はじめに:「大きいほど良い」とは限らない
LLMのコンテキストウィンドウは年々拡大しています。GPT-4の128Kトークン、Claudeの100K+トークン、Geminiの1M+トークン。しかし、コンテキストが大きくなれば本当に回答精度も上がるのでしょうか?
答えは「ノー」です。このページでは、コンテキスト拡大に潜む罠と、各モデルがどのようにこの課題を乗り越えようとしているかを徹底的に解説します。
- 「大きいほど良い」とは限らない ― 文脈長が拡大しても、入力が増えるだけで回答精度は13.9%〜85%低下する「Lost in the Middle」現象が発生。特にGPT-4世代では顕著
- 次世代モデルによる壁の突破 ― GPT-5とGemini 2.5は、アーキテクチャの刷新(推論モードや動的メモリ)により、長文入力時の精度低下を劇的に抑制
- プロンプトエンジニアリングの重要性は継続 ― モデルが進化しても、「重要情報の配置(冒頭・末尾)」や「ノイズの除去」といった戦略は、最大精度を引き出すために依然として不可欠
1. 現象:コンテキストの「中盤」で情報は消失する
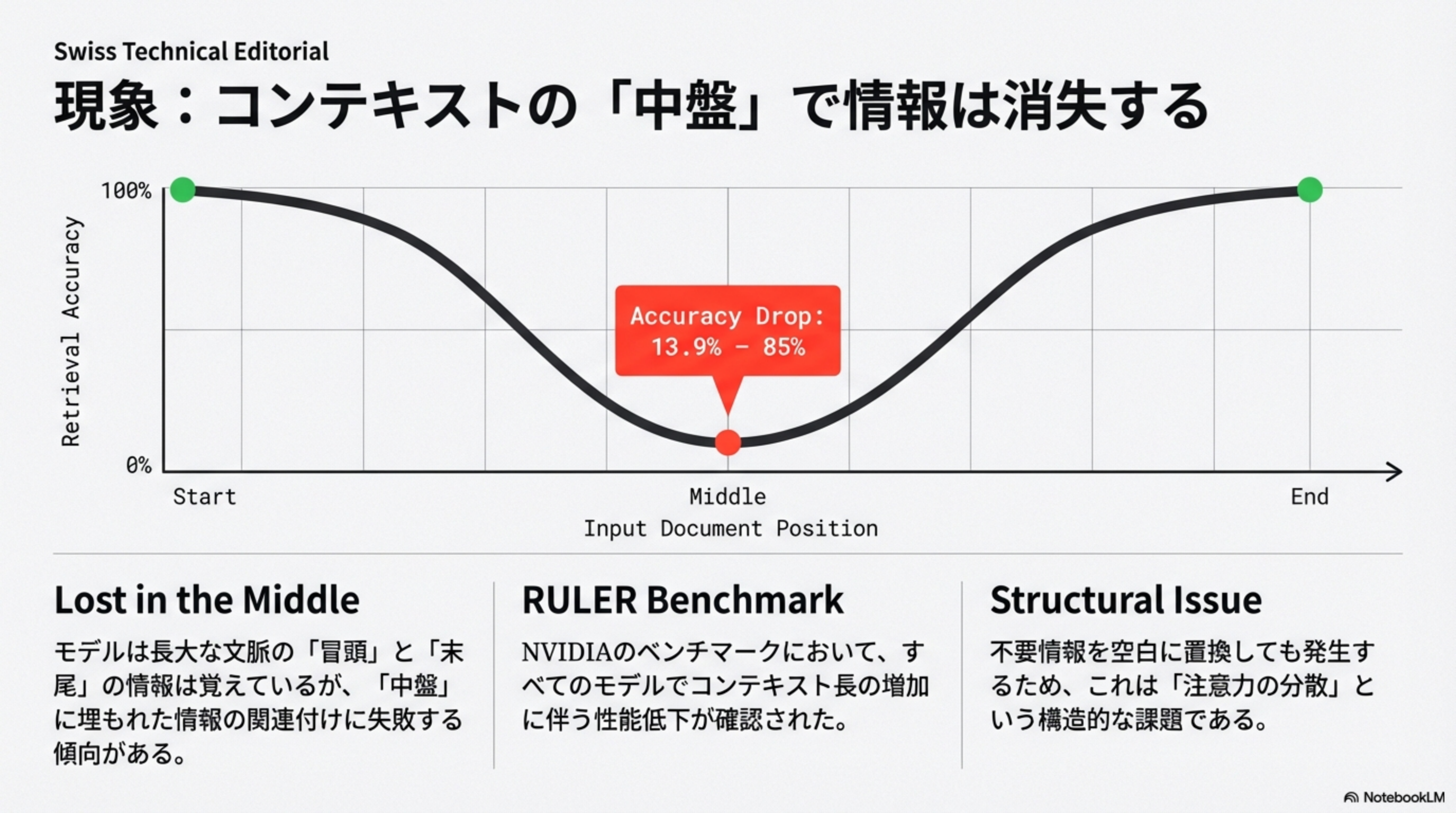
Lost in the Middle(中間消失問題)は、LLMが長い文脈を処理する際に、冒頭と末尾の情報はよく覚えているが、中盤に埋もれた情報の関連付けに失敗する傾向のことです。
なぜこの現象が起きるのか?
