データに基づいて確率分布が偏り、より「正解に近い」トークンが選ばれやすくなります。
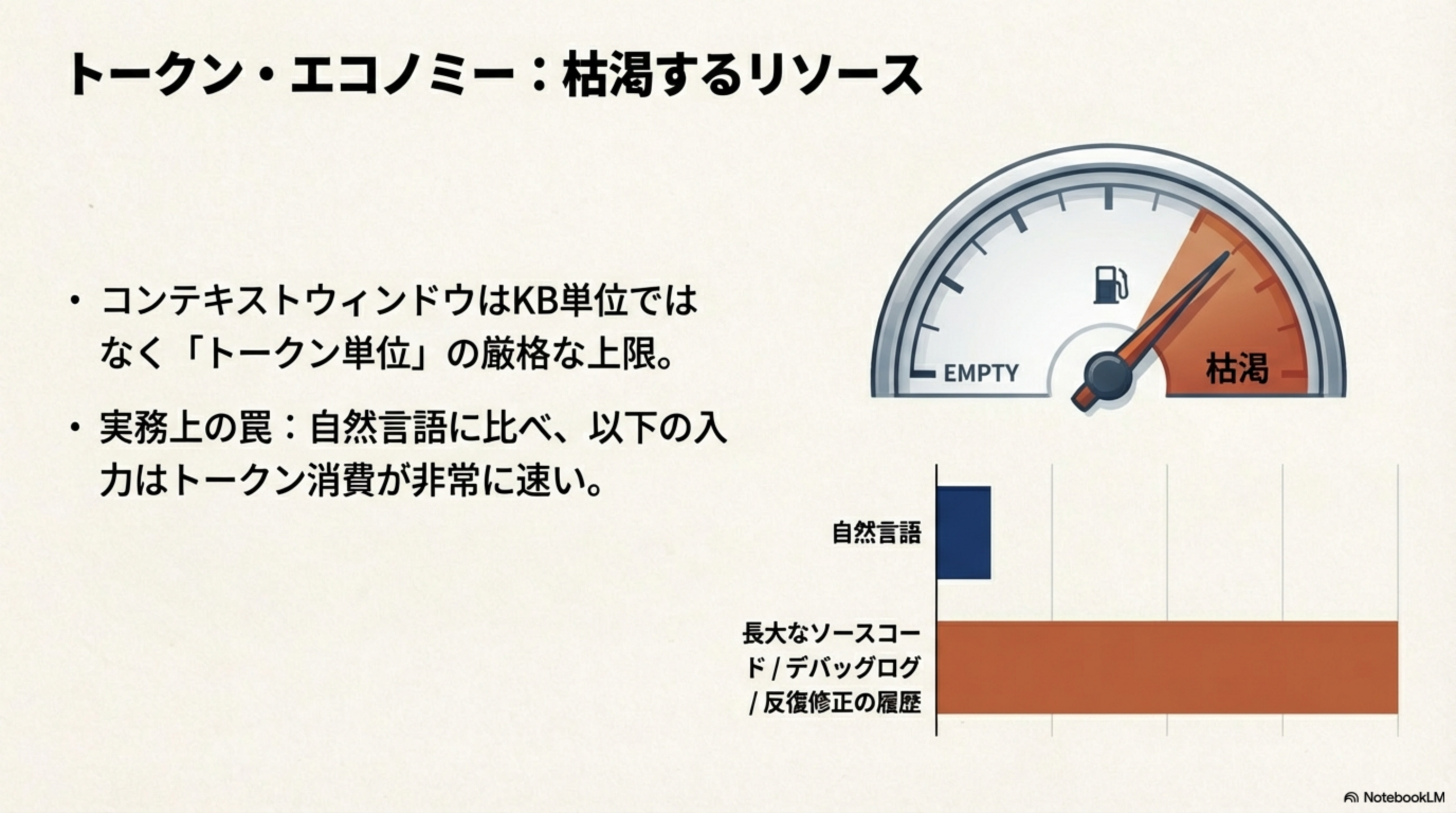
3. トークン・エコノミー:枯渇するリソース
コンテキストウィンドウとは、LLMが一度に処理できるテキストの「容量」のことです。ここで重要なのは、この容量はKB(キロバイト)単位ではなく、「トークン」単位の厳格な上限であるということです。
トークンとは?
