はじめに:「言葉遣い」ではなく「在り方」を複製する
従来のAI分身(デジタルツイン)は、対象者の発言を表面的に模倣することに留まっていました。プロンプトで口調を指定したり、RAGで過去の発言を検索して貼り付けたり。しかし、それでは根拠のない文脈の「創作」や、人格のブレ(ハルシネーション)が頻発します。
Project GENは、この限界を突破するために設計された次世代の認知アーキテクチャです。対象者の思想、信念、価値観に基づく推論プロセスを完全再現します。鍵となるのは、コーチングセッション(1対1の対話録)の書き起こしをデータソースとすることで、「相手の状態を読み解いてから関わる」という対象者本来の関わり方がデータに自然に内包される点です。
- 従来手法(What)とProject GEN(Why/How)の本質的な違い
- 3層メモリRAGパイプラインの理論と実装
- Chronicle Graph:検索可能な「関係性」の構築
- Case Layer:網羅性と人格純度の両立戦略
- 世界の主要な人格コピー手法との比較
- 書籍ソースからの人格構築パイプライン
- 実装ロードマップと研究最前線との合致
1. 目的:「What」ではなく「Why/How」を複製する
従来手法とProject GENの根本的な違いは、何を再現しようとしているかにあります。
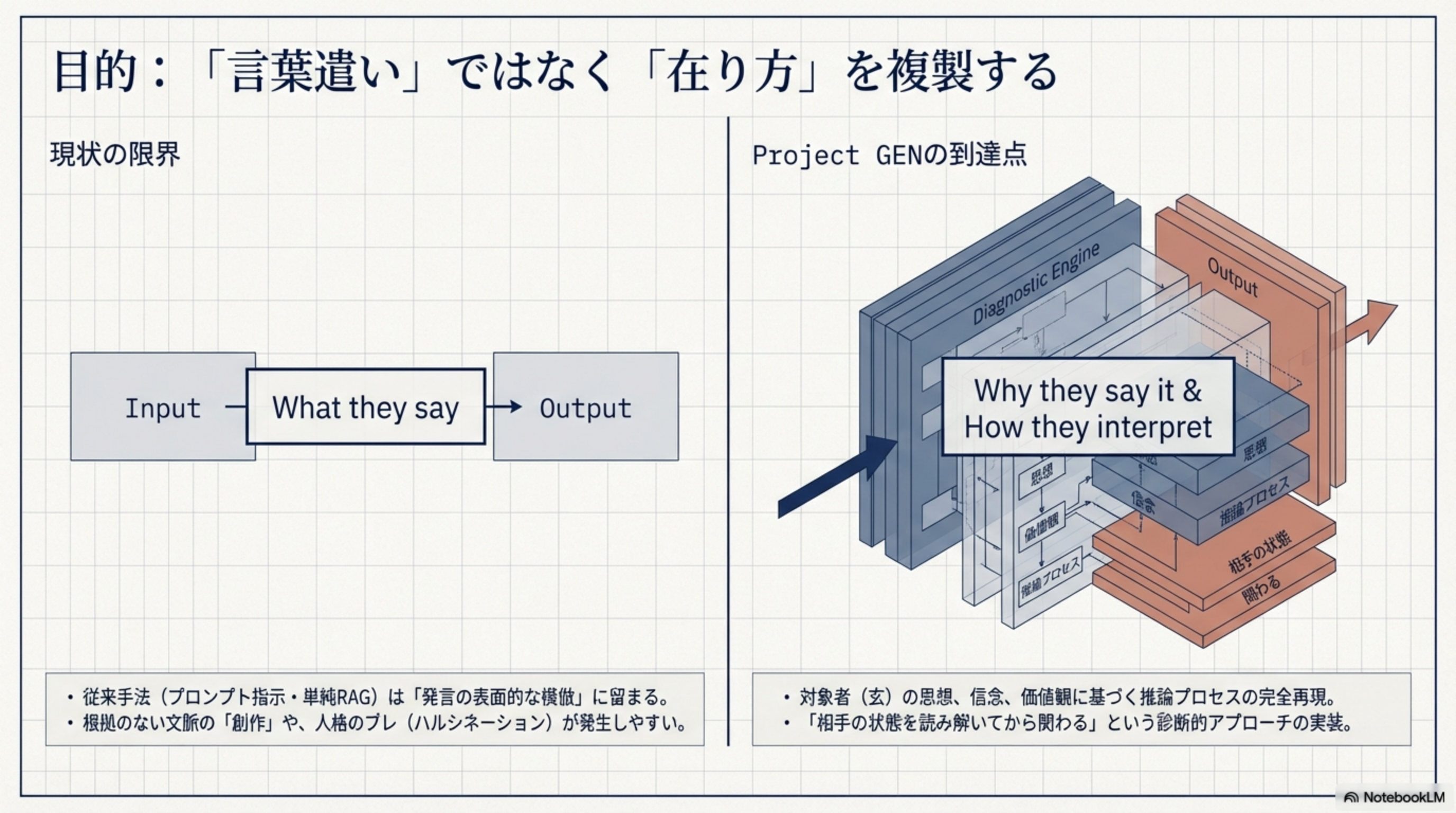
現状の限界(What)
Input → What they say → Output。従来手法(プロンプト指示・単純RAG)は「発言の表面的な模倣」に留まる。根拠のない文脈の「創作」や、人格のブレ(ハルシネーション)が発生しやすい。
