はじめに:コンテキストウィンドウだけでは「分身」は作れない
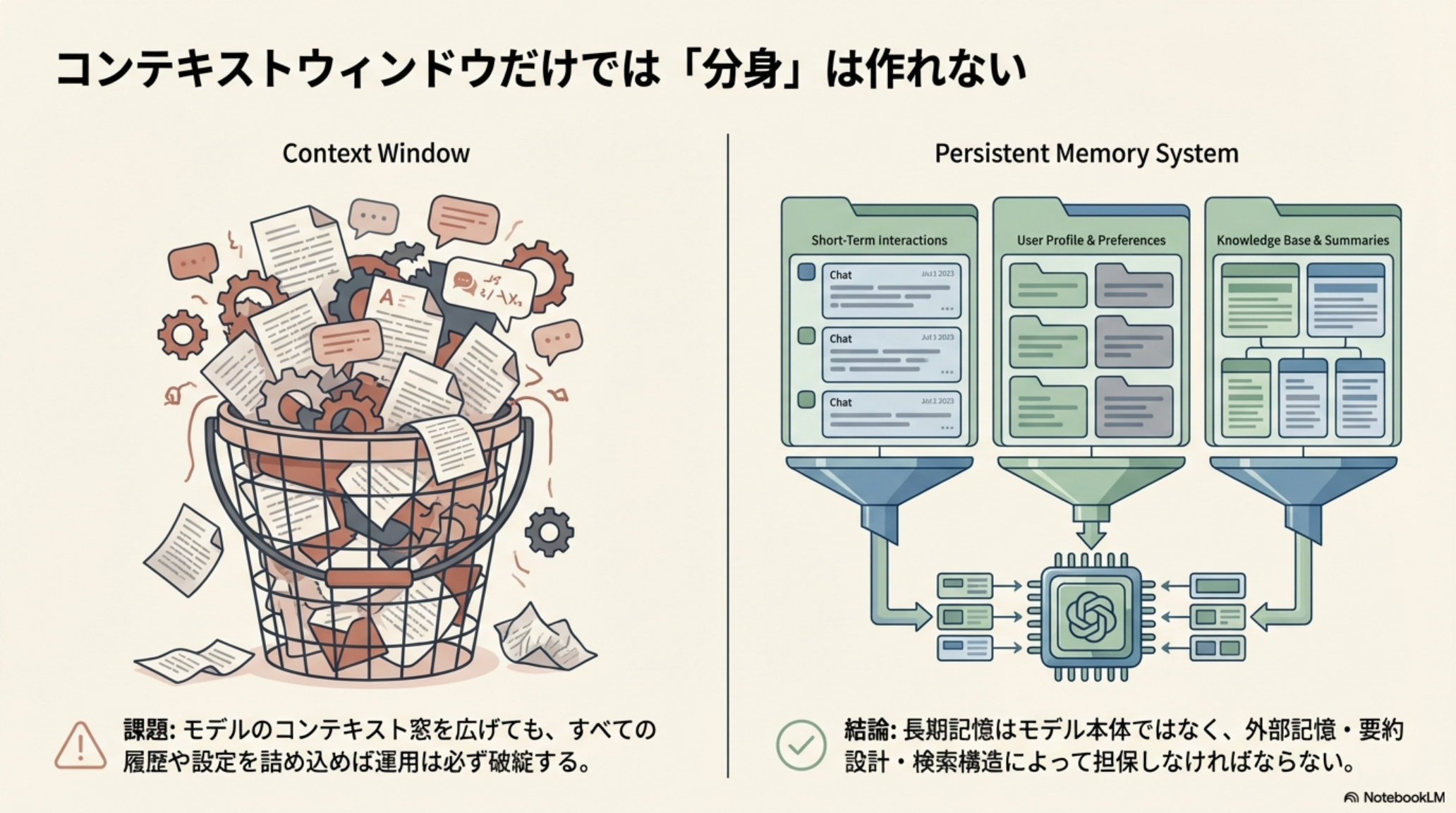
「AIに自分の好みや過去の判断を覚えてもらいたい」「毎回同じ説明をするのが面倒」 -- こうした願望は、すべてのLLMユーザーが感じるものです。しかし、モデルのコンテキスト窓を広げても、すべての履歴や設定を詰め込めば運用は必ず破綻します。
Context Window(従来のアプローチ)
すべてを1つのウィンドウに詰め込もうとする。履歴が増えると溢れ、古い情報は失われる。
課題:モデルのコンテキスト窓を広げても、すべての履歴や設定を詰め込めば運用は必ず破綻する。
Persistent Memory System(目指す形)
短期的なやり取り、ユーザープロファイル、ナレッジベースを分離して管理。必要な時に必要な情報だけを引き出す。
結論:長期記憶はモデル本体ではなく、外部記憶・要約設計・検索構造によって担保しなければならない。
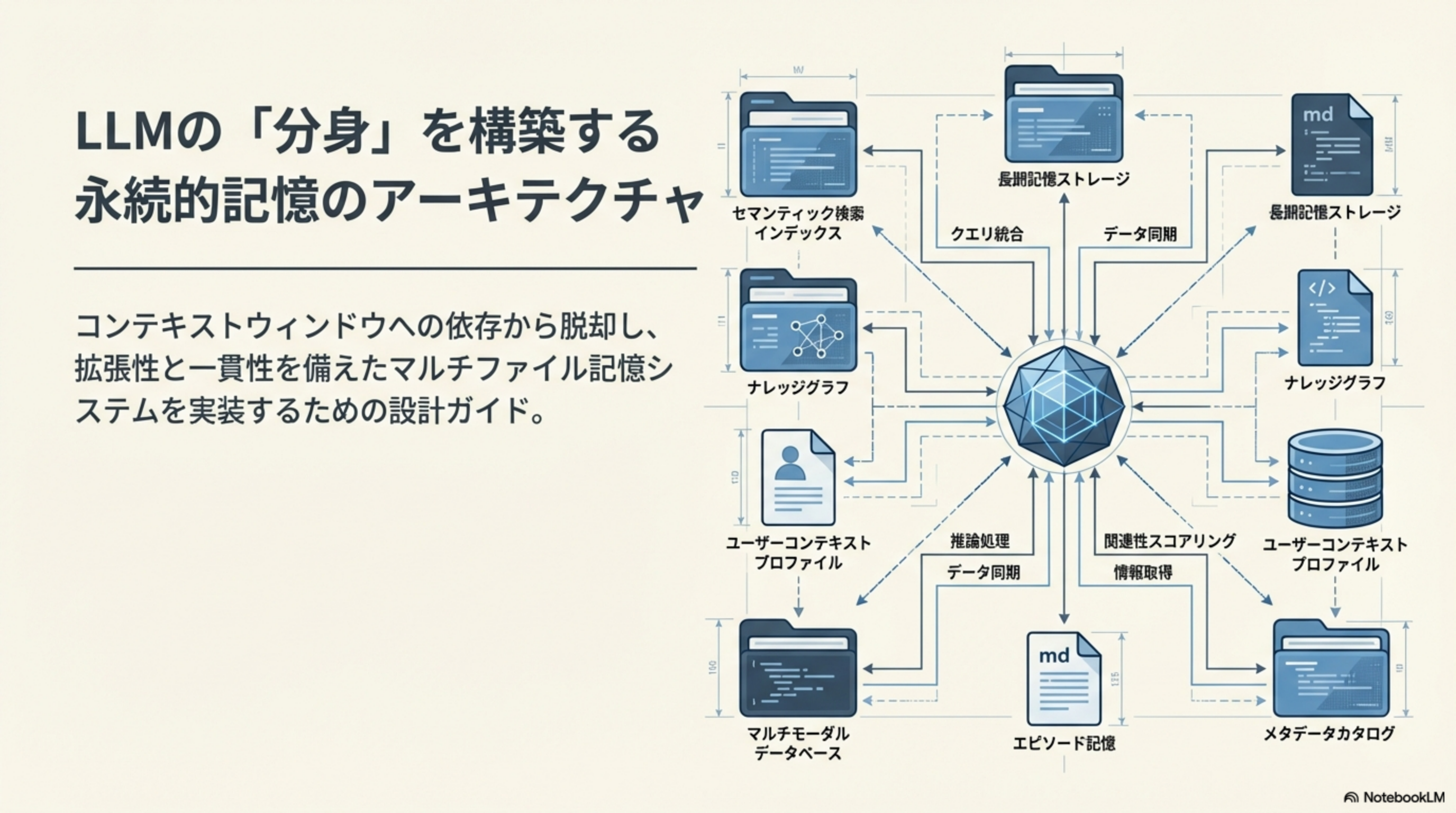
- LLMの記憶を3つの階層で設計する方法
- 巨大な1つのプロンプトから、階層化されたモジュールへの転換
- 「母艦(Mothership)」と「案件(Project)」の分離アーキテクチャ
- CLAUDE.mdをエントリポイントとして活用する方法
- コンテキスト圧迫を防ぐ運用ガイドライン
- 今日から始める5つのステップ
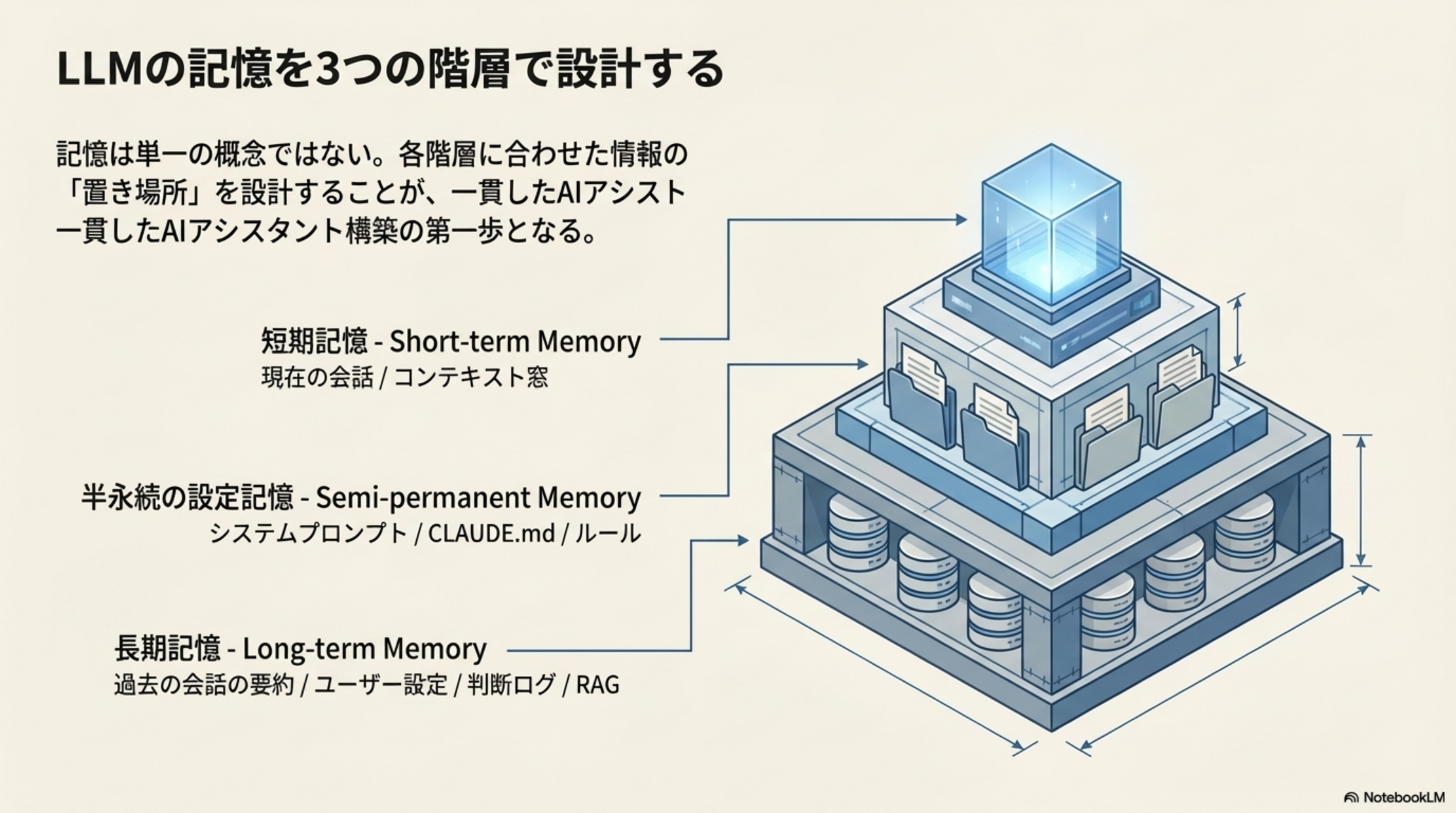