Lost in the Middle
モデルは長大な文脈の「冒頭」と「末尾」の情報は覚えているが、「中盤」に埋もれた情報の関連付けに失敗する傾向がある。
RULER Benchmark
NVIDIAのベンチマークにおいて、すべてのモデルでコンテキスト長の増加に伴う性能低下が確認された。
この問題は、不要情報を空白に置換しても発生するため、単なる「情報過多」ではなく「注意力の分散」という構造的な課題です。コンテキストが長くなるほど、アテンション機構が重要な情報に集中しにくくなるのです。
300ページの本を一気に読んだとき、最初の章と最後の章の内容はよく覚えていますが、真ん中あたりの章の内容は曖昧になりがちです。LLMもまったく同じ傾向を持っているのです。
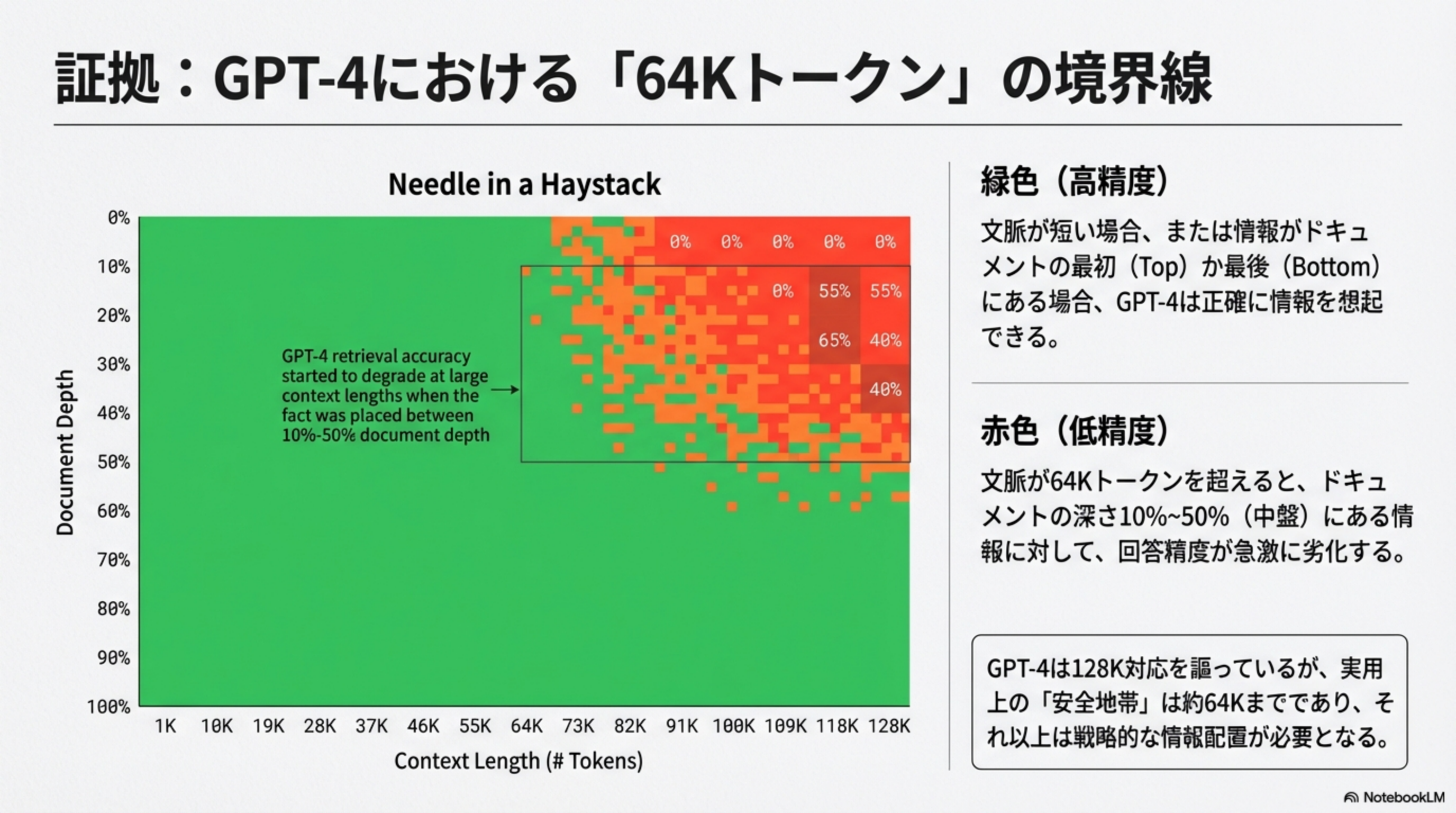
2. 証拠:GPT-4における「64Kトークン」の境界線
GPT-4は公称128Kトークンに対応していますが、実用上の「安全地帯」は約64Kトークンまでです。
Needle in a Haystack テスト
これは「大量のテキスト(干し草の山)の中に、1つの重要な事実(針)を隠して、モデルがそれを見つけられるか」を調べるテストです。
| 条件 | GPT-4の精度 | 説明 |
|---|---|---|