Project GENの到達点(Why/How)
Why they say it & How they interpret → Output。対象者の思想、信念、価値観に基づく推論プロセスの完全再現。セッション書き起こし(対話録)をデータソースとすることで、「相手の状態を読み解いてから関わる」という対象者の関わり方が自然に再現されます。
2. 理論的青写真:3層メモリRAGパイプライン
Project GENの基盤となる3層メモリ構造を解説します。下から上へ、データの抽象度が上がっていきます。
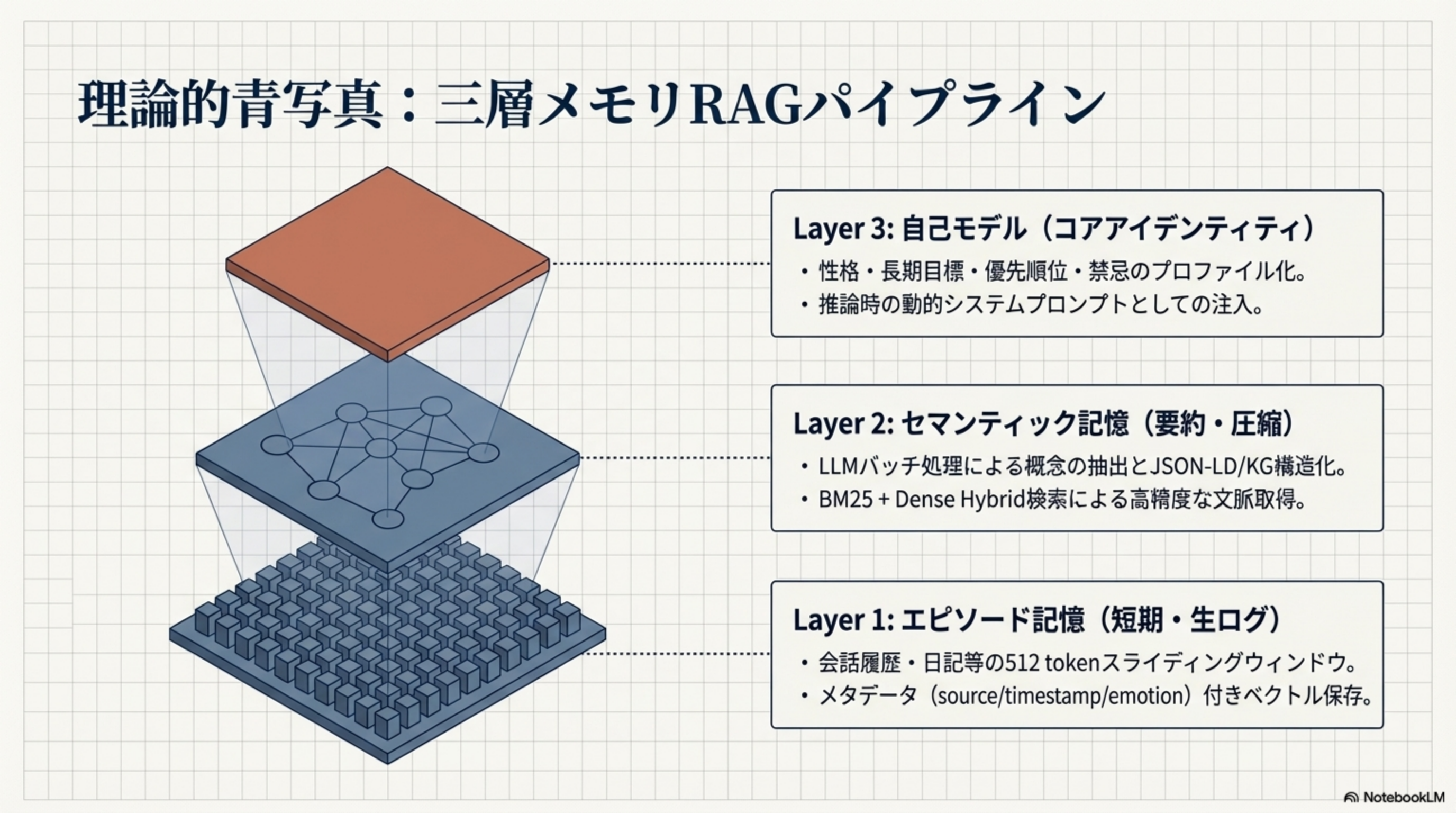
| 層 | 名称 | 内容 | 技術要素 |
|---|---|---|---|
| Layer 1 | エピソード記憶(短期・生ログ) | 会話履歴・日記等の512 tokenスライディングウィンドウ | ruri-v3でベクトル化、メタデータ(source/timestamp/emotion)付き保存 |
| Layer 2 | セマンティック記憶(要約・圧縮) | LLMバッチ処理による概念の抽出とJSON-LD/KG構造化 | BM25 + Dense Hybrid検索による高精度な文脈取得 |
| Layer 3 | 自己モデル(コアアイデンティティ) | 性格・長期目標・優先順位・禁忌のプロファイル化 | 推論時の動的システムプロンプトとしての注入 |
3. 実装への翻訳:Project GEN アーキテクチャ