1. LLMの記憶を3つの階層で設計する
記憶は単一の概念ではありません。各階層に合わせた情報の「置き場所」を設計することが、一貫したAIアシスタント構築の第一歩となります。
| 階層 | 内容 | 特徴 | たとえ |
|---|---|---|---|
| 短期記憶 | 現在の会話 / コンテキストウィンドウ | セッション限りで揮発。トークン上限あり。LLMが「今見えている」情報 | 作業机の上に広げた書類 |
| 半永続の設定記憶 | システムプロンプト / CLAUDE.md / ルール | セッションを超えて維持される設定情報。毎回自動的に読み込まれる | デスクの引き出しにある手順書 |
| 長期記憶 | 過去の会話の要約 / ユーザー設定 / 判断ログ / RAG | 永続的に保存。必要な時だけ取り出す。容量は事実上無制限 | 書庫の棚にファイリングされた過去の記録 |
あなたはオフィスで働いています。短期記憶は今デスクに広げている書類(セッションが終われば片付ける)。半永続の設定記憶はデスクの引き出しにある「社内ルール集」や「自分の作業手順書」(毎朝確認する)。長期記憶は会社の書庫にある過去のプロジェクト資料(特定の案件で必要になった時だけ取りに行く)。
2. 巨大な1つのプロンプトから、階層化されたモジュールへ
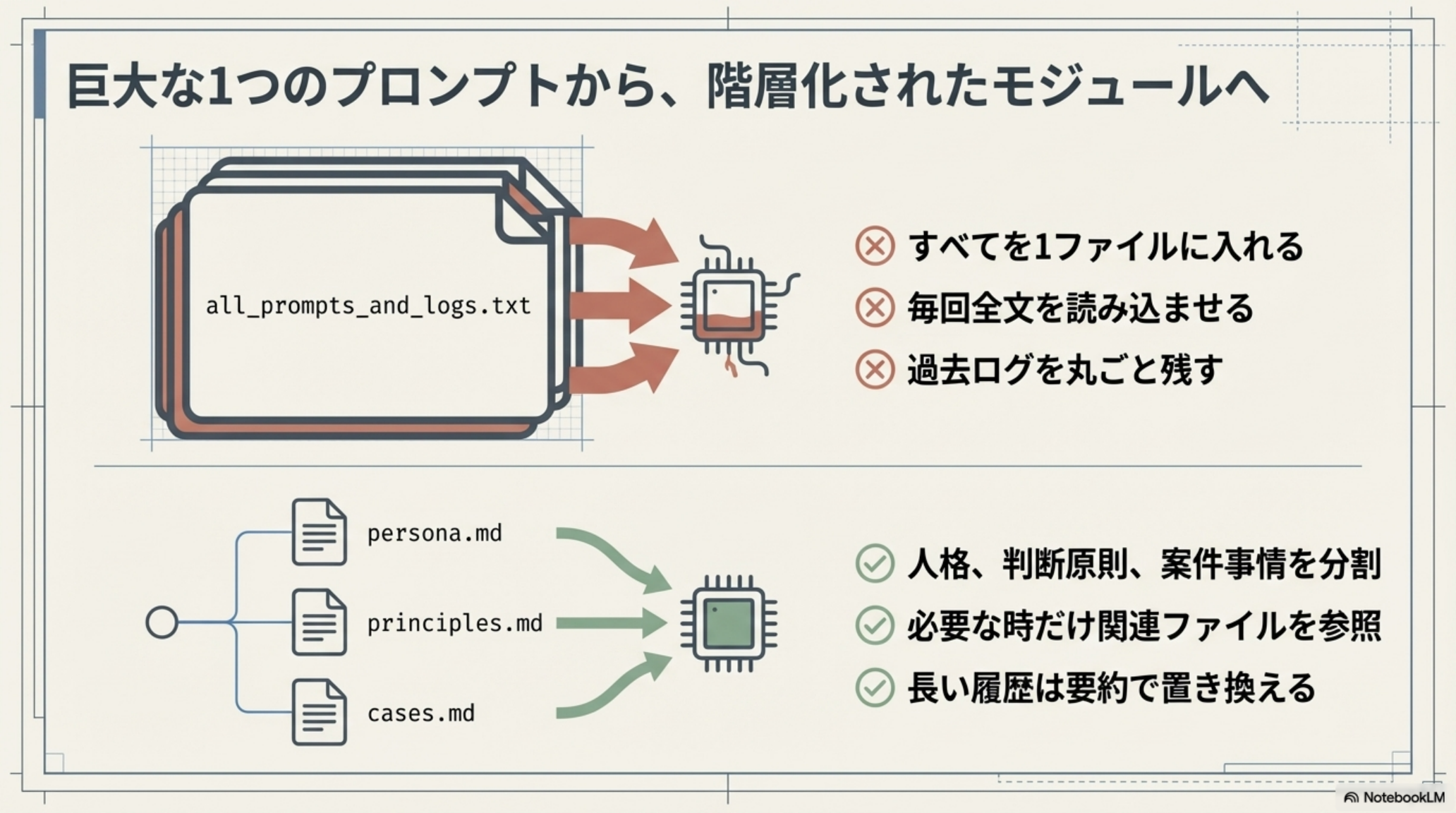
多くの人がやりがちな失敗は、すべての情報を1つの巨大なプロンプトに詰め込むことです。これは必ず破綻します。
ダメなパターン
