はじめに:「答えるAI」から「行動するAI」へ
ChatGPTなどのLLM(大規模言語モデル)は、質問に答えることが得意です。しかし、私たちが本当に求めているのは「質問に答える」だけではなく、「自分で考え、道具を使い、タスクを完了する」AIではないでしょうか?
この章では、LLMを単なるテキスト生成器から自律的なソフトウェア実行エンジンへと進化させる「エージェント・アーキテクチャ」の全貌を学びます。
- エージェントを構成する3つの要素(LLM + ループ + ツール)
- ReActフレームワークの仕組み
- Planning Engine(計画エンジン)の役割
- マルチエージェントの2つのトポロジー(Hub-and-Spoke vs Mesh)
- 設計で避けるべきアンチパターンと修復戦術
1. エージェントを定義する中核方程式
AIエージェントとは何でしょうか?実は、モデルの「賢さ」のことではありません。エージェントとは、LLMに自律性を与える「周辺アーキテクチャ」の設計を指します。
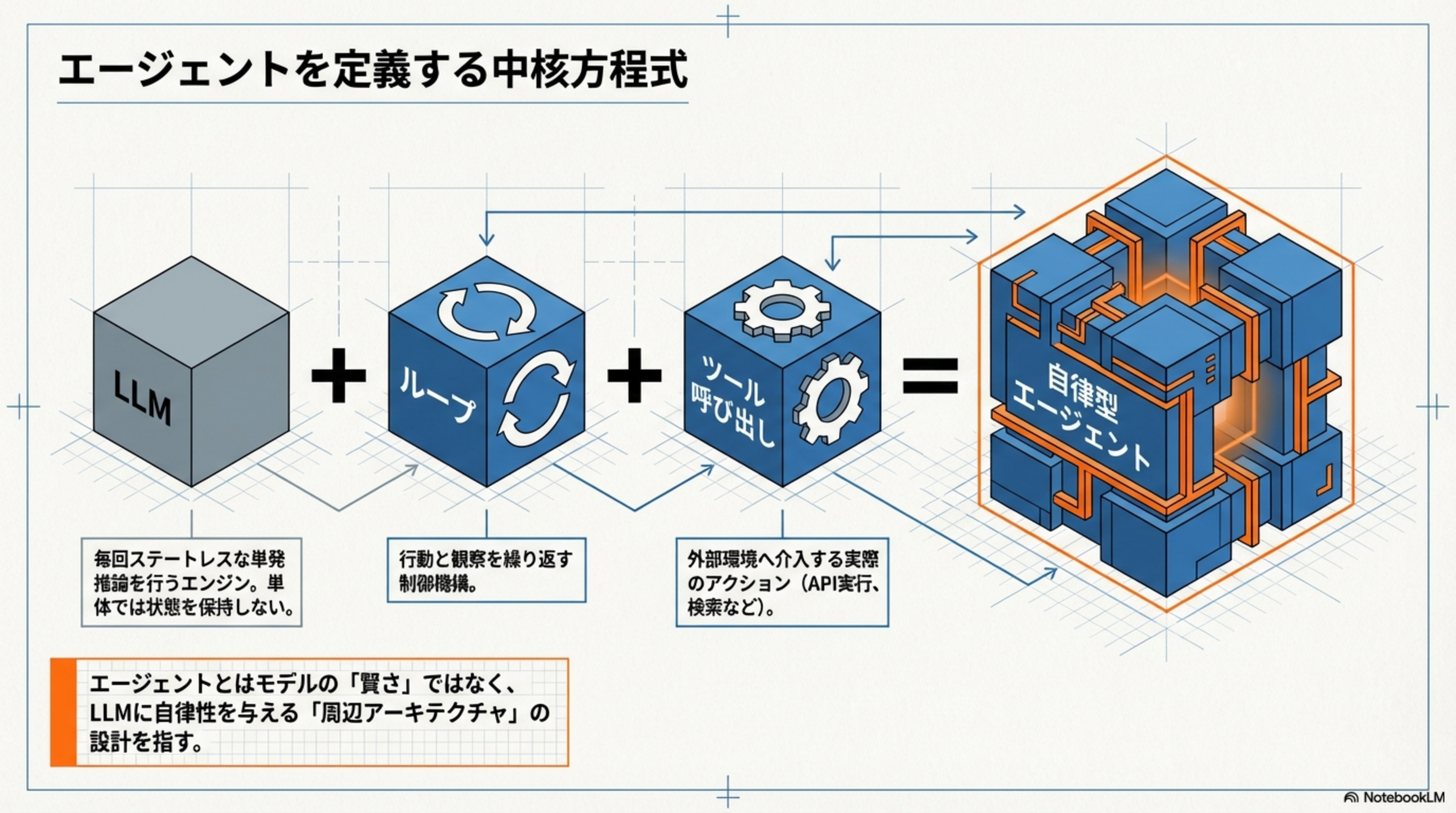
この方程式を、日常生活に例えてみましょう。
- LLM単体 = レシピの知識はあるが、手が動かないシェフ。「カレーの作り方は?」と聞けば答えるが、実際には作らない
- LLM + ループ = 調理工程を1ステップずつ確認しながら進められる。「次は何をする?」を繰り返す
- LLM + ループ + ツール = 包丁(ファイル編集)、鍋(API実行)、味見(テスト実行)を自分で使って、実際にカレーを完成させる
3つの構成要素を詳しく見る
| 構成要素 | 役割 | 具体例 |
|---|---|---|
| LLM(頭脳) | 毎回ステートレスな単発推論を行うエンジン。単体では状態を保持しない | Claude、GPT-4、Gemini など |
| ループ(制御機構) | 行動と観察を繰り返す制御機構。「考える→実行する→結果を見る」のサイクルを回す | while文、ReActループ |