| 短い文脈(〜64K) | 高精度(緑色ゾーン) | 文脈が短い場合、または情報がドキュメントの最初(Top)か最後(Bottom)にある場合、GPT-4は正確に情報を想起できる |
| 長い文脈(64K〜128K)+ 情報が中盤 | 急激に劣化(赤色ゾーン) | 文脈が64Kトークンを超えると、ドキュメント深さ10%〜50%(中盤)にある情報に対して回答精度が急激に劣化する |
GPT-4は128K対応を謳っていますが、実用上の「安全地帯」は約64Kまでであり、それ以上は戦略的な情報配置が必要となります。重要な情報は必ずプロンプトの冒頭か末尾に配置しましょう。
3. Claudeシリーズ:慎重な巨人とプロンプトの鍵
Claude(Anthropic社)は、コンテキスト上限100K+トークンを持つモデルですが、GPT-4とは異なる特徴的な挙動を示します。
デフォルトプロンプト
27%
Claudeは「安全性側」に倒す設計(Safe Refusals)のため、文脈中に確証がないと判断すると回答を拒否する傾向がある。
最適化プロンプト
98%
「該当する一文のみを抜き出して」という具体的な指示を追加し、文脈テーマを調整することで、精度は劇的に向上した。
Claudeの長文性能を引き出すには、モデルの「ためらい」を解消する強力な誘導プロンプトが必須です。具体的には:
- 「文脈から抜粋せよ」と明示する
- 「無い場合は不明と答えよ」とセーフティネットを与える
- 抽出タスクの形式で質問する
4. GPT-5:推論(Reasoning)によるコンテキスト活用
GPT-5はコンテキスト上限400Kトークンを持ち、「Thinking Mode(推論モード)」という新しいアプローチでコンテキスト活用を刷新しました。
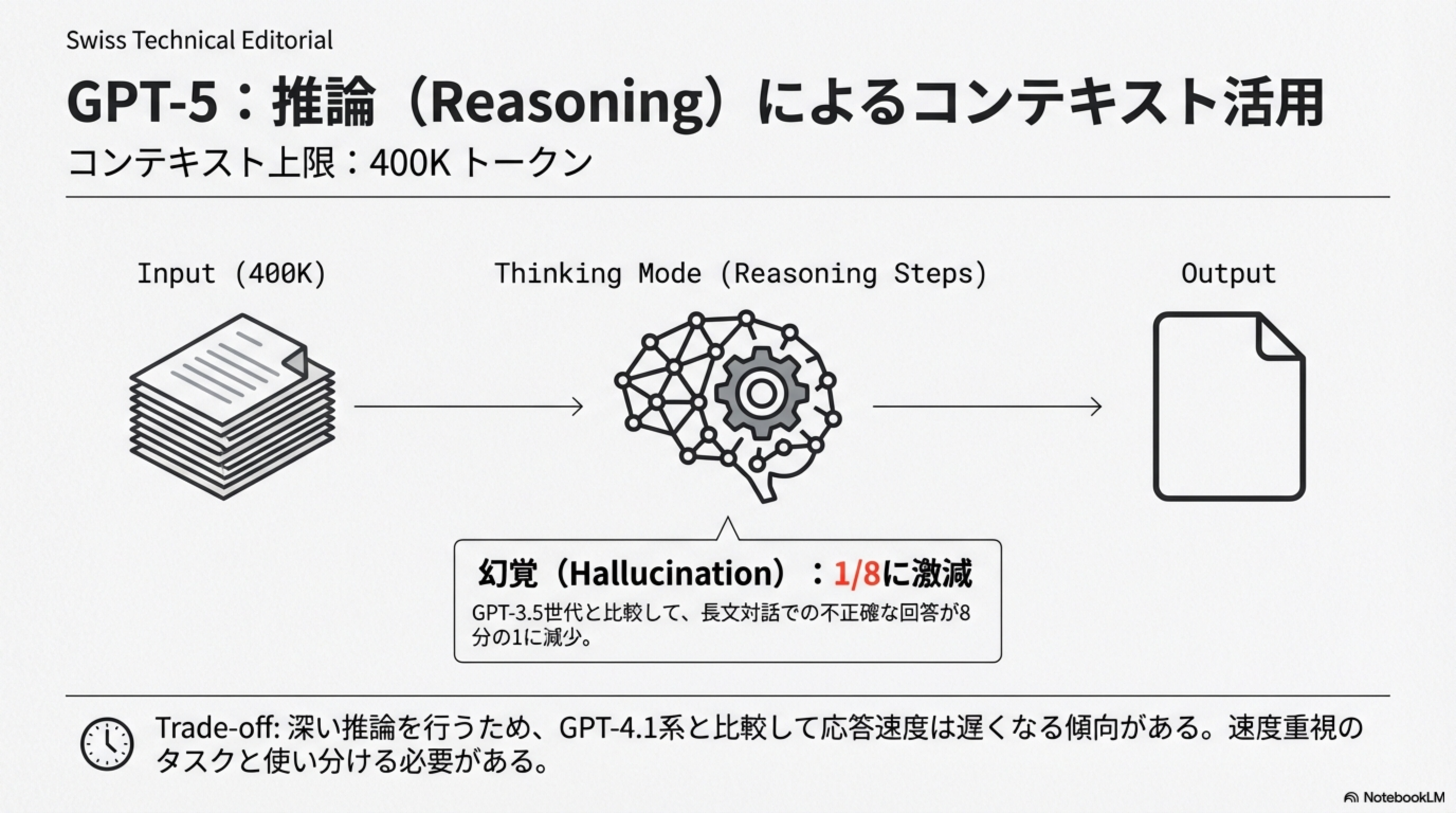
- Thinking Mode ― 入力を受け取った後、内部で推論ステップを踏んで情報を整理・統合してから回答を生成
- 幻覚の激減 ― GPT-3.5世代と比較して、長文対話での不正確な回答が 8分の1 に減少
- 400Kトークン ― 大容量コンテキストを高精度で活用可能
深い推論を行うため、GPT-4.1系と比較して応答速度は遅くなる傾向があります。速度重視のタスクとは使い分ける必要があります。
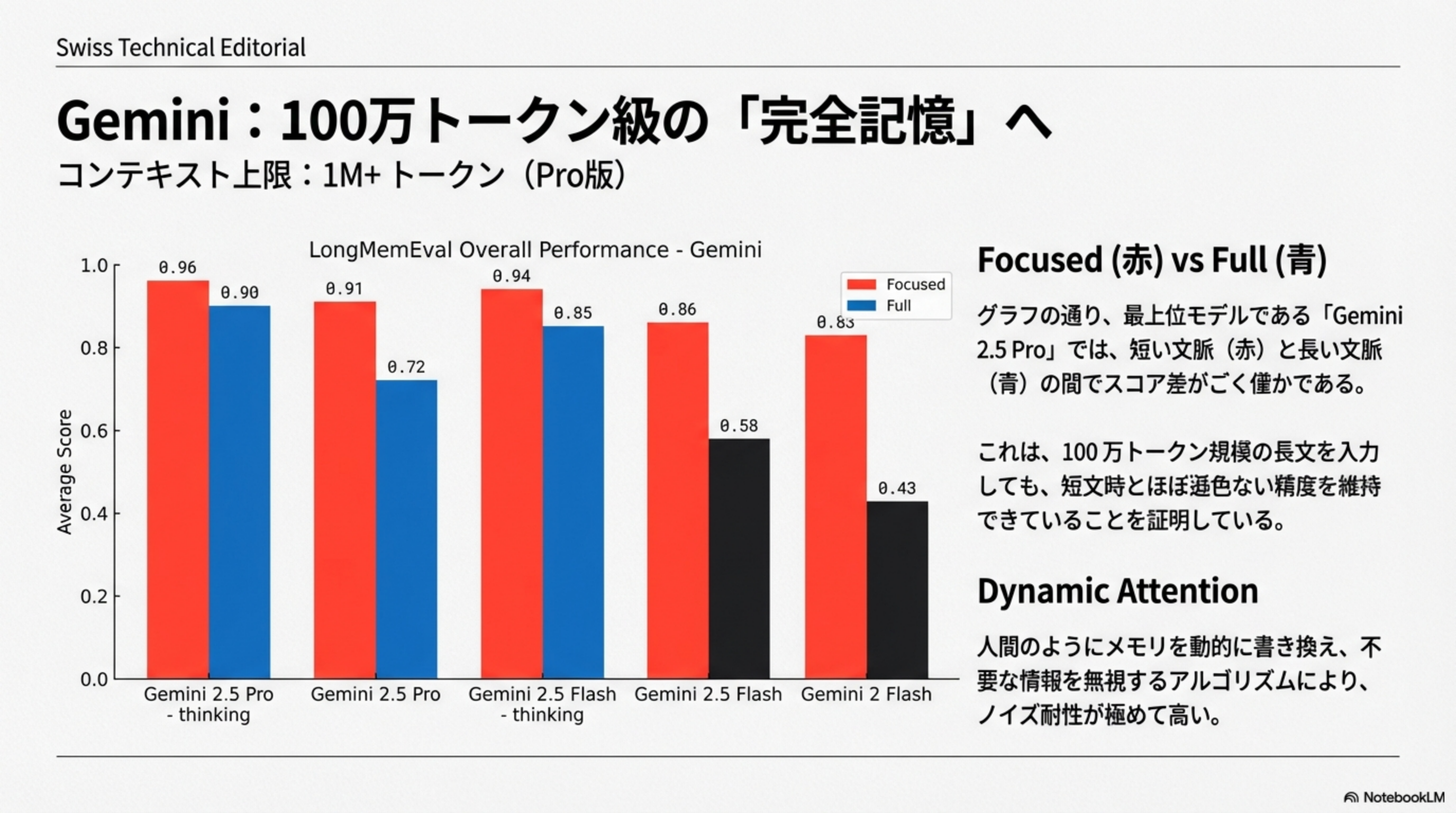
5. Gemini:100万トークン級の「完全記憶」へ
Gemini(Google)はコンテキスト上限1M+トークン(Pro版)を持ち、圧倒的な容量と精度維持を実現しています。
LongMemEval ベンチマーク結果