all_prompts_and_logs.txt のような巨大ファイル1つに全てを入れる
- すべてを1ファイルに入れる
- 毎回全文を読み込ませる
- 過去ログを丸ごと残す
良いパターン
役割別に persona.md、principles.md、cases.md に分割
- 人格、判断原則、案件事情を分割
- 必要な時だけ関連ファイルを参照
- 長い履歴は要約で置き換える
LLMのコンテキストウィンドウには限りがあります。すべてを毎回読み込ませると:(1) トークンコストが爆発する (2) Lost in the Middle問題で中央の情報が無視される (3) 古い情報と新しい情報が矛盾した場合、LLMが混乱する。
3.「母艦」と「案件」を完全に分離するアーキテクチャ
1つに集約しすぎると話題が混線します。そこで、共通人格である「母艦(Mothership)」をOSとして置き、その上で動く専門作業場として「案件」プロジェクトを展開する設計が有効です。
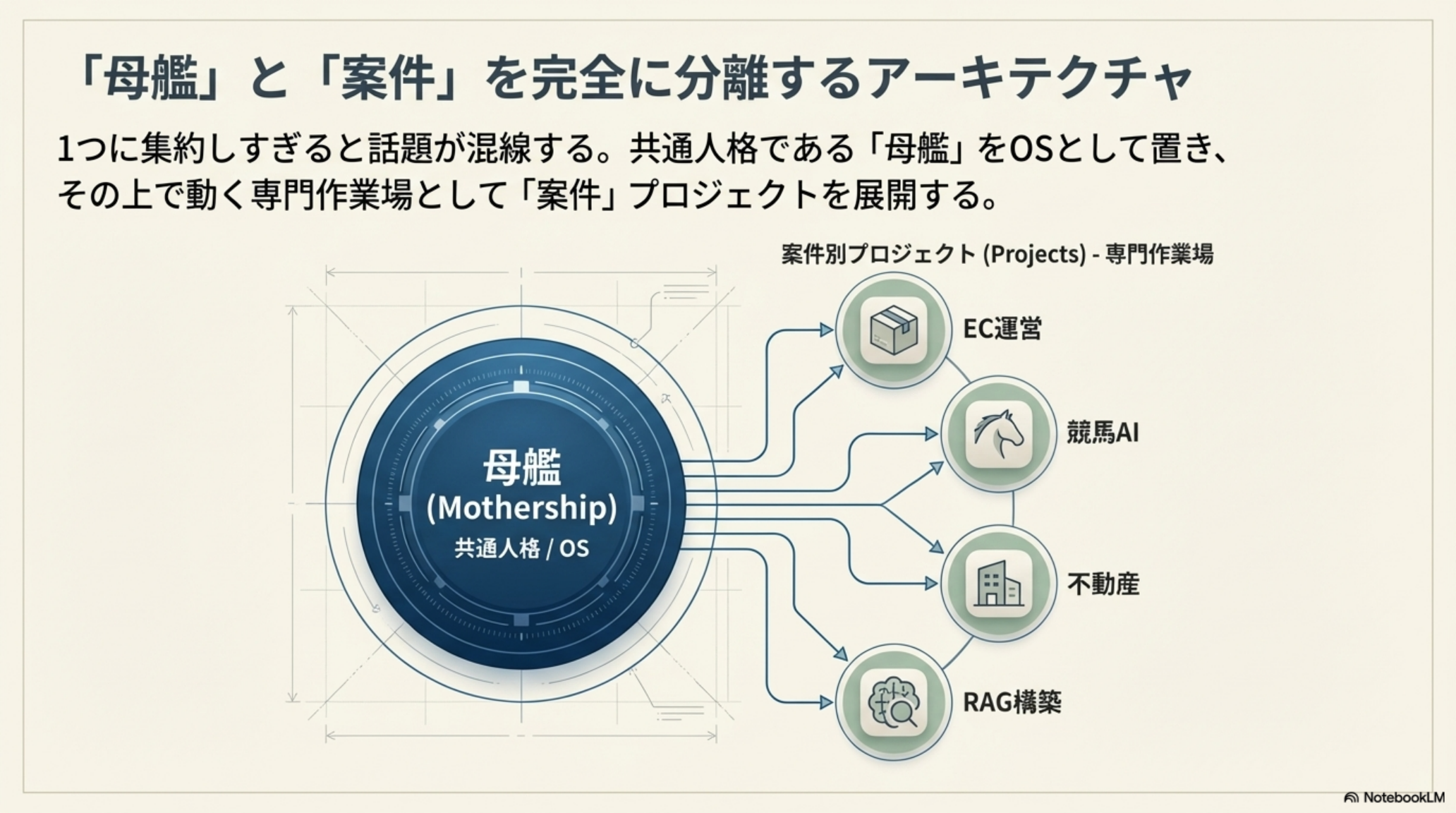
母艦は「会社の理念・行動規範・社風」のようなもの。どのプロジェクトに配属されても変わらない、共通のアイデンティティです。案件プロジェクトは「営業部」「開発部」「経理部」のような専門部署。それぞれ異なる目的・ツール・コンテキストを持っていますが、根底にある会社の文化は共有しています。
母艦(OS)を構成する4つのコアファイル
これらは「分身」の脳のコア。すべての案件において共通して読み込まれる基盤となります。
| ファイル名 | 役割 | 具体的な内容 |