理論的な3層構造が、Project GENでどのように具体的に実装されているかを見ます。
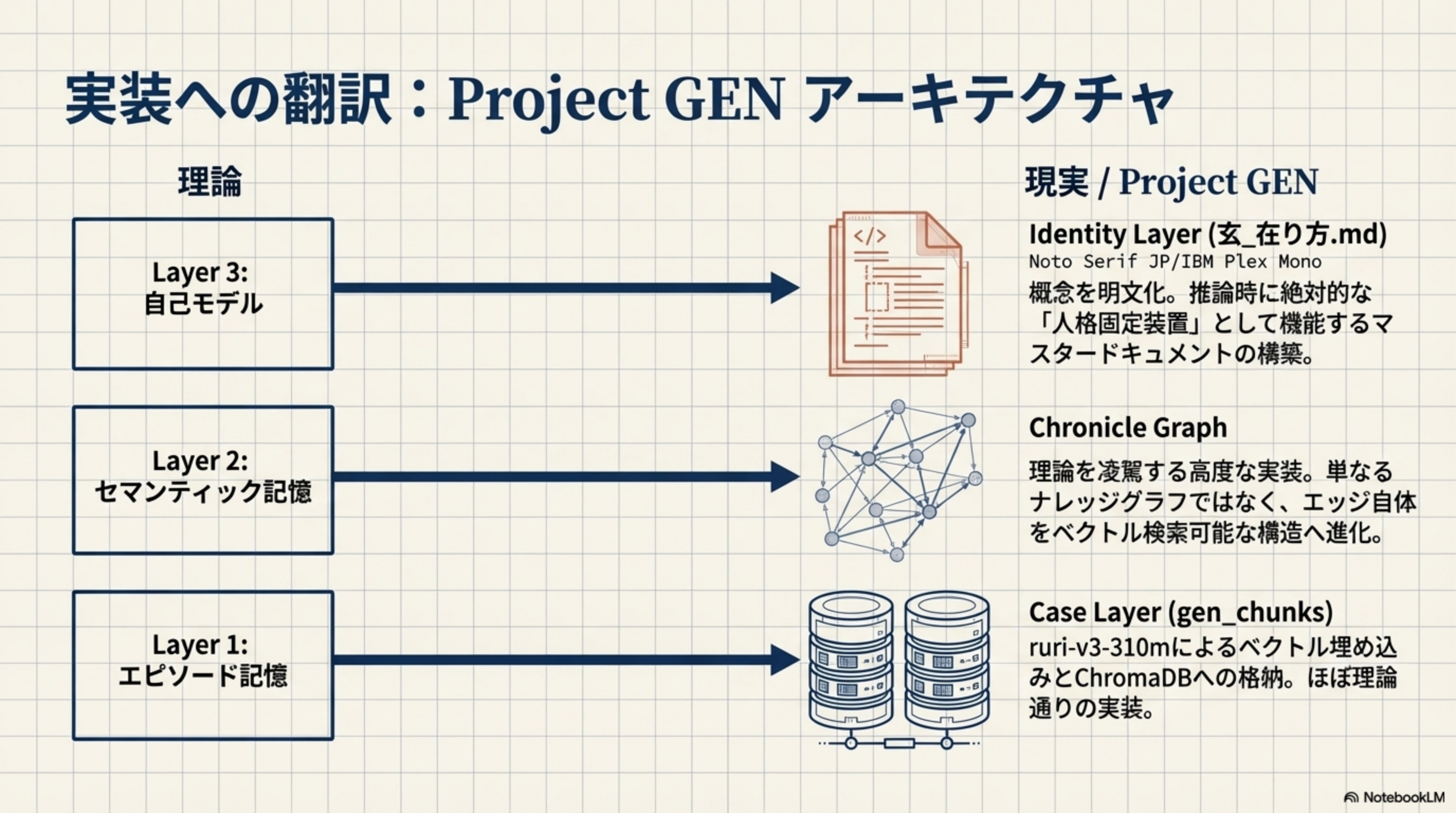
| 理論 | Project GEN 実装 | 評価 |
|---|---|---|
| Layer 3: 自己モデル | Identity Layer(玄_在り方.md) - 概念を明文化。推論時に絶対的な「人格固定装置」として機能するマスタードキュメント | 概念は同一、GENは明文化で上回る |
| Layer 2: セマンティック記憶 | Chronicle Graph - 理論を凌駕する高度な実装。単なるナレッジグラフではなく、エッジ自体をベクトル検索可能な構造へ進化 | GENが理論より高度 |
| Layer 1: エピソード記憶 | Case Layer(gen_chunks) - ruri-v3-310mによるベクトル埋め込みとChromaDBへの格納 | ほぼ理論通りの実装 |
オフライン構築パイプライン
初回構築時やデータ更新時に実行される、インデックス構築の全体フローです。

- 入力データ収集 - セッション書き起こし(1対1の対話録)、会話ログ、日記・メモ、玄_在り方.md
- 前処理 - ファイル分類 + 話者抽出 → PIIマスク → チャンク分割(chunks.jsonl)
- Identity Layer構築 - 在り方抽出・整理 → Chronicle Graph構築 → エッジをruri-v3-310mで事前埋め込み