| モデル | 短い文脈(Focused) | 長い文脈(Full) | 精度差 |
|---|---|---|---|
| Gemini 2.5 Pro - thinking | 0.96 | 0.90 | わずか 0.06 |
| Gemini 2.5 Pro | 0.91 | 0.72 | 0.19 |
| Gemini 2.5 Flash - thinking | 0.94 | 0.85 | 0.09 |
| Gemini 2.5 Flash | 0.86 | 0.58 | 0.28 |
| Gemini 2 Flash | 0.83 | 0.43 | 0.40 |
最上位モデル「Gemini 2.5 Pro」では、短い文脈(赤)と長い文脈(青)の間でスコア差がごく僅かです。つまり、100万トークン規模の長文を入力しても、短文時とほぼ遜色ない精度を維持できていることを証明しています。
Dynamic Attention(動的アテンション)
Geminiの高い長文性能の秘密はDynamic Attentionにあります。人間のようにメモリを動的に書き換え、不要な情報を無視するアルゴリズムにより、ノイズ耐性が極めて高いのです。
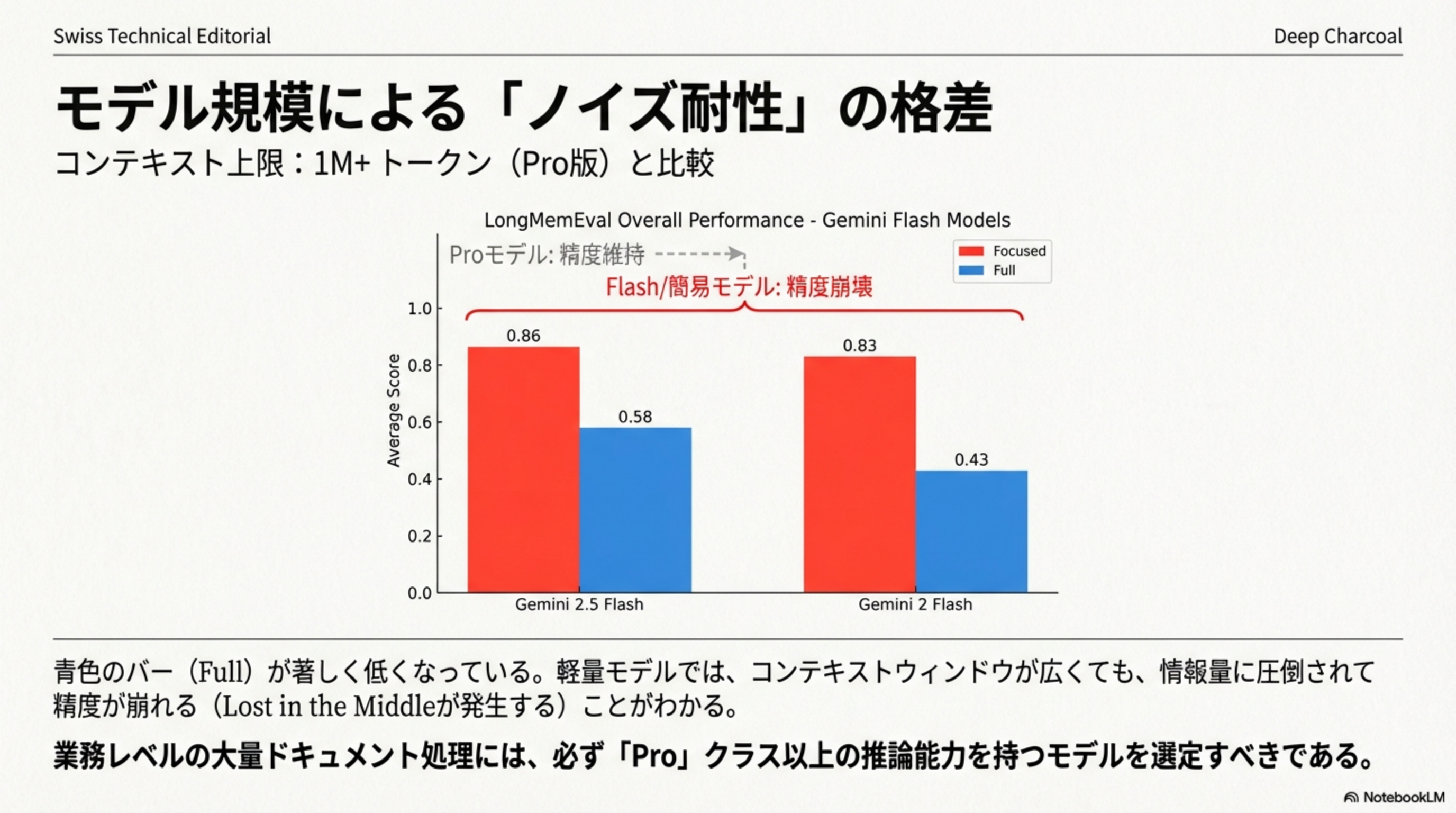
モデル規模による「ノイズ耐性」の格差