トークンとは、LLMがテキストを処理する最小単位です。日本語の場合、1文字が1トークンとは限らず、ひらがな1文字で1トークン、漢字1文字で1〜2トークンになることがあります。英語では、1単語が約1.3トークン程度です。
自然言語のテキストに比べて、以下の入力はトークン消費が非常に速いことに注意が必要です:
- 長大なソースコード ― インデントや記号が多くトークンを消費
- デバッグログ ― 繰り返しの多いテキストでもトークンは消費される
- 反復修正の履歴 ― 会話が長くなるほど過去の履歴がトークンを圧迫
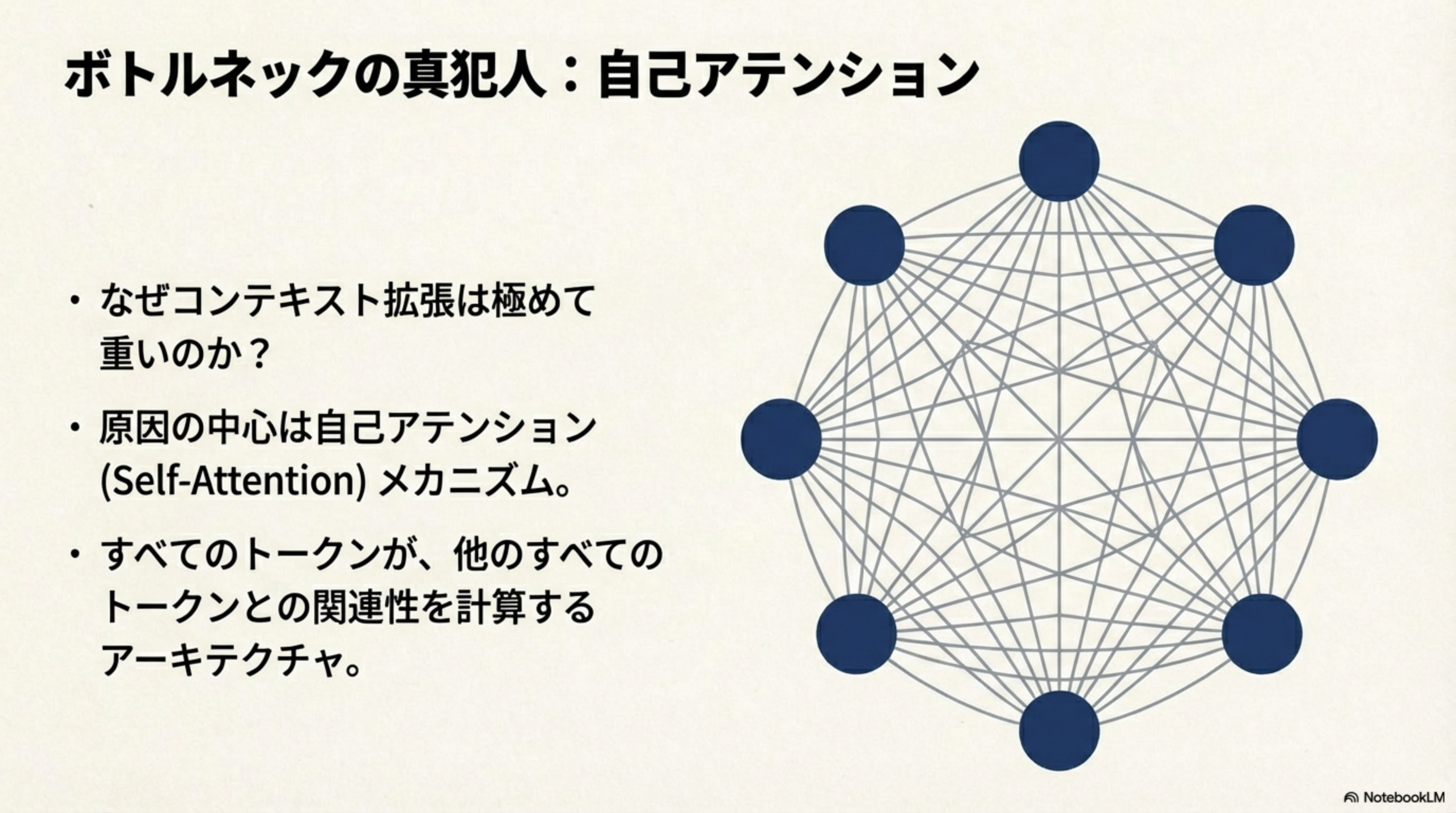
4. ボトルネックの真犯人:自己アテンション
なぜコンテキストの拡張は極めて「重い」のでしょうか?原因の中心にあるのが自己アテンション(Self-Attention)メカニズムです。
自己アテンションとは?