| ツール呼び出し(手足) | 外部環境へ介入する実際のアクション(API実行、検索など) | ファイル読み書き、Web検索、DB操作、コード実行 |
エージェントとはモデルの「賢さ」ではなく、LLMに自律性を与える「周辺アーキテクチャ」の設計を指します。どんなに賢いLLMでも、ループとツールがなければ「聞かれたことに答えるだけ」のチャットボットに留まります。
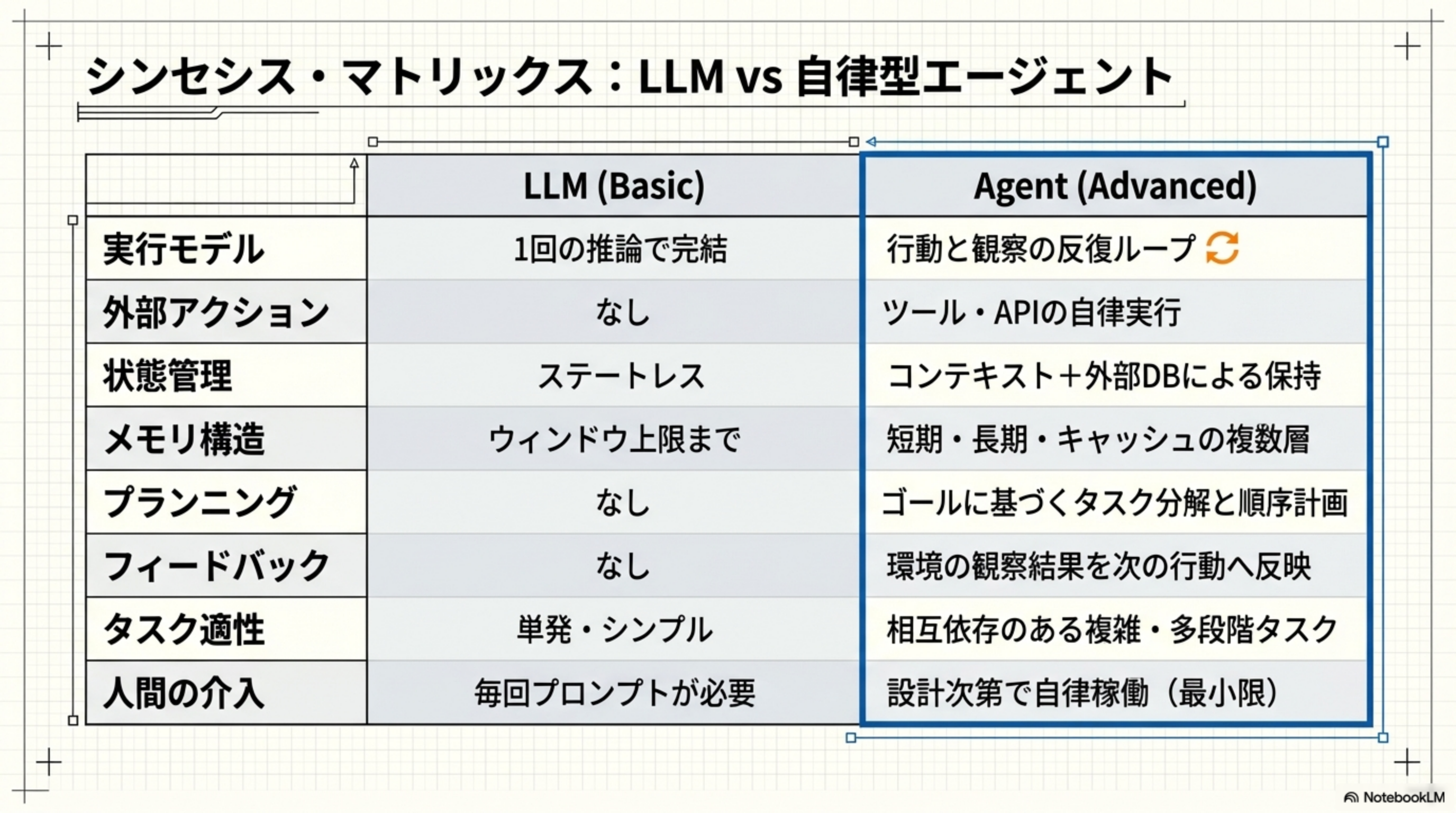
2. LLM(Basic)vs 自律型エージェント(Advanced)
素のLLMとエージェントの違いを、8つの観点から比較してみましょう。この表を見れば、エージェント化によって何が変わるのかが一目瞭然です。
| 比較項目 | LLM(Basic) | Agent(Advanced) |
|---|---|---|
| 実行モデル | 1回の推論で完結 | 行動と観察の反復ループ |
| 外部アクション | なし | ツール・APIの自律実行 |
| 状態管理 | ステートレス | コンテキスト+外部DBによる保持 |
| メモリ構造 | ウィンドウ上限まで | 短期・長期・キャッシュの複数層 |
| プランニング | なし | ゴールに基づくタスク分解と順序計画 |
| フィードバック | なし | 環境の観察結果を次の行動へ反映 |
| タスク適性 | 単発・シンプル | 相互依存のある複雑・多段階タスク |
| 人間の介入 | 毎回プロンプトが必要 | 設計次第で自律稼働(最小限) |
エージェントは「すべてを自動化する魔法」ではなく、適切な設計によってLLMの能力を拡張する仕組みです。単純な質問応答にはLLM単体で十分。複雑な多段階タスクにこそエージェントの真価が発揮されます。
3. 推論パラダイムの進化とReActフレームワーク
エージェントの「考え方」は、LLMの進化とともに3段階で発展してきました。この進化を理解することで、なぜReActが現在のエージェント設計の主流なのかが分かります。
3つの推論パラダイム
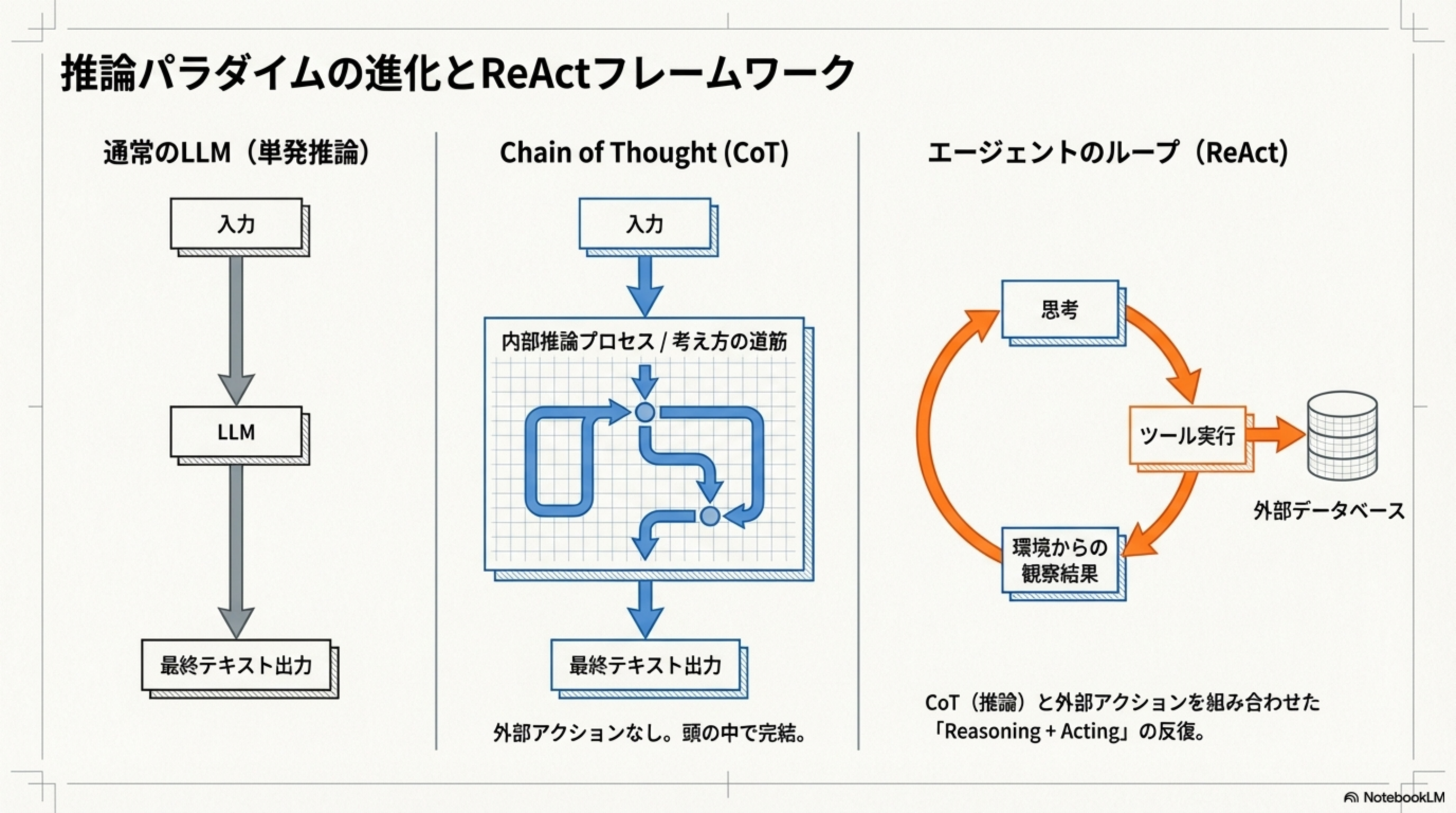