Flash/簡易モデルでは、コンテキストウィンドウが広くても情報量に圧倒されて精度が崩れる(Lost in the Middleが発生する)ことがわかっています。業務レベルの大量ドキュメント処理には、必ず「Pro」クラス以上の推論能力を持つモデルを選定すべきです。
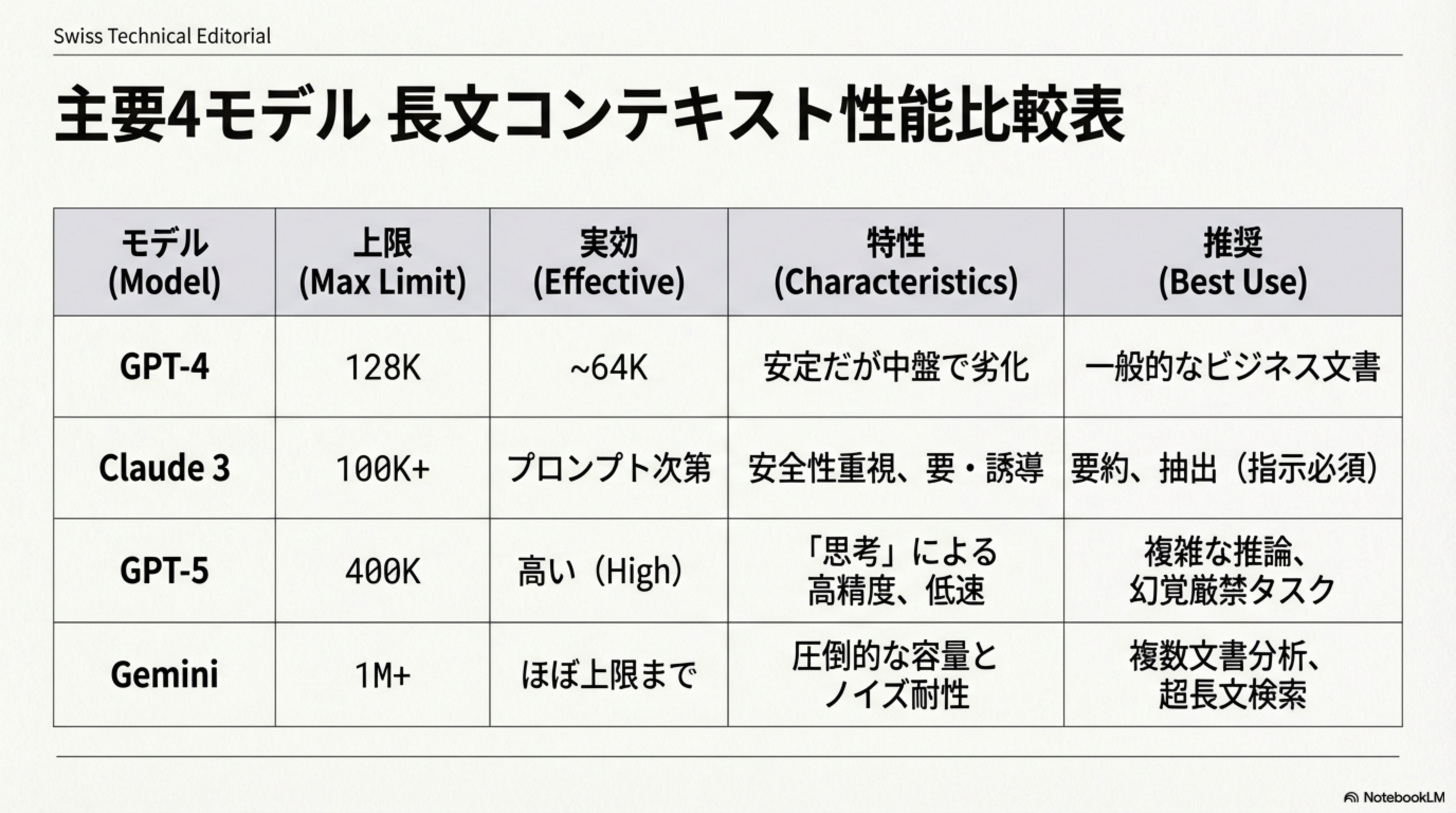
6. 主要4モデル:長文コンテキスト性能比較表
| モデル | 上限 (Max Limit) | 実効 (Effective) | 特性 | 推奨用途 |
|---|---|---|---|---|
| GPT-4 | 128K | 〜64K | 安定だが中盤で劣化 | 一般的なビジネス文書 |
| Claude 3 | 100K+ | プロンプト次第 | 安全性重視、要・誘導 | 要約、抽出(指示必須) |
| GPT-5 | 400K | 高い(High) | 「思考」による高精度、低速 | 複雑な推論、幻覚厳禁タスク |
| Gemini | 1M+ | ほぼ上限まで | 圧倒的な容量とノイズ耐性 | 複数文書分析、超長文検索 |
モデル選択のポイントは「トークン上限の数字」ではなく、タスクの性質で決めることです:
- 短〜中程度の文書(〜64K)→ GPT-4で十分