- Case Layer構築 - ruri-v3-310m埋め込み → gen_chunks(全チャンク)/ gen_chunks_hi(GEN発話専用)→ BM25インデックス並行構築
オンライン応答パイプライン
ユーザーの発話ごとにリアルタイムで実行される、応答生成の全体フローです。

- ユーザー入力 → ruri-v3-310mでベクトル化(768次元)
- 4並列検索 - Semantic検索(gen_chunks)+ Semantic検索(gen_chunks_hi)+ BM25検索 + Chronicle Graphエッジ検索
- RRF統合 - 4本の検索結果を順位ベースで統合・候補絞り込み
- クロスエンコーダーリランキング - クエリ×チャンクのペアを精密スコアリング
- チャンク文脈拡張 - ヒットチャンクの前後を結合し意味の流れを補完
- Identity Layer注入 + 最終プロンプト組立 - 在り方 + Chronicleエッジ + ユーザープロファイル + 検索chunk + 会話履歴を統合
- Claude API(ストリーミング応答)→ 人格として応答出力
4. Case Layer:網羅性と人格純度の両立
生データからベクトルDBに格納する際、2つのコレクションに分けることで、網羅性と人格純度を同時に担保します。
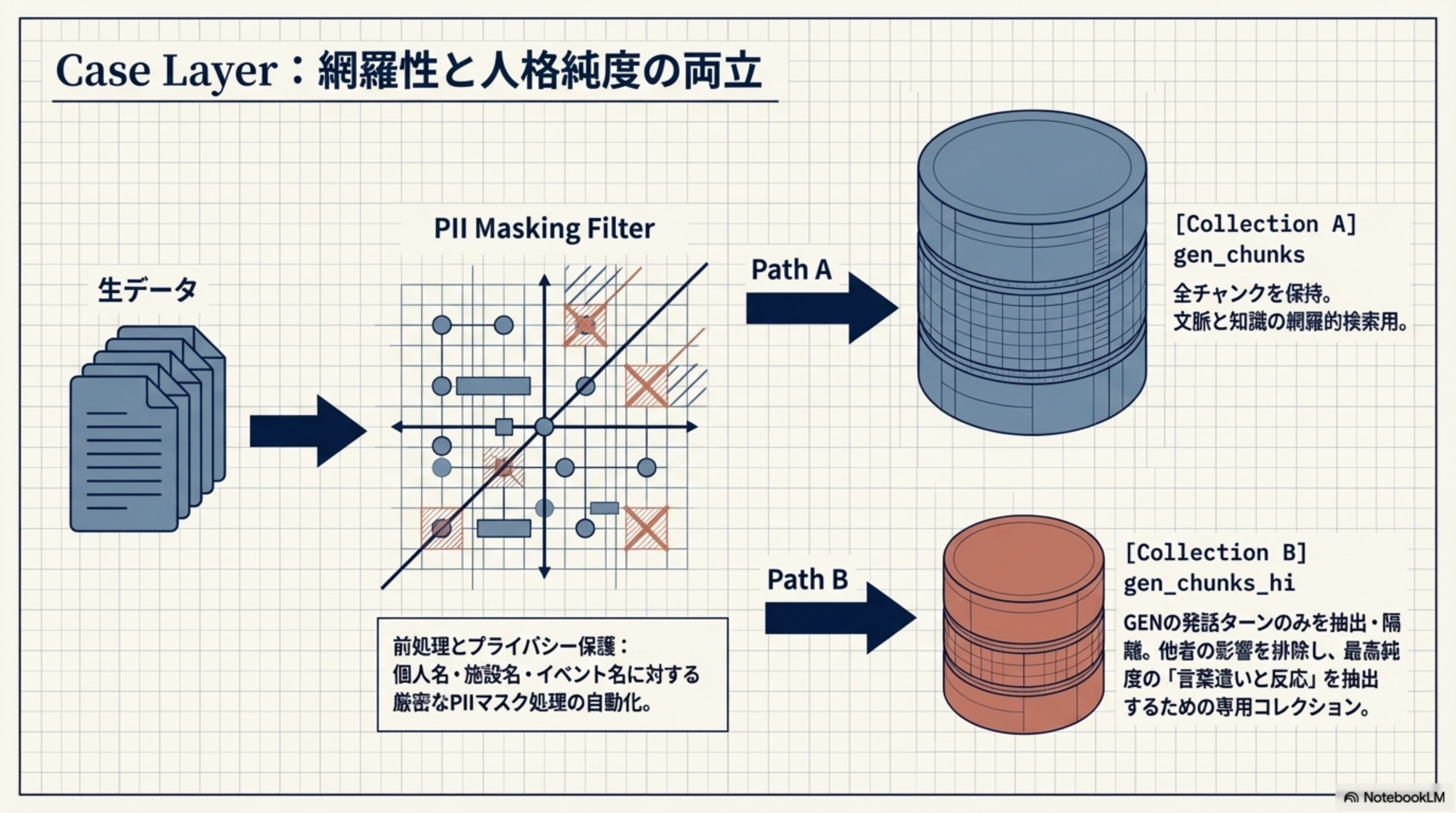
Collection A: gen_chunks
全チャンクを保持。文脈と知識の網羅的検索用。対話の全体像を捉えるために使用します。