| パラダイム | 特徴 | 限界 |
|---|---|---|
| 単発推論 | 入力→LLM→出力。1回で完結 | 複雑な問題には対応できない |
| Chain of Thought (CoT) | 「考え方の道筋」を内部で展開してから回答 | 外部アクションなし。頭の中で完結するため、現実世界のデータ取得や操作ができない |
| ReAct | CoT(推論)と外部アクションを組み合わせた「Reasoning + Acting」の反復 | 設計が複雑になるが、最も実用的 |
ReActループの具体例
- 思考(Thought):「まず明日の東京の天気を調べる必要がある」
- 行動(Action):天気APIを呼び出して、明日の東京の天気データを取得
- 観察(Observation):「最高気温22度、午後から雨、湿度70%」という結果を受け取る
- 思考(Thought):「午後から雨なので折りたたみ傘が必要。気温は暖かめなので薄手の上着で十分」
- 行動(Action):ユーザーに最終的な服装提案を出力
ReAct = Reasoning(推論) + Acting(行動)。考えるだけでなく、考えた結果に基づいて行動し、その結果をまた考慮に入れる。この「思考→行動→観察」のサイクルこそが、エージェントの核心です。
4. エージェントメモリの解剖学
エージェントが「賢く」動き続けるためには、情報をどこに保存し、どう取り出すかが重要です。人間の脳と同じように、エージェントにも短期記憶と長期記憶があります。
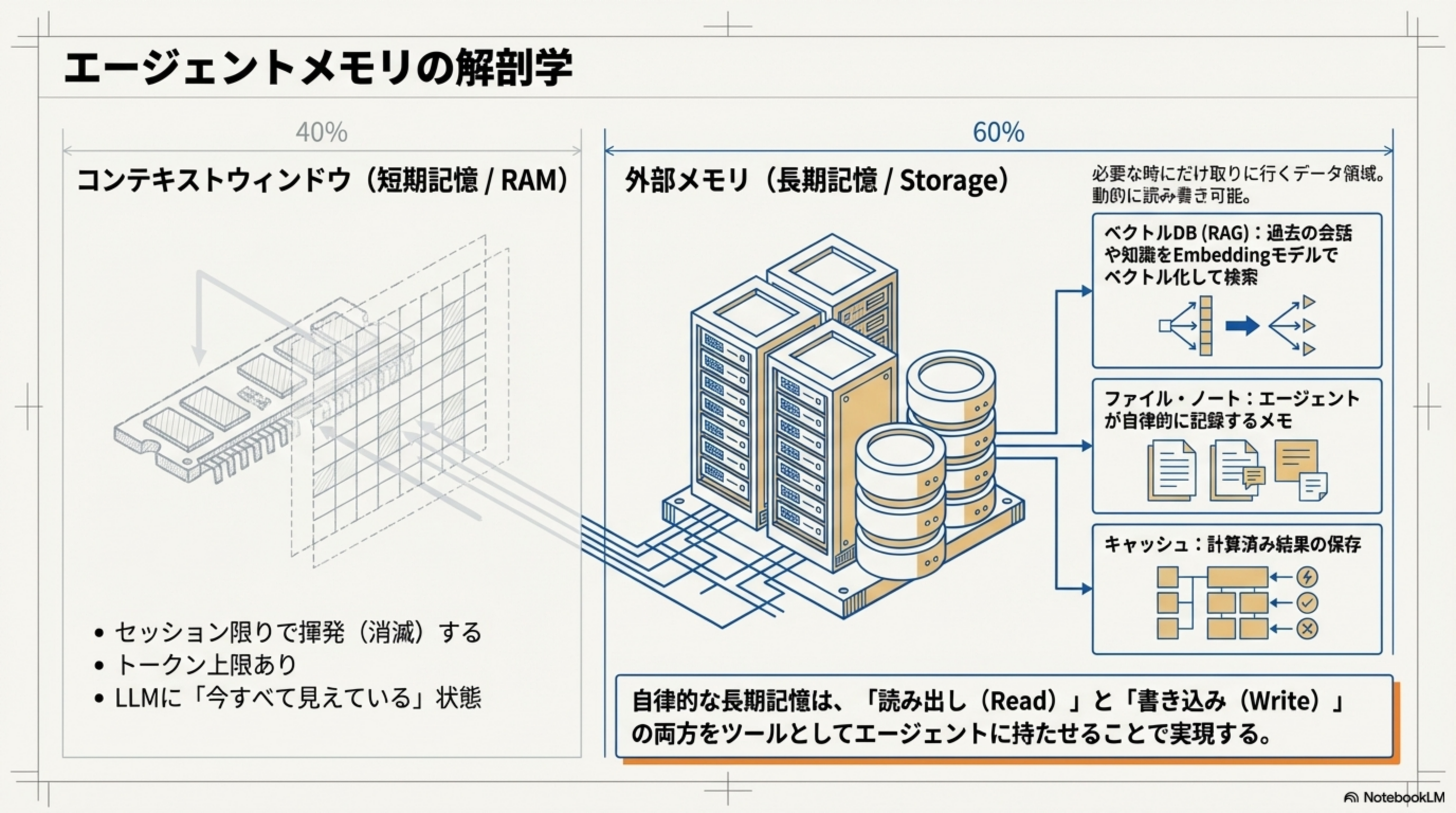
- 短期記憶(コンテキストウィンドウ) = 作業机の上。今まさに見ている書類。机の広さ(トークン上限)には限りがあり、作業が終われば片付けられる
- 長期記憶(外部メモリ) = 隣の部屋にある書庫。必要な時にだけ取りに行く。容量は事実上無制限。必要な時にだけ取り出す
自律的な長期記憶は、「読み出し(Read)」と「書き込み(Write)」の両方をツールとしてエージェントに持たせることで実現します。エージェントが自分で「これは重要だから保存しよう」と判断してメモを書き、後で必要な時に読み出す。これが外部メモリの核心です。