- 安全性が重要な抽出タスク → Claude(適切なプロンプト設計が前提)
- 複雑な推論が必要 → GPT-5のThinking Mode
- 大量の文書を一括処理 → Gemini Pro
7. 技術戦略:精度の劣化を防ぐ3つの実装アプローチ
モデルが進化しても、プロンプトエンジニアリングの重要性は変わりません。以下の3つの戦略を組み合わせることで、長文処理の精度を最大化できます。
戦略1:重要情報の配置
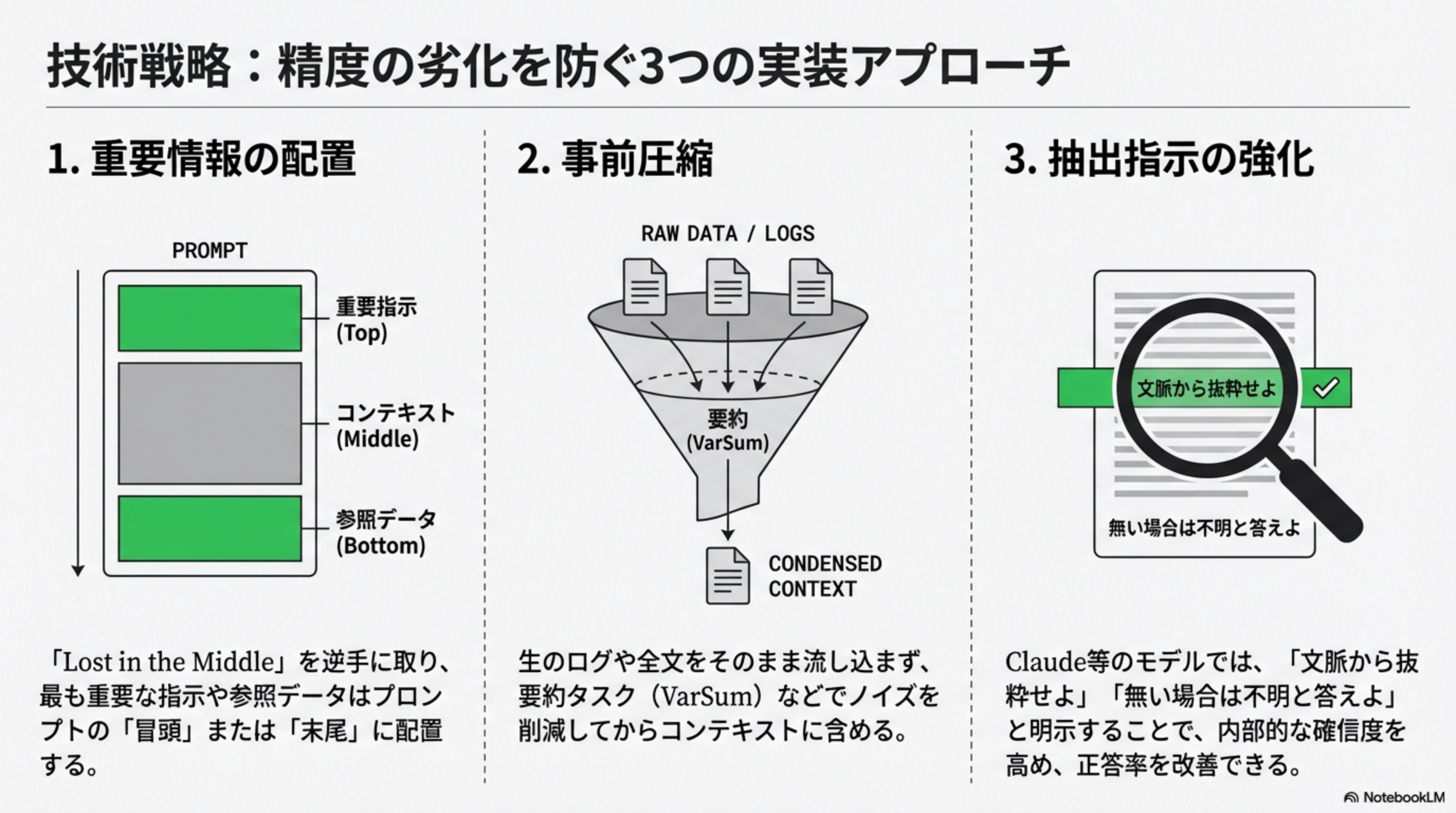
最も重要な指示や参照データは、プロンプトの「冒頭」または「末尾」に配置しましょう。モデルの注意が集中しやすい位置に重要情報を置くことが鍵です。
戦略2:事前圧縮
生のログや全文をそのまま流し込まず、要約タスク(VarSumなど)でノイズを削減してからコンテキストに含めます。
10万行のログファイルを分析する場合:
- まず第1段階のLLM呼び出しでログを要約(10万行 → 500行のサマリー)
- 要約されたサマリーを第2段階のLLM呼び出しに渡して分析
この2段階パイプラインにより、精度を維持しながらトークン消費を大幅に削減できます。
戦略3:抽出指示の強化
Claude等のモデルでは、「文脈から抜粋せよ」「無い場合は不明と答えよ」と明示することで、内部的な確信度を高め、正答率を改善できます。