自己アテンションとは、入力されたすべてのトークンが、他のすべてのトークンとの関連性を計算する仕組みです。
30人の教室で「全員が全員と1回ずつ握手する」場面を想像してください。30人なら 30 × 29 / 2 = 435回の握手が必要です。しかし、60人になると 60 × 59 / 2 = 1,770回に跳ね上がります。人数が2倍になっただけで、握手の回数は約4倍になるのです。自己アテンションもまったく同じ構造です。
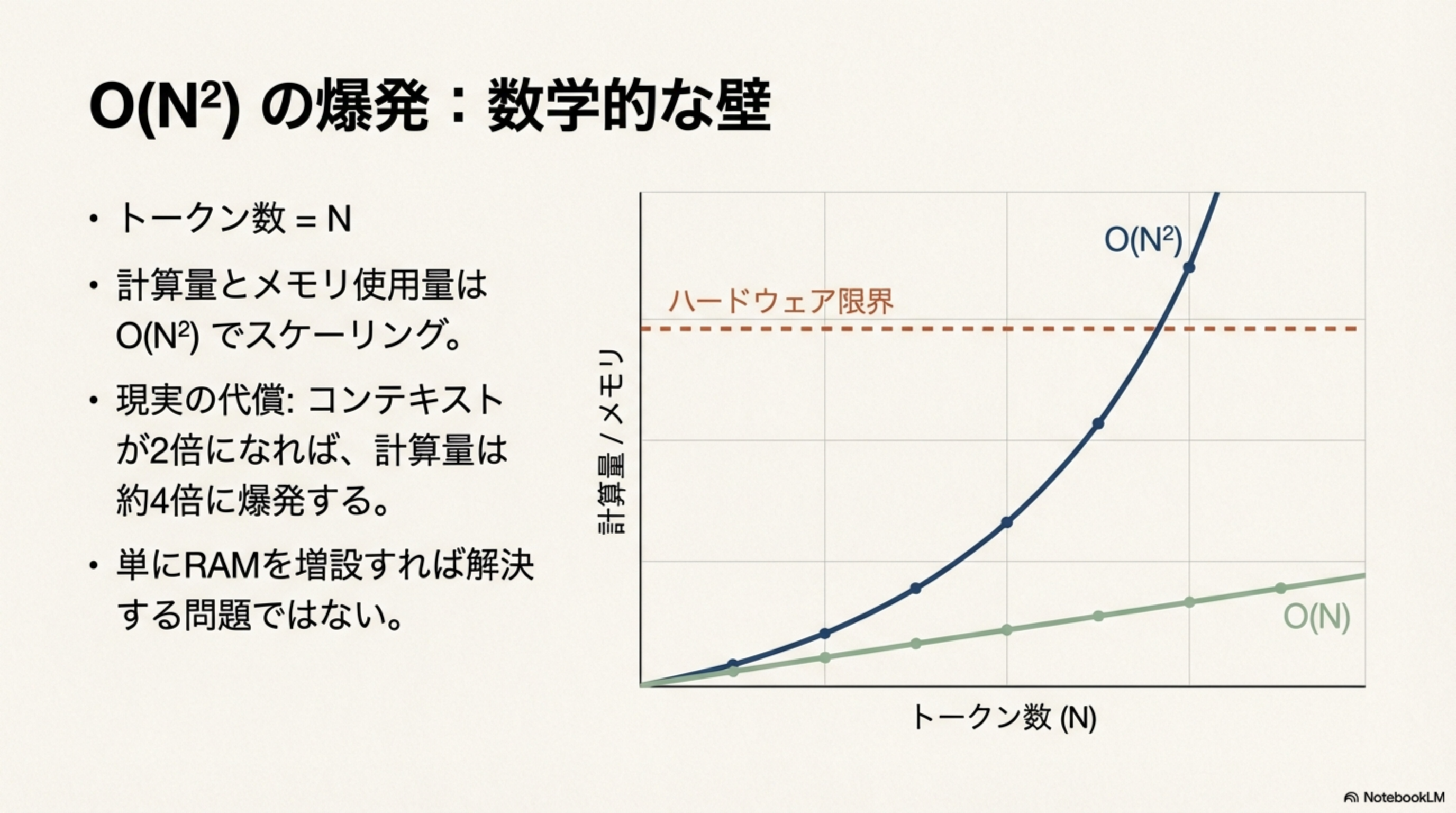
5. O(N²)の爆発:数学的な壁
自己アテンションの「全員と握手」構造がもたらす数学的な制約を見てみましょう。
計算量のスケーリング
- トークン数 = N
- 計算量とメモリ使用量は O(N²) でスケーリング
- コンテキストが2倍になれば、計算量は約4倍に爆発する
- 単にRAMを増設すれば解決する問題ではない