5. エグゼクティブ・ブレインとしてのPlanning Engine
エージェントが複雑なタスクをこなすには、いきなりReActループを回すだけでは不十分です。まず「何をどの順番でやるか」の計画が必要になります。これを担うのがPlanning Engine(計画エンジン)です。
「来週の京都旅行を計画して」と頼まれた場合、いきなり新幹線を予約しません。まず「目的は何か?予算は?何日間?」を整理し、それから行動計画を立てますよね。Planning Engineはまさにこの「計画フェーズ」を担当します。
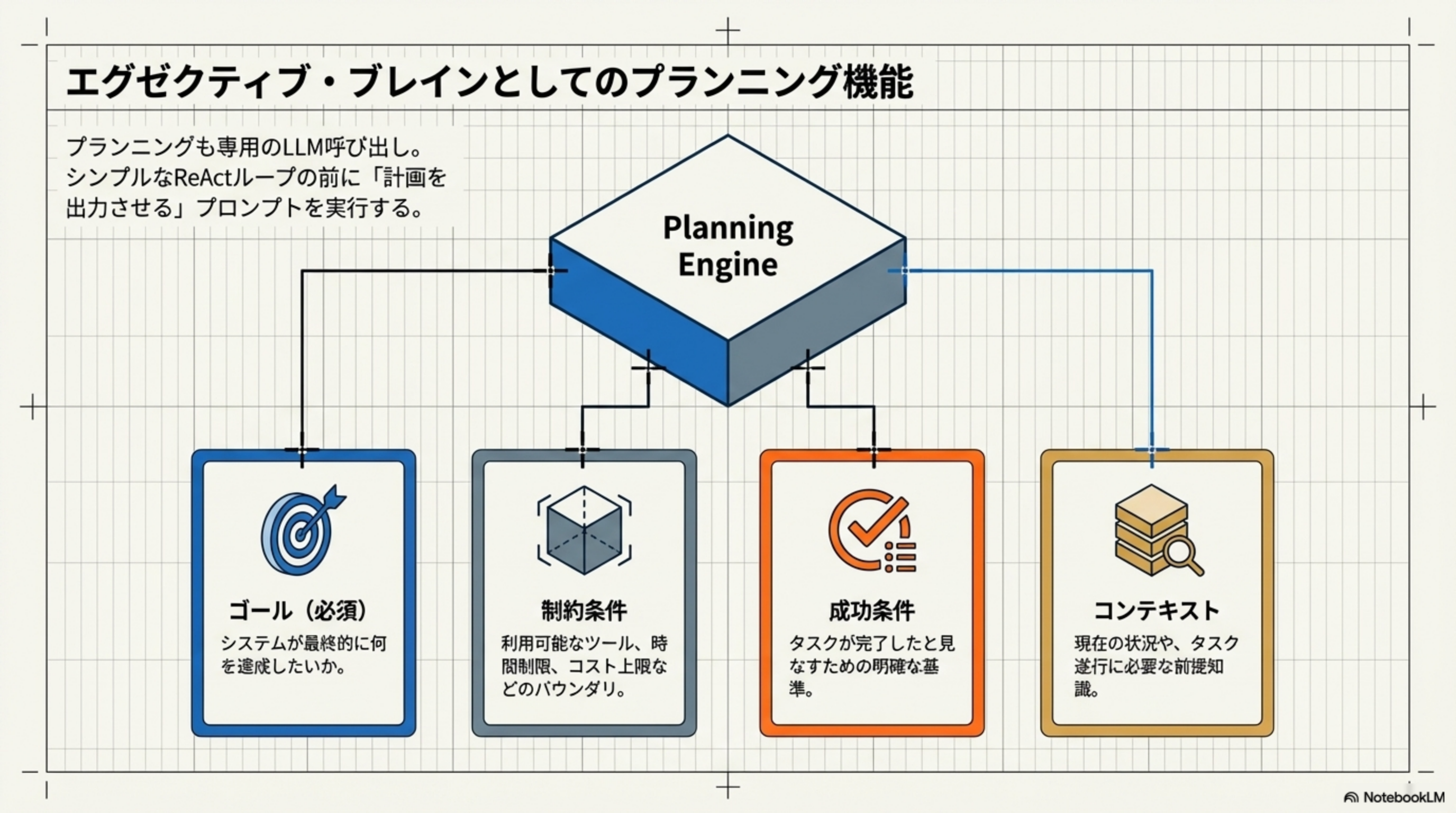
Planning Engineの4つの入力
| 入力 | 説明 | 具体例 |
|---|---|---|
| ゴール(必須) | システムが最終的に何を達成したいか | 「ユーザー認証機能を実装する」 |
| 制約条件 | 利用可能なツール、時間制限、コスト上限などのバウンダリ | 「Pythonのみ使用」「30分以内」 |
| 成功条件 | タスクが完了したと見なすための明確な基準 | 「全テストがパスする」 |
| コンテキスト | 現在の状況や、タスク遂行に必要な前提知識 | 「既存のDBスキーマ」「API仕様」 |
プランニングも専用のLLM呼び出しとして実現されます。シンプルなReActループの前に「計画を出力させる」プロンプトを実行する。つまり「まず計画を立てて、それからReActで実行する」という2段階構成です。
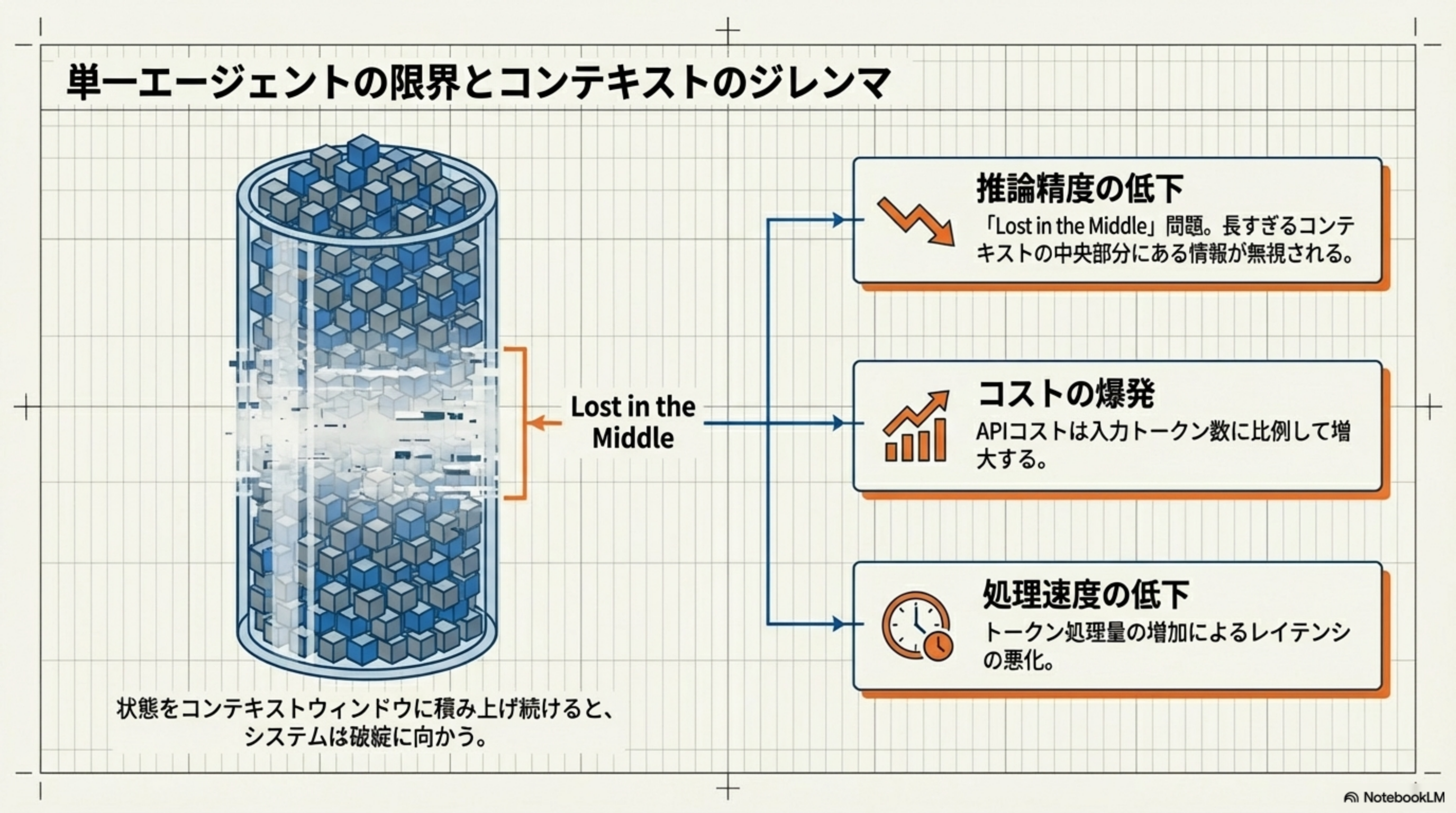
6. 単一エージェントの限界とコンテキストのジレンマ
1つのエージェントに全てを任せると、どうなるでしょうか?コンテキストウィンドウに状態を積み上げ続けると、3つの深刻な問題が発生します。
推論精度の低下