|---|---|---|
persona_core.md |
人格の核 | 口調、結論の出し方、曖昧時の振る舞い |
decision_principles.md |
判断原則 | 仮定で進める条件、構造化のタイミング、再利用性の重視 |
response_style.md |
応答スタイル | 回りくどさの排除、実務フォーマット優先、Markdownの活用 |
global_memory.md |
恒久情報 | 長く残したい恒久情報、ユーザーの好み、固定ルール |
案件(ワークスペース)を構成する3つのコンテキスト
案件ごとの事情やログはここに隔離します。新規案件を立ち上げる際は、この薄いテンプレートをコピーするだけで開始できます。
| ファイル名 | 役割 | 具体的な内容 |
|---|---|---|
project_context.md |
案件コンテキスト | 案件の目的、制約、技術スタック、出力形式 |
decision_log.md |
判断ログ | 過去の重要判断、その理由、再利用条件 |
session_summary.md |
セッション要約 | 直近会話の短い要約、今回決まったこと、次回参照すべきこと |
この設計により、EC運営の案件で蓄積した判断ログが、競馬AIの案件に混入することがなくなります。各案件は独立したコンテキストを持ちつつ、母艦の共通人格を継承する。これが「分身」の安定した動作の秘訣です。
4. コンテキストを最適化する「読み込みの順序」
すべてを毎回全文読む必要はありません。「最初に人格の核を読み、最後に直近の要約を読む」ことで、最新状況の補正が正確に機能します。