| トークン数 (N) | 計算量(相対値) | イメージ |
|---|---|---|
| 1,000 | 1倍 | 短いプロンプト |
| 2,000(2倍) | 4倍 | 普通の質問 |
| 4,000(4倍) | 16倍 | 長めのコード付き質問 |
| 8,000(8倍) | 64倍 | 詳細な文書分析 |
| 128,000(128倍) | 16,384倍 | GPT-4の上限付近 |
6. ハードウェアのトリレンマ
コンテキスト拡張は、単なるソフトウェアの問題ではなく、過酷な物理的・ハードウェア的問題でもあります。O(N²)の処理には、以下の3つのリソースへの極端な依存が発生します。
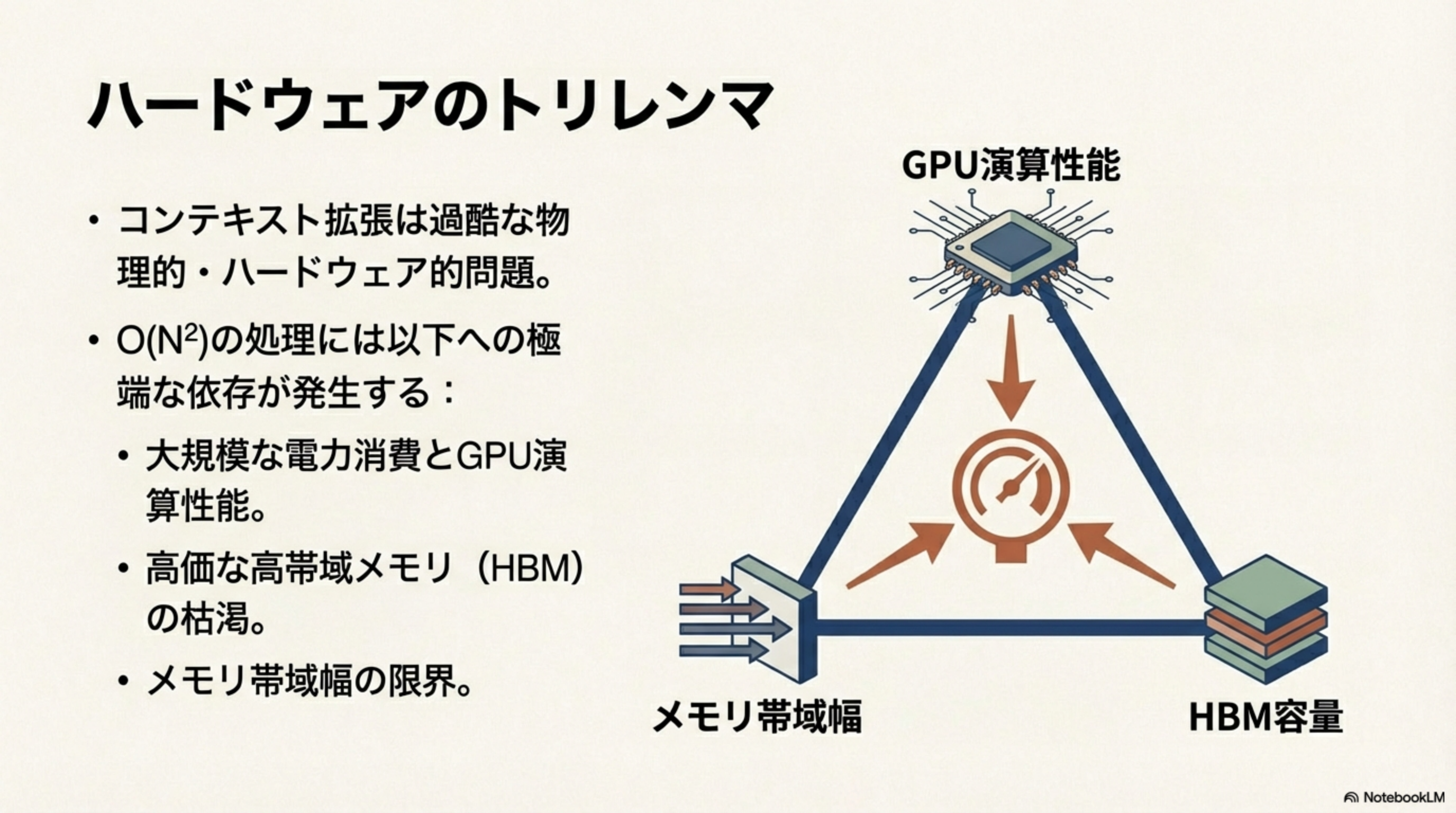
- GPU演算性能 ― 実際に計算を行う処理能力。O(N²)の計算量は膨大な演算力を要求します。