Lost in the Middle問題。長すぎるコンテキストの中央部分にある情報が無視される。LLMは文章の「最初」と「最後」を重視し、中間の情報を見落としやすい傾向があります。
コストの爆発
APIコストは入力トークン数に比例して増大します。会話が長くなればなるほど、毎回のAPI呼び出しで大量のトークンを送信することになり、コストが雪だるま式に膨らみます。
処理速度の低下
トークン処理量の増加によるレイテンシの悪化。コンテキストが大きくなるほど、LLMの応答時間が長くなり、ユーザー体験が悪化します。
根本的なジレンマ
状態をコンテキストウィンドウに積み上げ続けると、システムは破綻に向かう。これは単にウィンドウサイズを広げれば解決する問題ではありません。
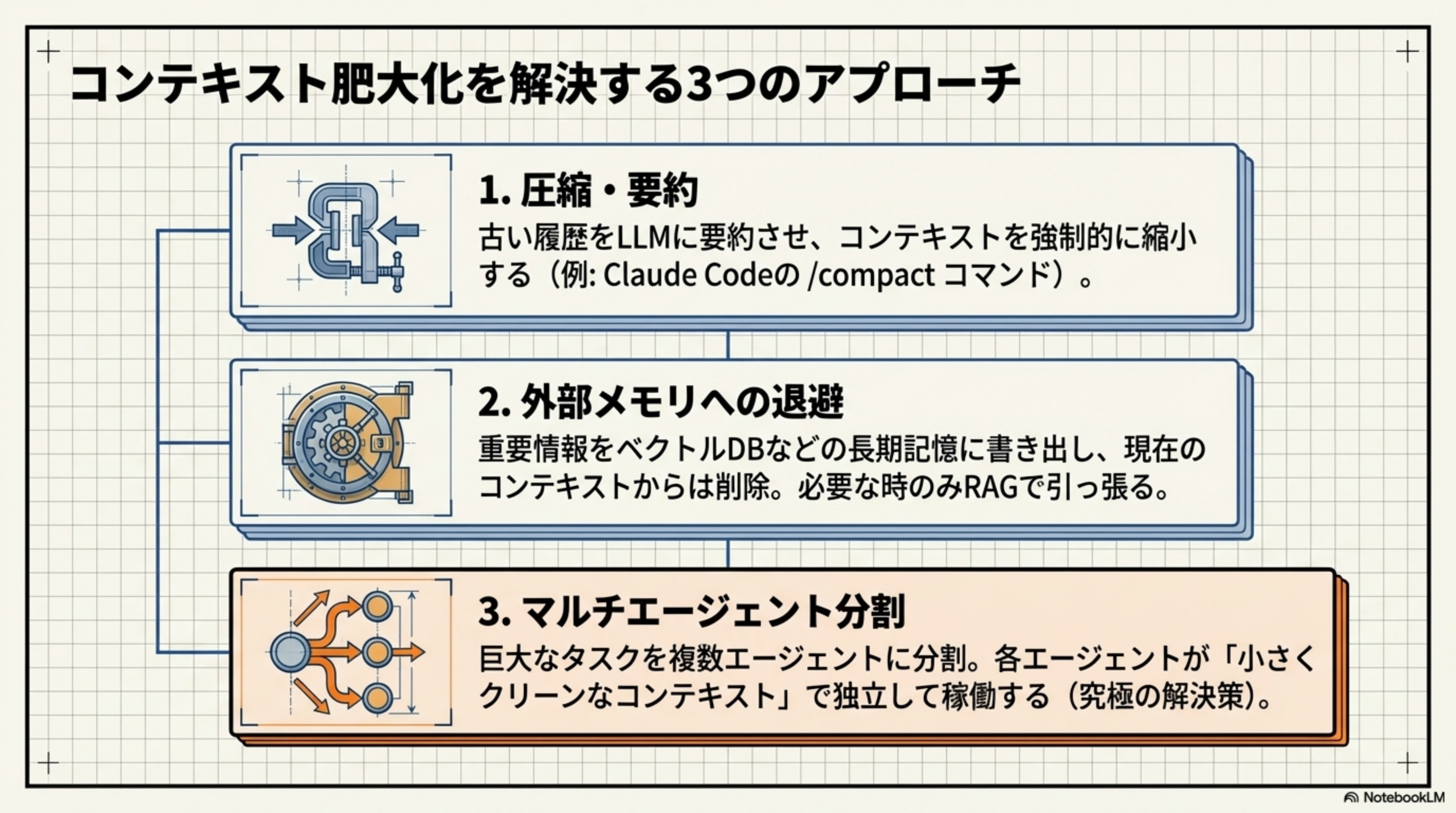
コンテキスト肥大化を解決する3つのアプローチ
- 圧縮・要約:古い履歴をLLMに要約させ、コンテキストを強制的に縮小する(例:Claude Codeの
/compactコマンド) - 外部メモリへの退避:重要情報をベクトルDBなどの長期記憶に書き出し、現在のコンテキストからは削除。必要な時のみRAGで引っ張る
- マルチエージェント分割(究極の解決策):巨大なタスクを複数エージェントに分割。各エージェントが「小さくクリーンなコンテキスト」で独立して稼働する
圧縮や外部メモリは「1つのエージェント内での対処療法」です。根本的に、1つのエージェントには処理できるコンテキストの上限があります。マルチエージェント分割は、この上限自体を「複数の小さな枠に分散する」ことで突破します。
7. ネットワークトポロジー:Hub-and-Spoke vs Mesh
複数のエージェントを協調させる場合、その「つなぎ方」(トポロジー)が重要になります。代表的な2つの設計パターンを比較しましょう。
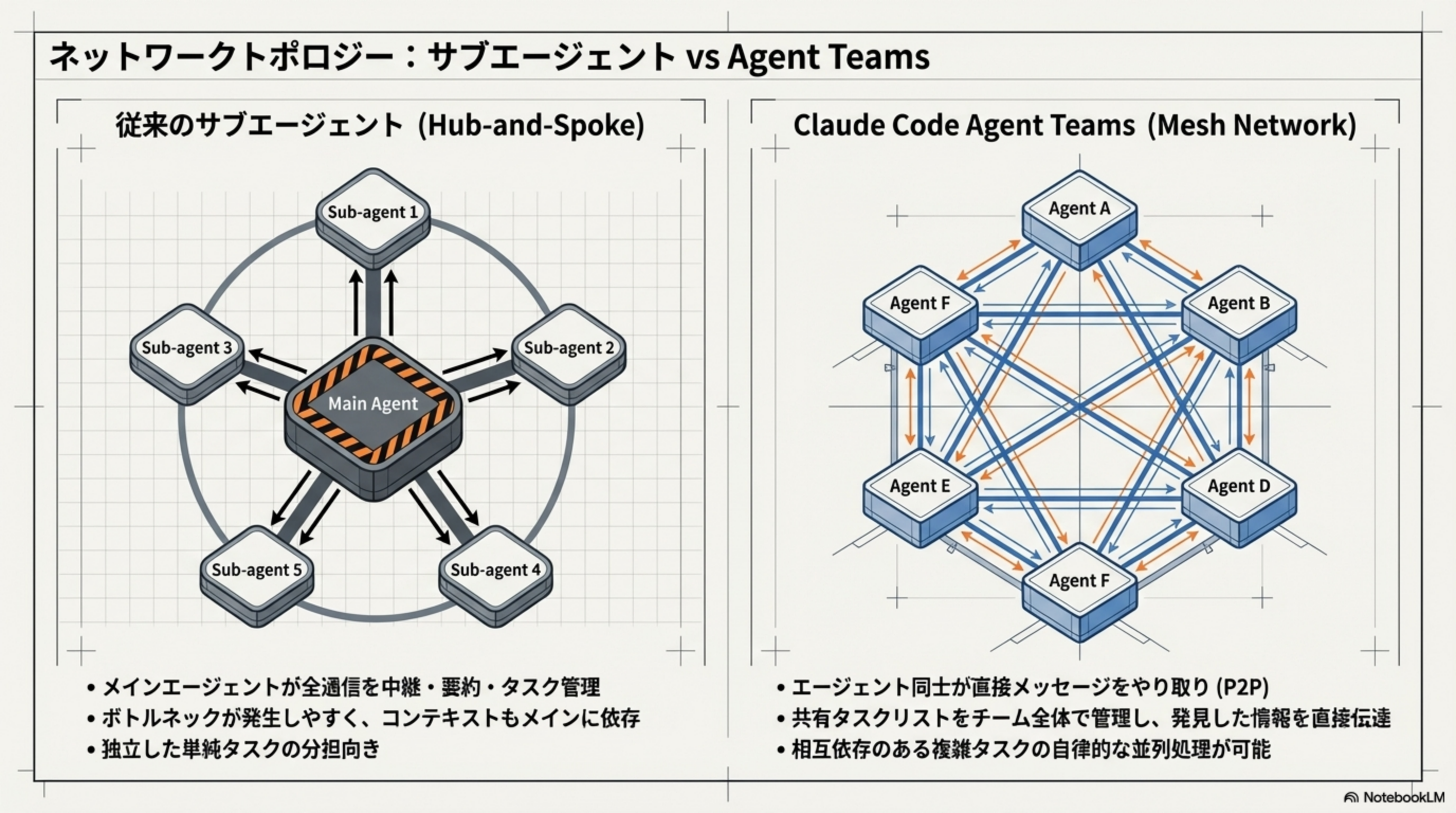
| 特性 | Hub-and-Spoke | Mesh(Agent Teams) |
|---|---|---|
| 通信方式 | メインを経由 | エージェント間で直接(P2P) |