Collection B: gen_chunks_hi
対象者の発話ターンのみを抽出・隔離。他者の影響を排除し、最高純度の「言葉遣いと反応」を抽出するための専用コレクション。
前処理段階で個人名・施設名・イベント名に対する厳密なPIIマスク処理を自動化。プライバシー保護はAI分身構築における必須の倫理的要件です。
5. Chronicle Graph:検索可能な関係性
Project GENの最も革新的な要素の一つが、Chronicle Graphです。単なるエンティティの羅列ではなく、事象間の「関係性」にこそ人格が宿るという洞察に基づいています。
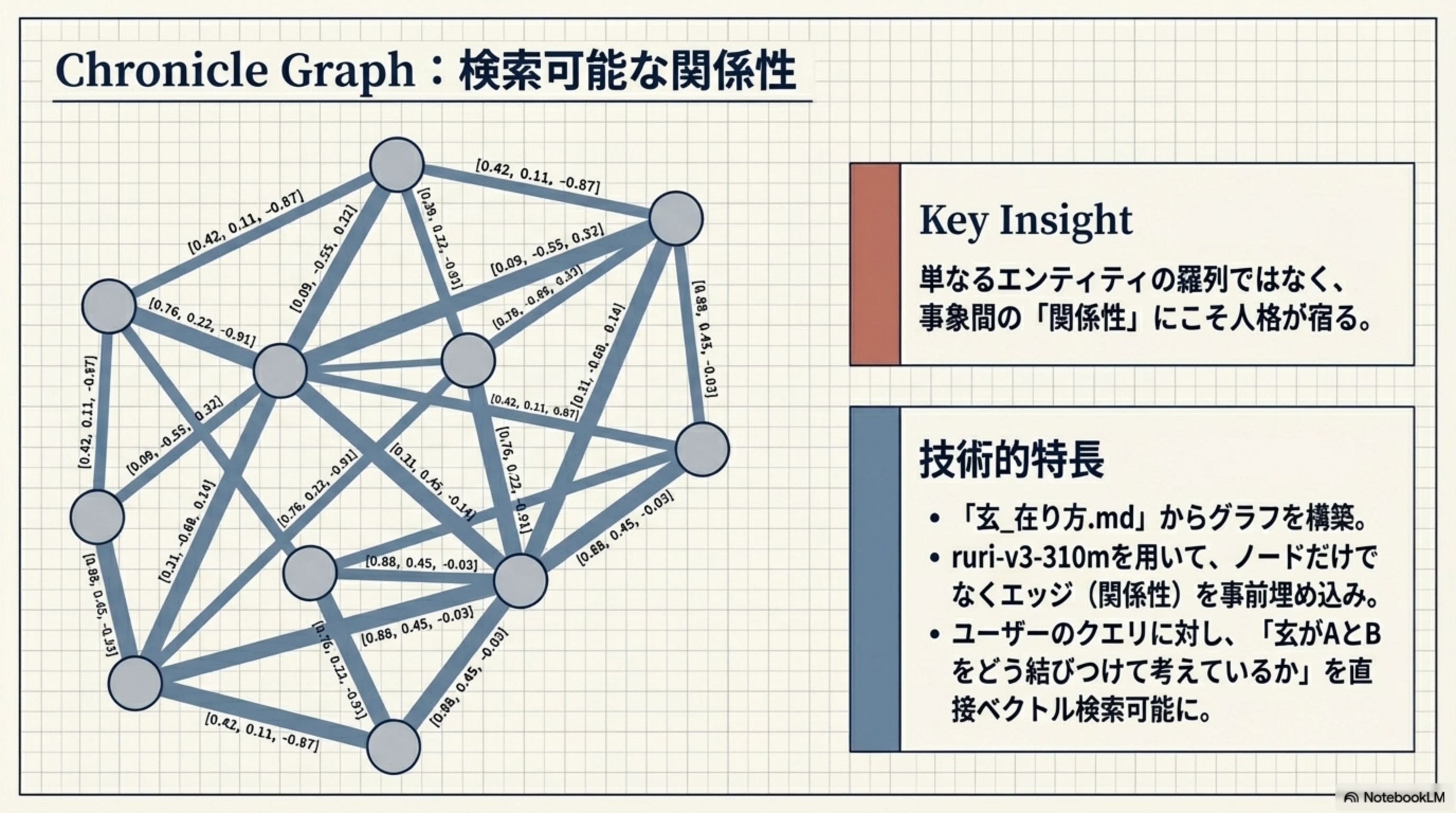
- 「玄_在り方.md」からグラフを構築
- ruri-v3-310mを用いて、ノードだけでなくエッジ(関係性)を事前埋め込み
- ユーザーのクエリに対し、「対象者がAとBをどう結びつけて考えているか」を直接ベクトル検索可能に
通常のナレッジグラフは「人物A」「場所B」「概念C」というノード(点)を保存します。Chronicle Graphはそれに加え、「AがBについてどう考えているか」「AがCをなぜ重要視するか」という線(エッジ)自体をベクトルとして検索できるようにしています。人格の本質は「何を知っているか」ではなく「何と何をどう結びつけるか」にあるからです。
6. 核心的優位性:「言葉の模倣」から「在り方の再現」へ
氷山モデルでProject GENの独自性を理解しましょう。水面上(Surface Level)の模倣にとどまるか、水面下(Below the Surface)の推論プロセスまで再現するかが決定的な違いです。