- HBM容量 ― 高帯域幅メモリ(HBM: High Bandwidth Memory)。GPUに搭載される高速メモリで、非常に高価です。
- メモリ帯域幅 ― メモリとGPU間のデータ転送速度。どれだけ速くデータを読み書きできるかの上限です。
GPU演算性能は「料理人の腕」、HBM容量は「冷蔵庫の大きさ」、メモリ帯域幅は「キッチンの広さ(食材を出し入れする速さ)」です。どんなに腕のいい料理人でも、冷蔵庫が小さければ大量の食材を保管できず、キッチンが狭ければ料理が渋滞します。LLMもまったく同じ制約に縛られているのです。
7. 今日の戦術:限界を回避するエンジニアリング
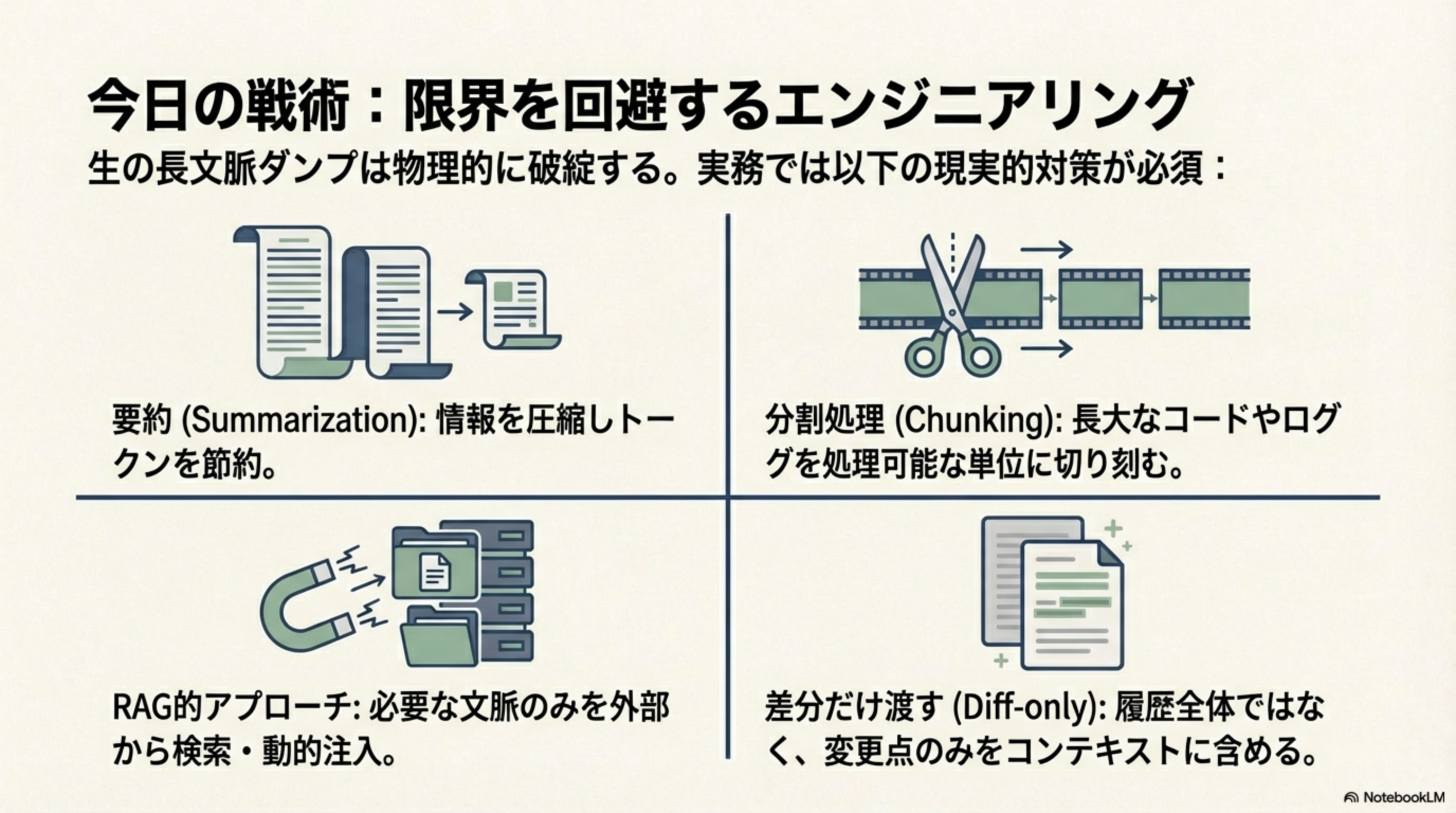
生の長文脈ダンプは物理的に破綻します。現時点では以下の現実的な対策が必須です。
要約(Summarization)
情報を圧縮しトークンを節約する方法。長い文書を短い要約に変換してからLLMに渡すことで、同じ情報を少ないトークンで伝えられます。