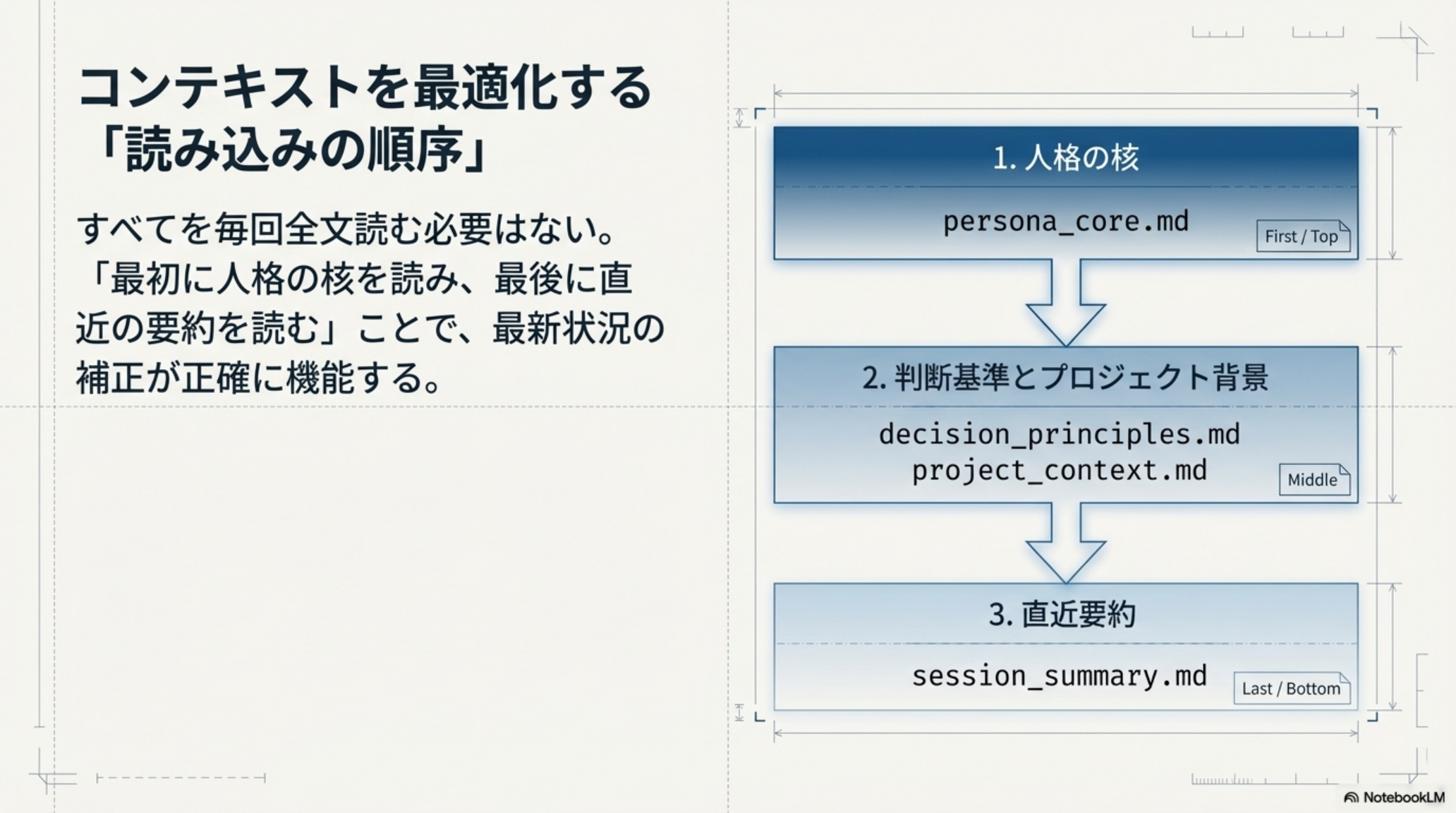
LLMは「最初」と「最後」に読んだ情報を最も重視する傾向があります(Primacy EffectとRecency Effect)。だからこそ、最初に「変わらない人格の核」を、最後に「最新のセッション要約」を配置することで、安定した人格と最新の文脈認識を両立できます。
毎朝出勤するとき、まず「自分が誰で、どんな立場か」を意識し(人格の核)、次に「今日の会議資料とプロジェクトの背景」を確認し(中間層)、最後に「昨日のメモと今日のToDo」をチェックする(直近要約)。この順番が逆だと混乱しますよね。LLMも同じです。
5. 実装方法:ChatGPTとClaude Codeそれぞれの場合
ChatGPT Web UIでの実装:Projects機能を活用する
- フォルダ指定は不要:Web UIではローカルフォルダを常時同期する運用は行わない
- Projectsを分身専用の箱に:左メニューからProjectを作成し、コアファイル群(.mdファイル)をアップロード
- Project Instructionsの重要性:単にファイルを置くだけでなく、指示文に「どのファイルを優先するか」「何を最新情報として扱うか」を明記することで出力が安定する
Claude Code / ローカル環境での実装:CLAUDE.mdを入口にする

- 入口を絞る:Claude Codeでは、CLAUDE.mdを案件の入口として機能させる