| ボトルネック | メインに集中しやすい | 分散されるため発生しにくい |
| コンテキスト | メインが全体を保持 | 各エージェントが独立して保持 |
| 適したタスク | 独立した単純タスクの分担 | 相互依存のある複雑タスクの並列処理 |
| スケーラビリティ | メインの処理能力に制約される | エージェント追加で水平スケール可能 |
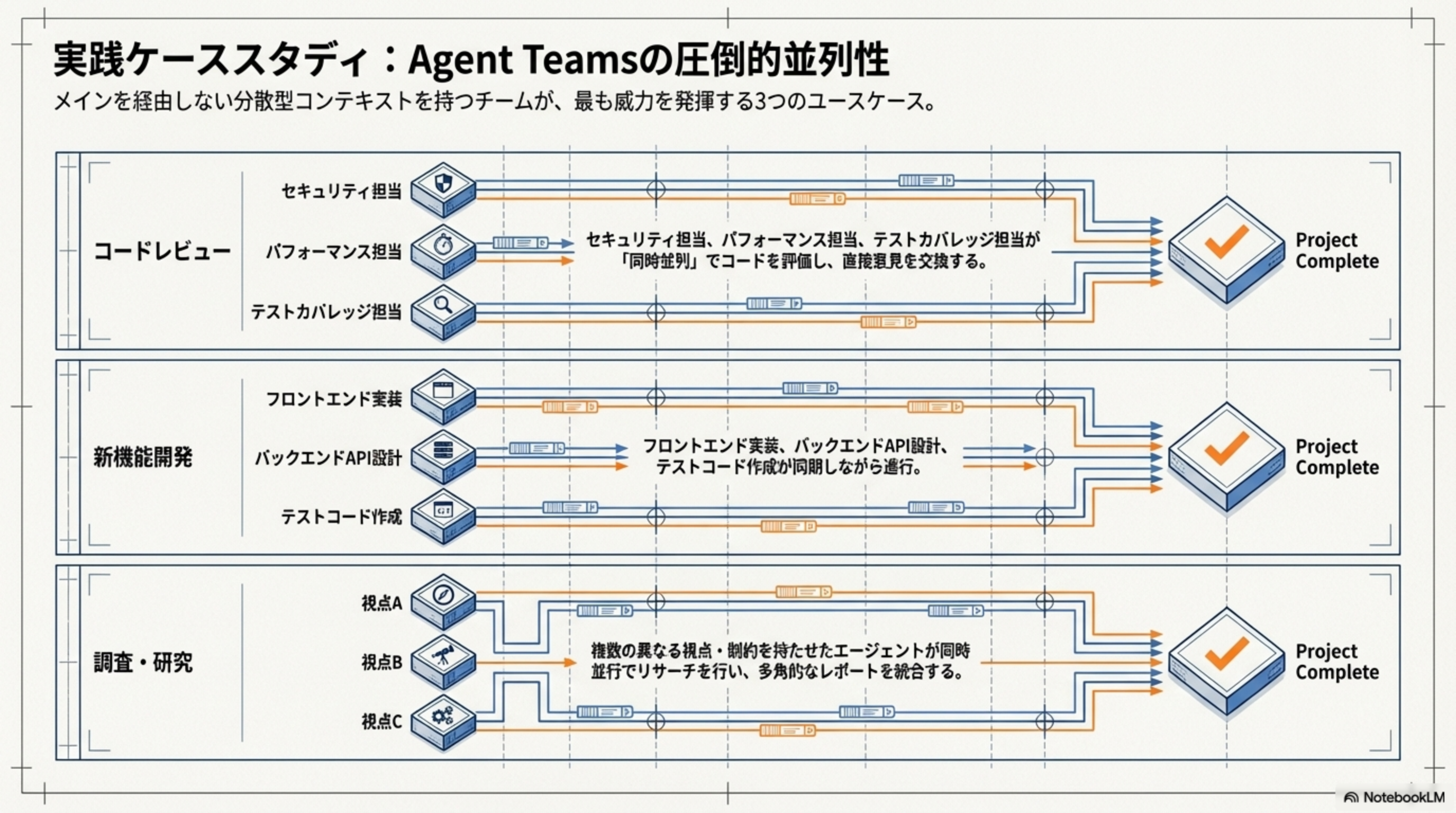
Agent Teamsが威力を発揮する3つのユースケース
セキュリティ担当、パフォーマンス担当、テストカバレッジ担当が「同時並列」でコードを評価し、直接意見を交換する。メインを介さないため高速。
フロントエンド実装、バックエンドAPI設計、テストコード作成が同期しながら進行。互いの進捗を直接確認できるため、手戻りが少ない。
複数の異なる視点・制約を持たせたエージェントが同時並行でリサーチを行い、多角的なレポートを統合する。
8. スケーリングの論理:タスク分割の判断基準
「いつマルチエージェントにすべきか?」これは重要な設計判断です。以下の3つの質問に「Yes」と答えられたら、タスクを分割する合図です。
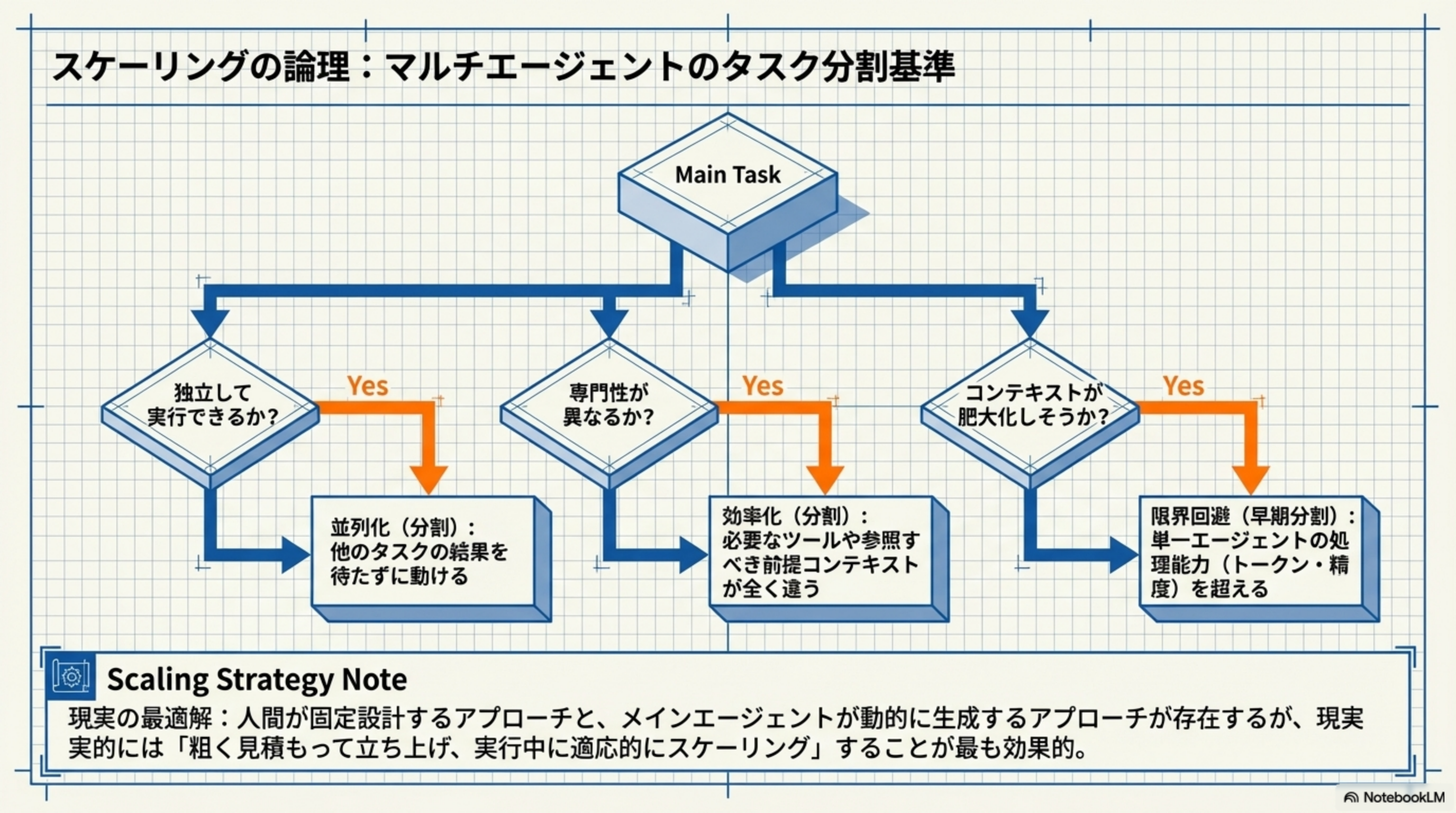
現実の最適解:人間が固定設計するアプローチと、メインエージェントが動的に生成するアプローチが存在しますが、現実的には「粗く見積もって立ち上げ、実行中に適応的にスケーリングする」ことが最も効果的です。
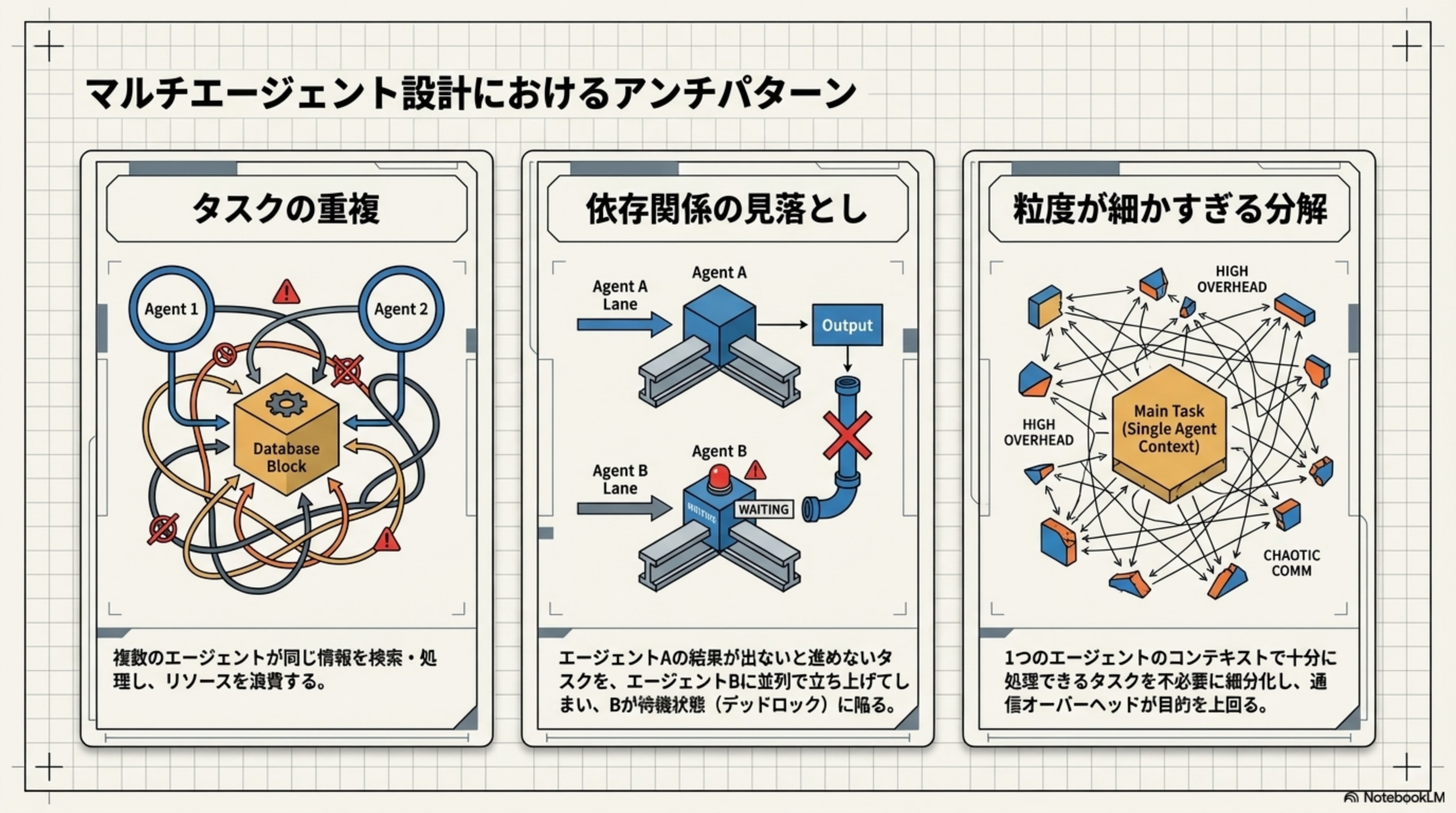
9. マルチエージェント設計のアンチパターン
マルチエージェントは強力ですが、設計を間違えると逆効果になります。よくある3つの失敗パターンを知っておきましょう。
アンチパターン1:タスクの重複
複数のエージェントが同じ情報を検索・処理し、リソースを浪費する。例えば、Agent 1とAgent 2が同じデータベースに同じクエリを投げてしまう状態。
アンチパターン2:依存関係の見落とし