分割処理(Chunking)
長大なコードやログを処理可能な単位に切り刻む方法。例えば10万行のコードを1000行ずつに分割して処理します。
RAG的アプローチ
RAG(Retrieval-Augmented Generation)は、必要な文脈のみを外部データベースから検索し、動的にコンテキストに注入する手法です。
差分だけ渡す(Diff-only)
履歴全体ではなく、変更点のみをコンテキストに含める方法。例えばコード修正時には全ファイルではなく、変更した部分だけを渡します。
これらの手法は単独で使うよりも組み合わせて使うことで効果を発揮します。たとえば「RAGで関連部分を検索 → 要約して圧縮 → 差分だけをコンテキストに含める」というパイプラインが実務では有効です。
8. 次世代アーキテクチャ:壁を破壊する研究
O(N²)の制約を根本から迂回・改善するために、現在さまざまなアプローチが研究されています。
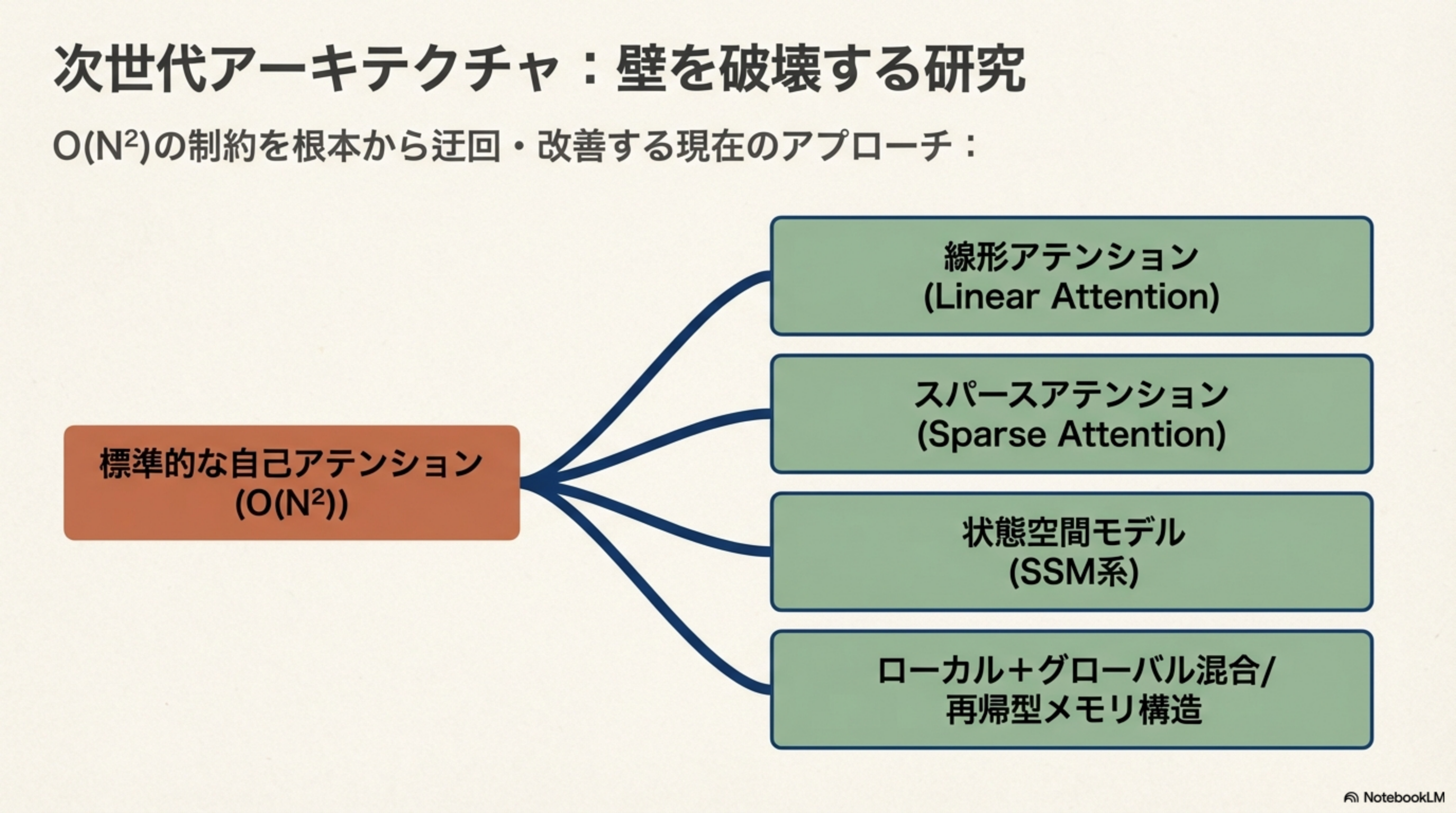
| アプローチ | 代表例 | 概要 |
|---|---|---|
| 線形アテンション | Linear Transformer | Softmaxを近似し、行列の掛け算順序を変えることで O(N) に削減 |
| スパースアテンション | Longformer, BigBird | 全対全ではなく「近くのトークン」と「少数のグローバル接続」のみに限定 |
| 状態空間モデル(SSM) | Mamba, RWKV | アテンションを完全に廃止し、状態ベクトルの更新で O(N) 推論を実現 |
| ローカル+グローバル混合 | 再帰型メモリ構造 | 近距離は詳細に、遠距離は圧縮して参照する二段構え |
9. 結論:コンテキストの物理と未来