- 詳細の分離:CLAUDE.md自体は短く保ち、「何を参照し、どう応答するか」のルーティングに特化させる。詳細は別ファイルへ逃がす
CLAUDE.mdは会社の受付のようなもの。来客(ユーザーの質問)が来たら、「このお客様にはAさん(persona_core.md)が対応すべき」「この案件はBさん(project_context.md)の担当」と振り分ける。受付自身が全部対応するのではなく、適切な担当者に振り向けるのが仕事です。
6. コンテキストの圧迫を防ぐ運用ガイドライン
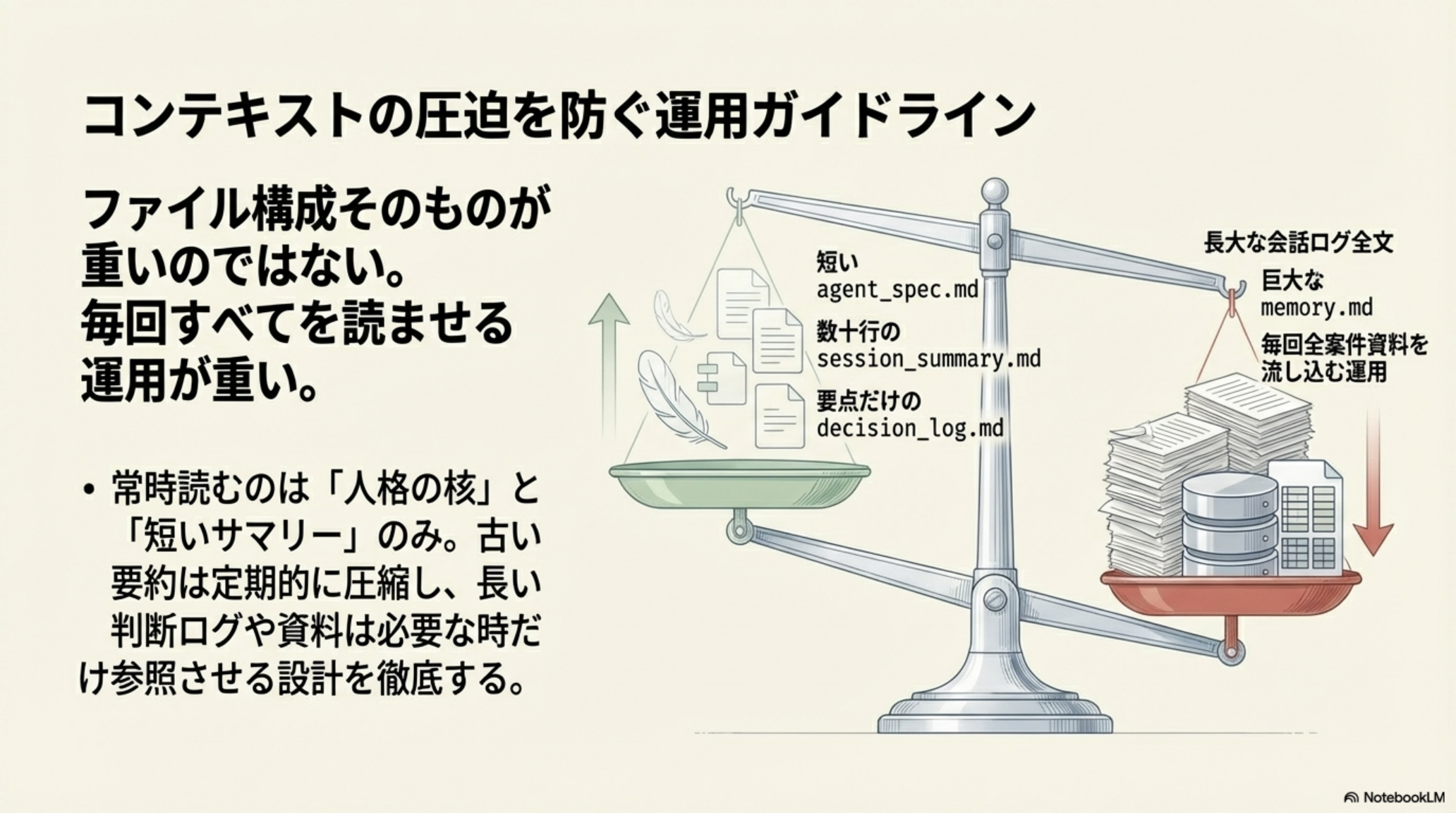
ファイル構成そのものが重いのではない。毎回すべてを読ませる運用が重いのです。
軽い運用(推奨)
- 短い
agent_spec.md - 数十行の
session_summary.md - 要点だけの
decision_log.md
常時読むのは「人格の核」と「短いサマリー」のみ。
重い運用(非推奨)
- 長大な会話ログ全文
- 巨大な
memory.md - 毎回全案件資料を流し込む運用
コンテキストが圧迫され、精度もコストも悪化する。
- 常時読むものは「人格の核」と「短いサマリー」のみ
- 古い要約は定期的に圧縮する
- 長い判断ログや資料は必要な時だけ参照させる設計を徹底する
毎日の通勤カバンに、過去10年分の仕事ファイルを全部入れて持ち歩く人はいません。今日使うものだけ入れ、過去の資料はオフィスの棚に置いておく。LLMのコンテキスト管理もまったく同じ発想です。
7. 完璧主義を捨てて「最小構成の分身(v1)」から育てる