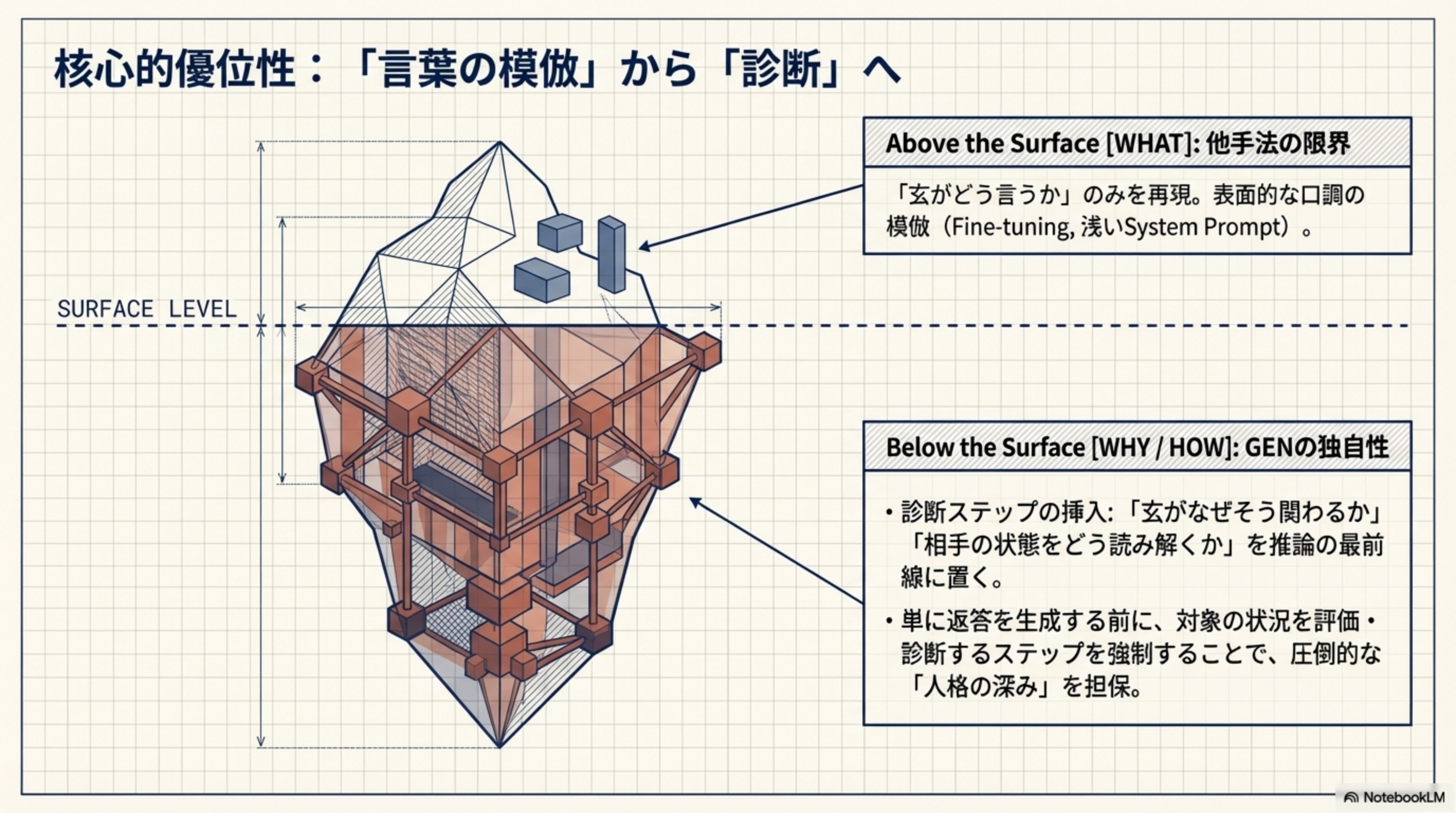
Above the Surface [WHAT]: 他手法の限界
「対象者がどう言うか」のみを再現。表面的な口調の模倣(Fine-tuning、浅いSystem Prompt)にとどまります。
Below the Surface [WHY/HOW]: GENの独自性
「対象者がなぜそう関わるか」「相手の状態をどう読み解くか」を推論の最前線に置きます。専用のロジックが存在するわけではなく、セッション書き起こし(1対1の対話録)自体に、対象者の関わり方・読み解き方が自然に内包されていることがポイントです。この対話録をデータソースとすることで、圧倒的な「人格の深み」を担保します。
7. グローバル・ランドスケープにおけるGENの立ち位置
世界の主要な人格コピー手法と比較した際の、Project GENのポジショニングです。
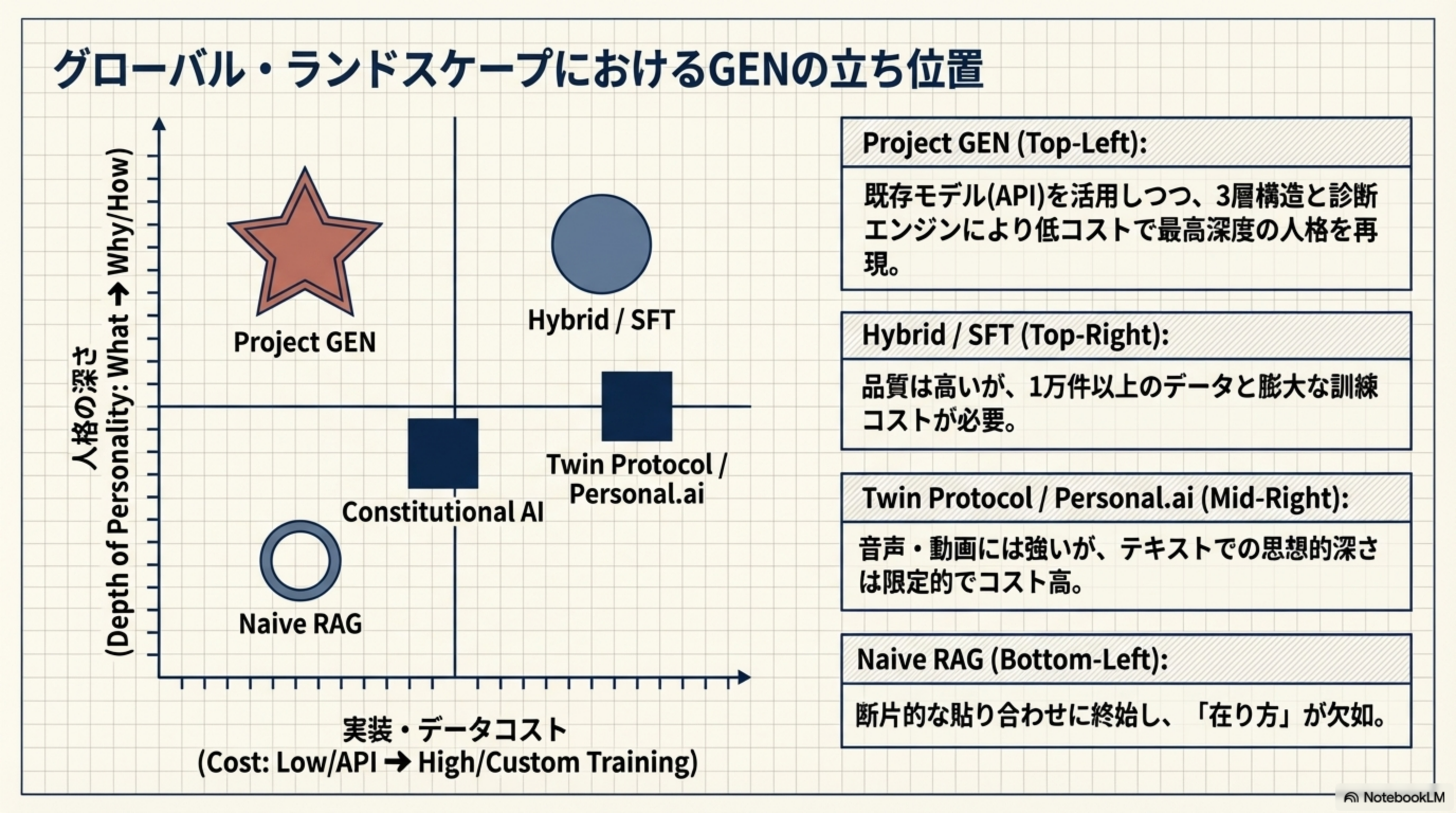
| 手法 | しくみ | 弱点 | GENとの差分 |
|---|---|---|---|
| Fine-tuning (SFT/LoRA) | モデル自体に人格を直接学習 | 1万件以上のデータ必要。更新不可 | データ量に依存せず「在り方」を構造的に再現 |
| Naive RAG | 発言をDBに入れて検索・引用 | 断片的な貼り合わせ。「在り方」が欠如 | 3層構造により検索を超えた一貫性を保持 |