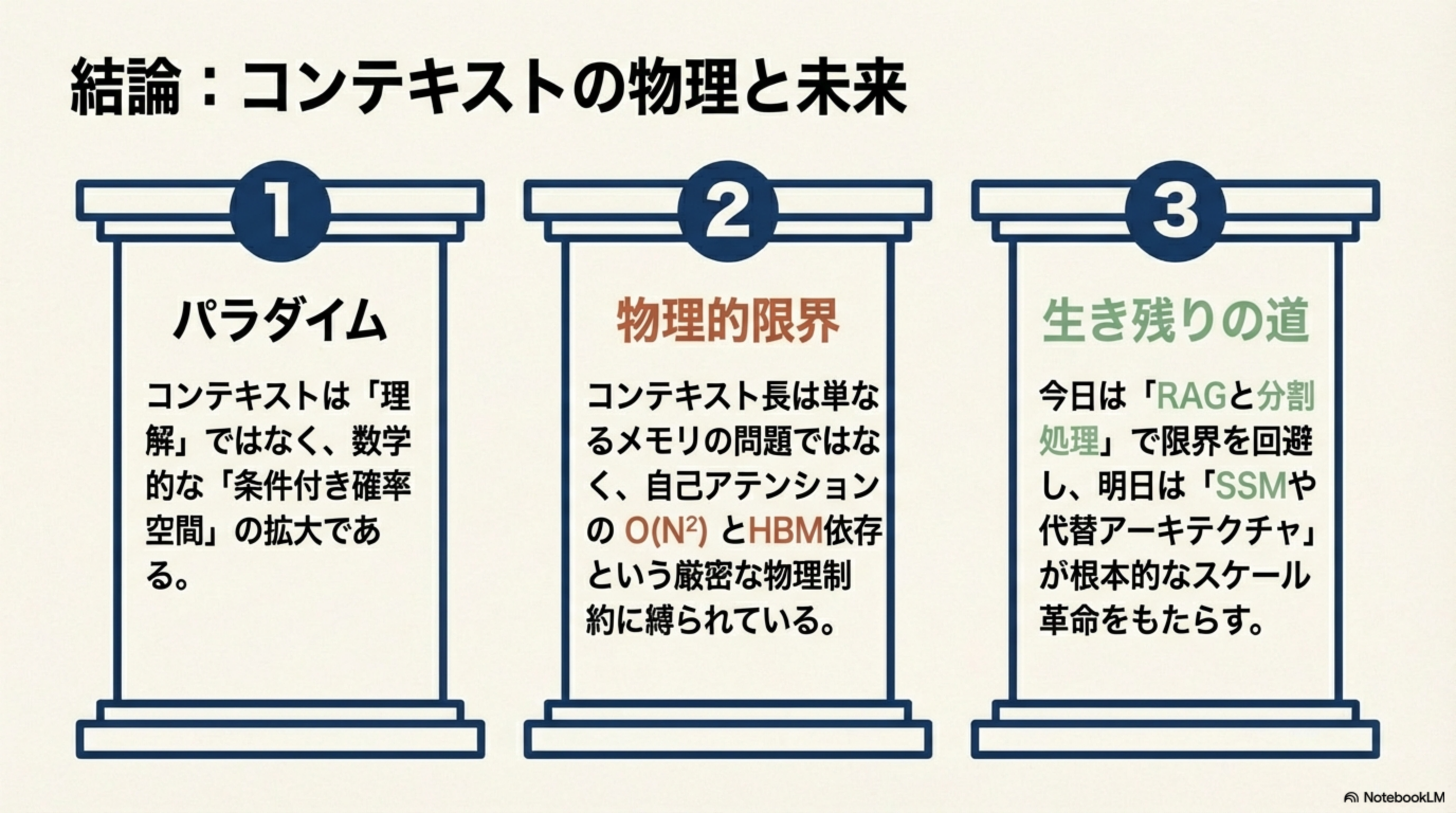
このページで学んだことを3つの柱にまとめましょう。
1. パラダイム
コンテキストは「理解」ではなく、数学的な「条件付き確率空間」の拡大である。
2. 物理的限界
コンテキスト長は単なるメモリの問題ではなく、自己アテンションの O(N²) とHBM依存という厳密な物理制約に縛られている。
今日は「RAGと分割処理」で限界を回避し、明日は「SSMや代替アーキテクチャ」が根本的なスケール革命をもたらす。研究の最終目標は、推論の品質(自己アテンションの精度)を維持しながら、計算量を O(N) または O(N log N) に近づけること。これが実現して初めて、真の「無限コンテキスト」が物理的に可能になります。
O(N²)の壁をどうやって乗り越えるのか、具体的な6つのアプローチについて次のページで詳しく解説します。
元のスライド一覧
クリックで拡大表示できます