今回の設計思想だけで、実用的な初版(v1)は構築可能です。最初から完全なログや例外処理を用意する必要はありません。
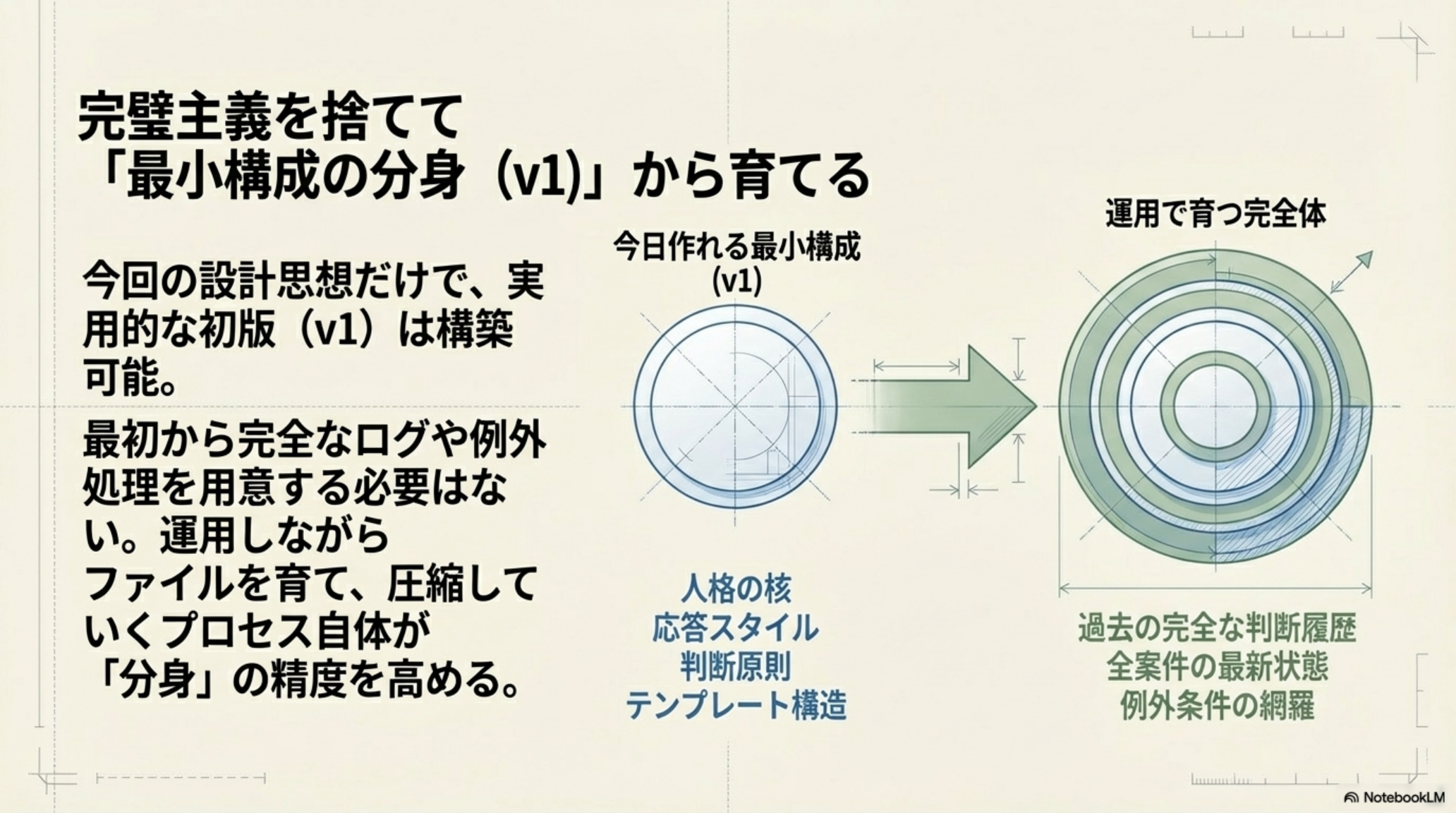
運用しながらファイルを育て、圧縮していくプロセス自体が「分身」の精度を高めます。最初から完璧を目指すのではなく、まず最小構成で動かし、使いながら改善していくというアジャイルな発想が重要です。
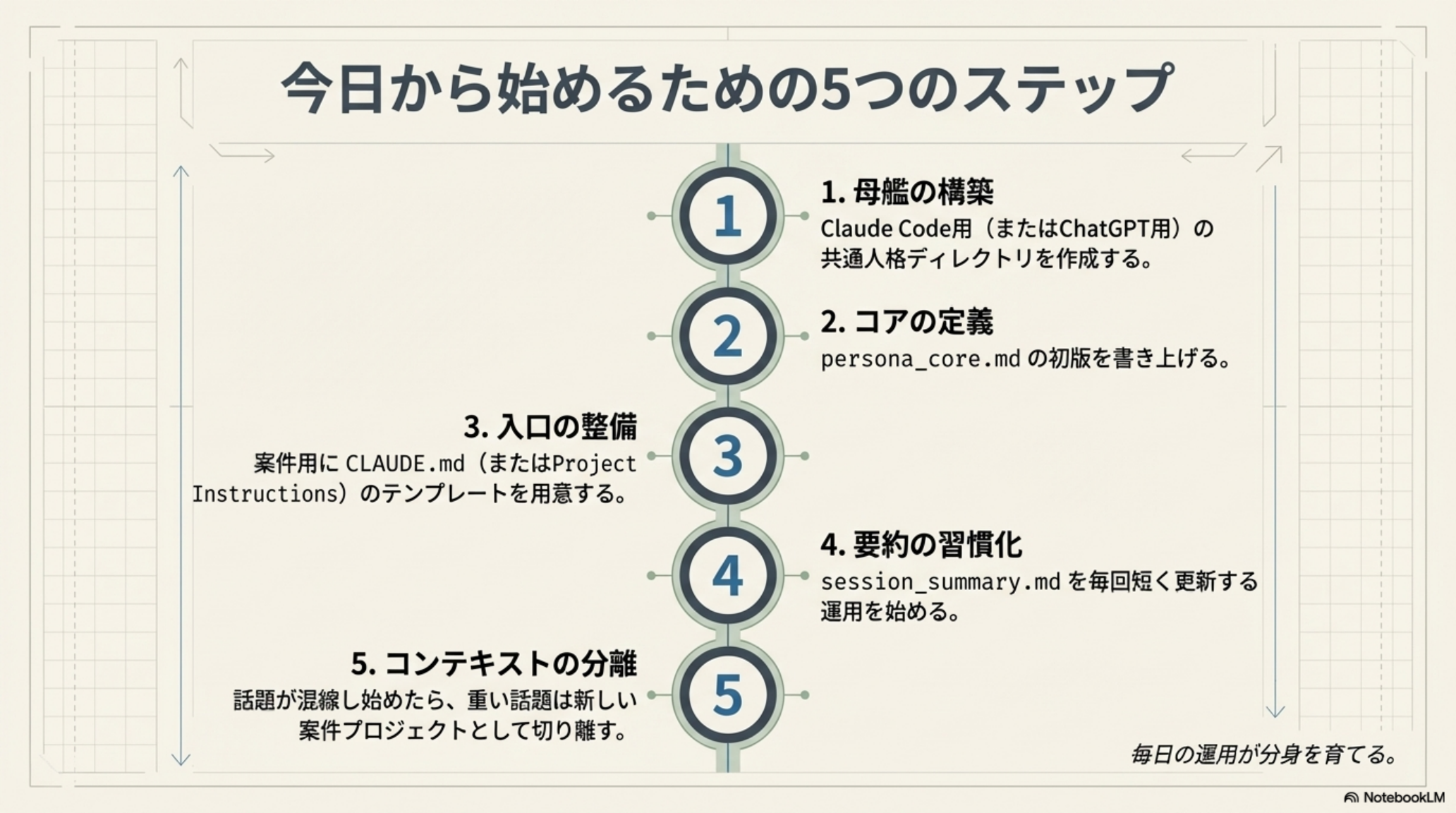
8. 今日から始めるための5つのステップ
ここまでの設計思想を、具体的なアクションに落とし込みましょう。以下の5ステップを順番に実行すれば、今日中に「分身v1」が完成します。
-
母艦の構築
Claude Code用(またはChatGPT用)の共通人格ディレクトリを作成する。フォルダ1つ作るだけでOK。 -
コアの定義
persona_core.mdの初版を書き上げる。完璧でなくていい。「自分のAIアシスタントにこう振る舞ってほしい」を箇条書きで書くだけで十分。 -
入口の整備
案件用にCLAUDE.md(またはProject Instructions)のテンプレートを用意する。「まずpersona_core.mdを読んでください」と一行書くだけでもスタートできる。 -
要約の習慣化
session_summary.mdを毎回短く更新する運用を始める。会話の最後に「今日の要約を書いて」と頼むだけ。 -
コンテキストの分離