エージェントAの結果が出ないと進めないタスクを、エージェントBに並列で立ち上げてしまい、Bが待機状態(デッドロック)に陥る。
1つのエージェントのコンテキストで十分に処理できるタスクを不必要に細分化し、通信オーバーヘッドが目的を上回る。小さなタスクをバラバラにしすぎると、エージェント間の連絡コストの方が、実際の作業よりも大きくなってしまいます。
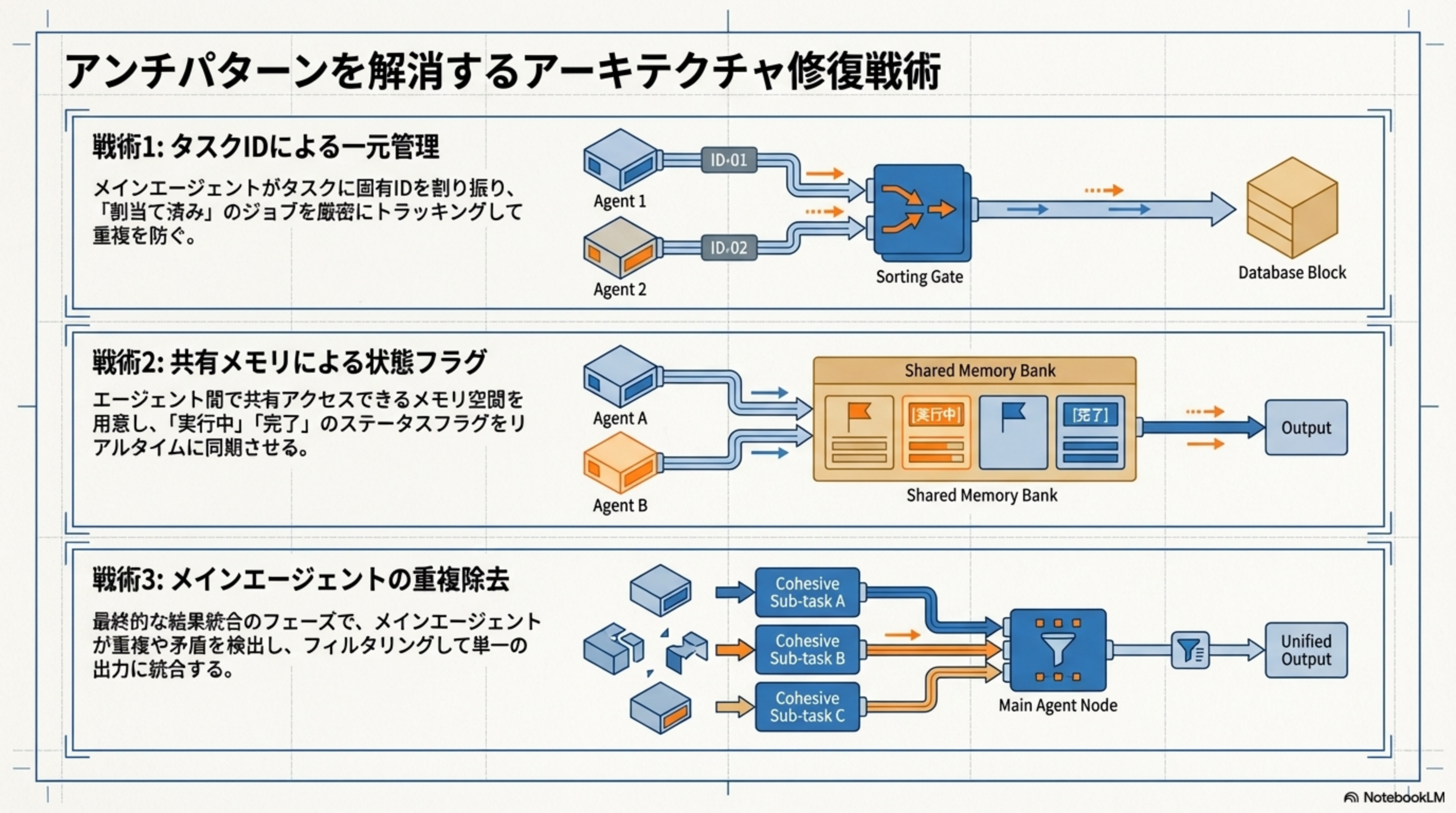
アンチパターンを解消するアーキテクチャ修復戦術
| 戦術 | 対策内容 | 仕組み |
|---|---|---|
| 戦術1:タスクIDによる一元管理 | メインエージェントがタスクに固有IDを割り振り、「割当て済み」のジョブを厳密にトラッキングして重複を防ぐ | Sorting Gateでタスクを振り分け、DBで管理 |
| 戦術2:共有メモリによる状態フラグ | エージェント間で共有アクセスできるメモリ空間を用意し、「実行中」「完了」のステータスフラグをリアルタイムに同期させる | Shared Memory Bankを介したステータス管理 |
| 戦術3:メインエージェントの重複除去 | 最終的な結果統合のフェーズで、メインエージェントが重複や矛盾を検出し、フィルタリングして単一の出力に統合する | Main Agent Nodeがファンネル(漏斗)として機能 |
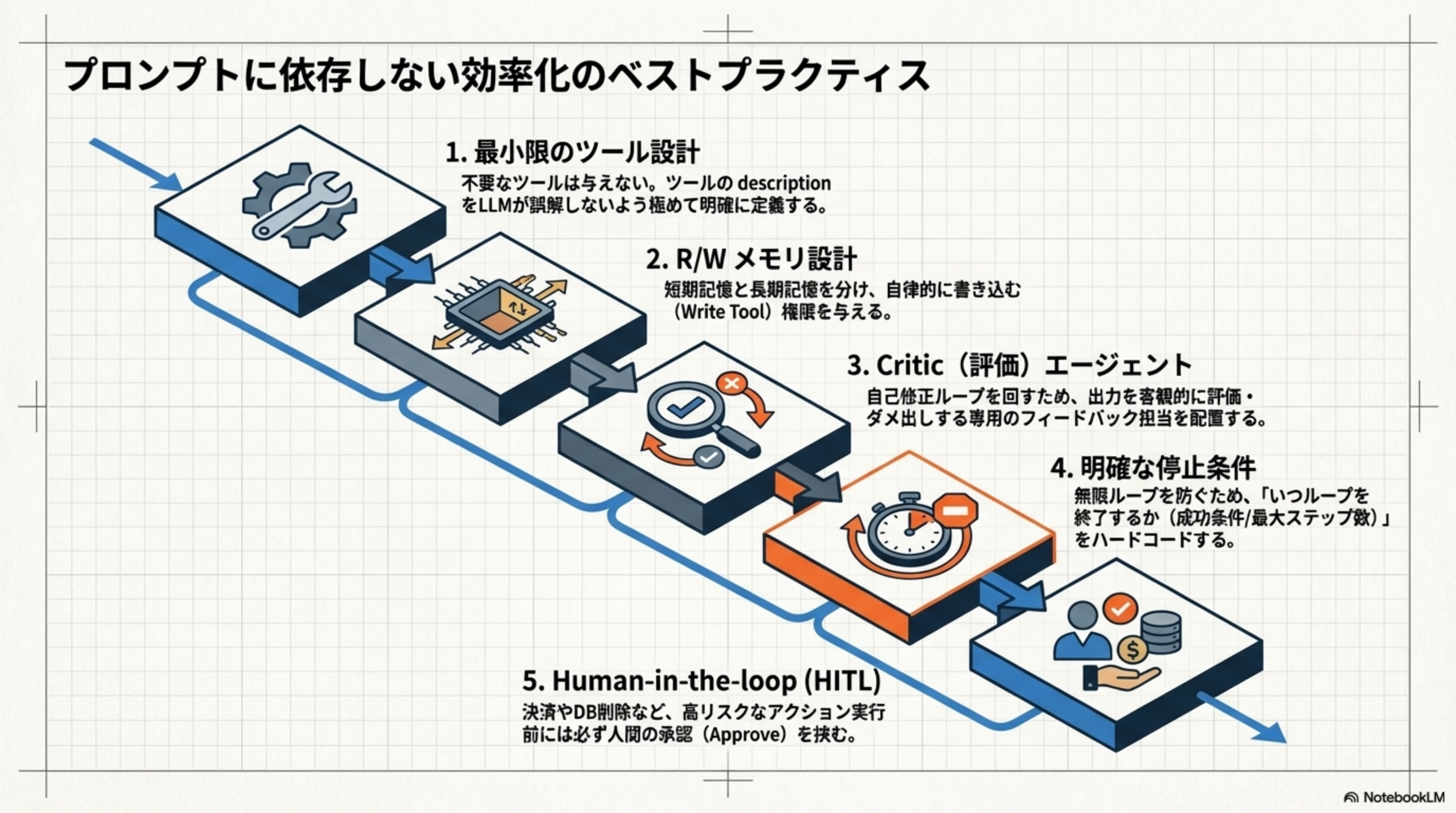
10. プロンプトに依存しない効率化のベストプラクティス
エージェントの品質を高めるには、プロンプトの工夫だけでは限界があります。アーキテクチャレベルでの5つのベストプラクティスを実践しましょう。
-
最小限のツール設計
不要なツールは与えない。ツールの description をLLMが誤解しないよう極めて明確に定義する。ツールが多すぎると、LLMが「どのツールを使うべきか」の判断に迷い、精度が落ちます。 -
R/W メモリ設計
短期記憶と長期記憶を分け、自律的に書き込む(Write Tool)権限を与える。エージェントが自分で「これは後で使うから保存しておこう」と判断できるようにします。 -