| System Prompt | プロンプトに人格を文章で書く | 表面的な口調のみ。根拠なく「創作」に | 設定文ではなく「セッション対話録・事例」の根拠に基づく |
| GraphRAG / ID-RAG | 価値観・特性をグラフ構造で保持 | 実装が極めて複雑 | 思想は近いが、GENはセッション対話録を活用した「在り方の再現」に特化 |
| Hybrid (FT + RAG) | 語り口をFT、知識をRAGで補完 | 最高品質だがコスト・データともに高い | 既存モデルを活用しつつ低コストで実現 |
| Stanford Generative Agent | 2時間インタビュー記録 × LLM | インタビューデータの収集コスト | BM25+RRF+リランキングで検索精度が上 |
「言葉の模倣」ではなく、セッション書き起こし(対話録)をデータソースとすることで「相手の状態を読み解いてから関わる(Why/How)」が自然に再現される点が、世界的な既存手法に対する独自性です。専用の診断ロジックではなく、対話録自体に対象者の関わり方が内包されています。arXiv 2025のID-RAGと独立して同じ発想に到達しており、研究最前線と同水準の設計です。
8. データパイプライン:書籍ソースの最適解
書籍をデータソースとしてAI分身を構築する場合の、最適なパイプライン設計です。
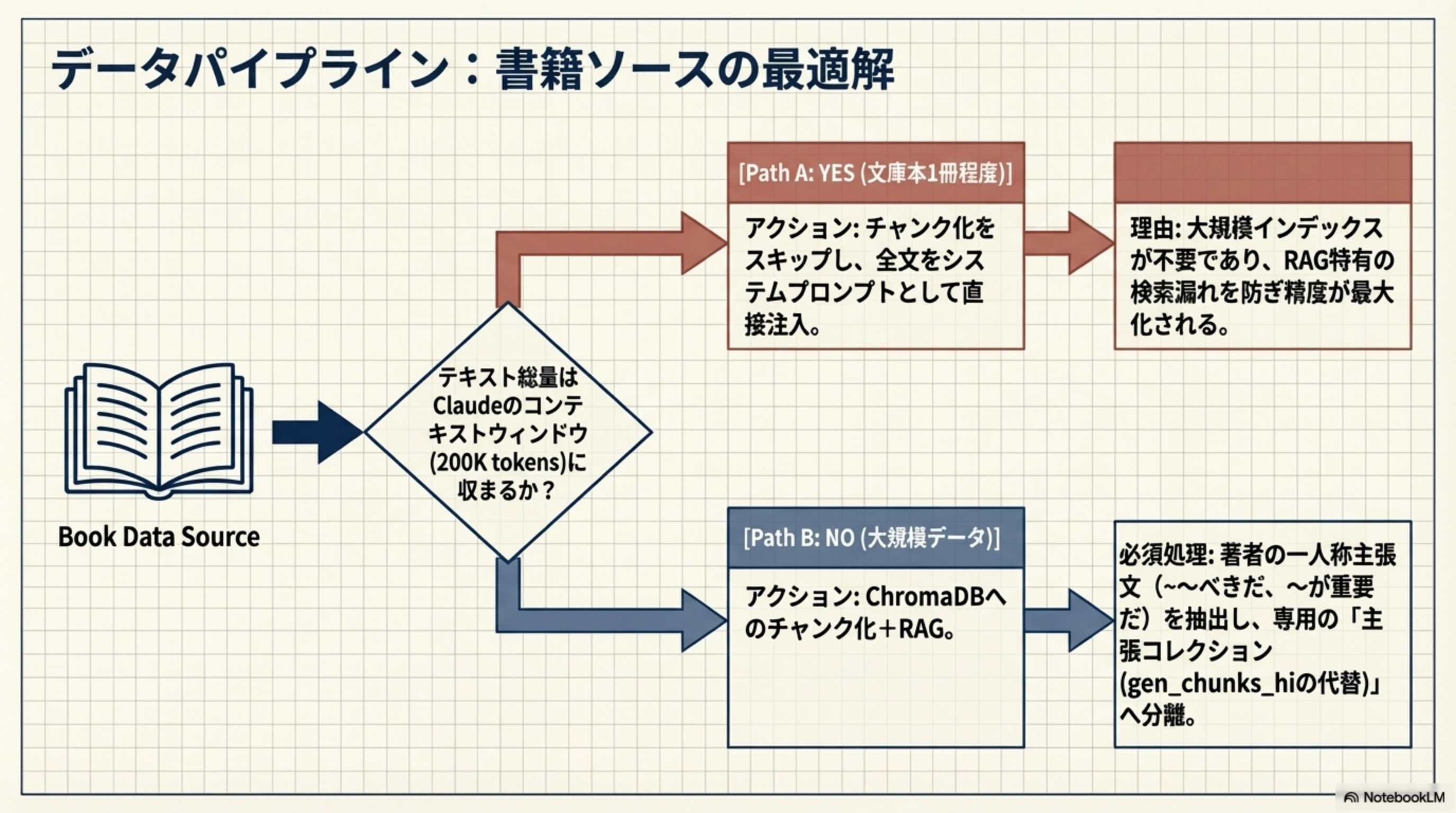
Path A: YES(文庫本1冊程度)