話題が混線し始めたら、重い話題は新しい案件プロジェクトとして切り離す。「このテーマは別プロジェクトにしよう」と判断するタイミングを覚える。
5つのステップは一度やって終わりではありません。毎日のAIとのやり取りの中で、ファイルを更新し、要約を圧縮し、新しい案件を分離する。この日常的な「手入れ」こそが、分身の精度を高める最大の秘訣です。
まとめ:記憶の設計が「分身」の品質を決める
- コンテキストウィンドウだけに頼る運用は必ず破綻する
- 記憶は3階層(短期・半永続・長期)で設計する
- 巨大な1ファイルではなく、役割別モジュールに分割する
- 母艦(共通人格)と案件(プロジェクト)を分離することで混線を防ぐ
- 母艦の4コアファイル:
persona_core.md/decision_principles.md/response_style.md/global_memory.md - 案件の3コンテキスト:
project_context.md/decision_log.md/session_summary.md - CLAUDE.mdはエントリポイント。短く保ち、ルーティングに特化させる
- 読み込み順序は「人格の核(最初)→ 判断基準(中間)→ 直近要約(最後)」
- 毎回全文を読ませるのではなく、必要な時だけ参照する設計が鍵
- 完璧主義を捨て、最小構成v1から運用で育てる
LLMの「分身」は、モデルの性能だけでは作れません。情報をどこに置き、いつ読み、どう更新するか -- この記憶アーキテクチャの設計こそが、一貫性のある実用的なAIアシスタントを生み出す鍵です。
元のスライド一覧
クリックで拡大表示できます