Critic(評価)エージェント
自己修正ループを回すため、出力を客観的に評価・ダメ出しする専用のフィードバック担当を配置する。「自分の仕事を自分でチェック」させるのではなく、別のエージェントがチェックする。 -
明確な停止条件
無限ループを防ぐため、「いつループを終了するか(成功条件/最大ステップ数)」をハードコードする。「もう十分」をLLMの判断だけに頼らず、システム側で強制停止の仕組みを入れる。 -
Human-in-the-loop(HITL)
決済やDB削除など、高リスクなアクション実行前には必ず人間の承認(Approve)を挟む。すべてを自動化するのではなく、「ここは人間が確認する」というゲートを設ける。
これらは独立した施策ではなく、互いに補完し合います。最小限のツール → 適切なメモリ → 自己評価 → 停止制御 → 人間によるセーフガード。この多層防御の構造が、堅牢なエージェントシステムを作り上げます。
まとめ:「答えるAI」から「行動するAI」へ
エージェントアーキテクチャは、LLMを単なるテキスト生成器から、自律的なソフトウェア実行エンジンへと昇華させました。
単一エージェントのコンテキスト限界を理解し、適切なマルチエージェント・トポロジーを設計することが、次世代システム構築の鍵となります。
- エージェント = LLM + ループ + ツール。モデルの賢さではなく、周辺設計で決まる
- ReActは「思考→行動→観察」の反復で、エージェントの基本動作パターン
- Planning Engineが複雑なタスクの計画を立て、ReActが実行する2段階構成
- 単一エージェントには限界がある。マルチエージェントで突破する
- Hub-and-Spoke よりもMesh(Agent Teams)が複雑タスクに適している
- アンチパターンを知り、修復戦術で対処する
- プロンプトだけでなく、アーキテクチャレベルのベストプラクティスを実践する
設計の全貌は整った。次は、あなたのシステムへの実装へ。
元のスライド一覧
クリックで拡大表示できます