これら3つの戦略は独立ではなく、組み合わせて使うことで最大の効果を発揮します:
- 事前圧縮でノイズを削減 →
- 重要情報を冒頭/末尾に配置 →
- 抽出指示を強化して確信度を高める
8. 結論:サイズ競争から「活用」の時代へ
2024年以降、コンテキストウィンドウの「サイズ」自体はコモディティ化しました。これからの勝負は、Geminiのような「動的メモリ管理」や、GPT-5のような「推論による文脈整理」といった、膨大な情報をどう処理するかというアルゴリズムの質に移行しています。
開発者は、単にトークン上限を見るのではなく、タスクの性質(推論の深さ vs ノイズ耐性)に応じてモデルを使い分け、適切な構造化データを与える設計者(Architect)になる必要がある。
やるべきこと
- タスクに応じたモデル選定
- 重要情報の戦略的配置
- 事前圧縮パイプラインの構築
- 抽出指示の明示化
やってはいけないこと
- トークン上限の数字だけでモデルを選ぶ
- 生データをそのまま流し込む
- 軽量モデルに大量文書を処理させる
- 曖昧なプロンプトで長文タスクを実行する
LLMの基礎理論を学んだら、次はこれらの知識を実際のAIエージェント設計にどう活かすかを見ていきましょう。
元のスライド一覧
クリックで拡大表示できます