テキスト総量がClaudeのコンテキストウィンドウ(200K tokens)に収まる場合、チャンク化をスキップし全文をシステムプロンプトとして直接注入。大規模インデックス不要で、RAG特有の検索漏れを防ぎ精度が最大化されます。
Path B: NO(大規模データ)
ChromaDBへのチャンク化 + RAG。必須処理として、著者の一人称主張文(〜べきだ、〜が重要だ)を抽出し、専用の「主張コレクション」(gen_chunks_hiの代替)へ分離します。
9. 「在り方.md」半自動構築ワークフロー
Identity Layer の核心である「在り方.md」を、LLMを使って半自動で構築するプロセスです。

| Phase | 自動化度 | Human vs. LLM Workload |
|---|---|---|
| Step 1: 信念・価値観の抽出 | High(LLM主体) | LLMが草案生成。人間は明らかな誤抽出のみ削除 |
| Step 2: 主張文の収集 | High(LLM主体) | LLMが網羅的に抽出。人間が重要度を判断・フィルタリング |
| Step 3: Graphの構造化 | Medium | LLMがノード間の関係性を提案。人間が文脈と整合性を確認 |
| Step 4: 最終レビュー | Zero(人手必須) | [必須] 本人または熟知者による「これは在り方として正しいか」の最終承認 |
Step 4 の最終レビューだけはLLMに委任できません。「これは対象者の在り方として正しいか」はLLMには判断できない領域です。本人または対象者を深く知る人間による確認が絶対に必要です。
10. 実装ロードマップ:5つのフェーズ
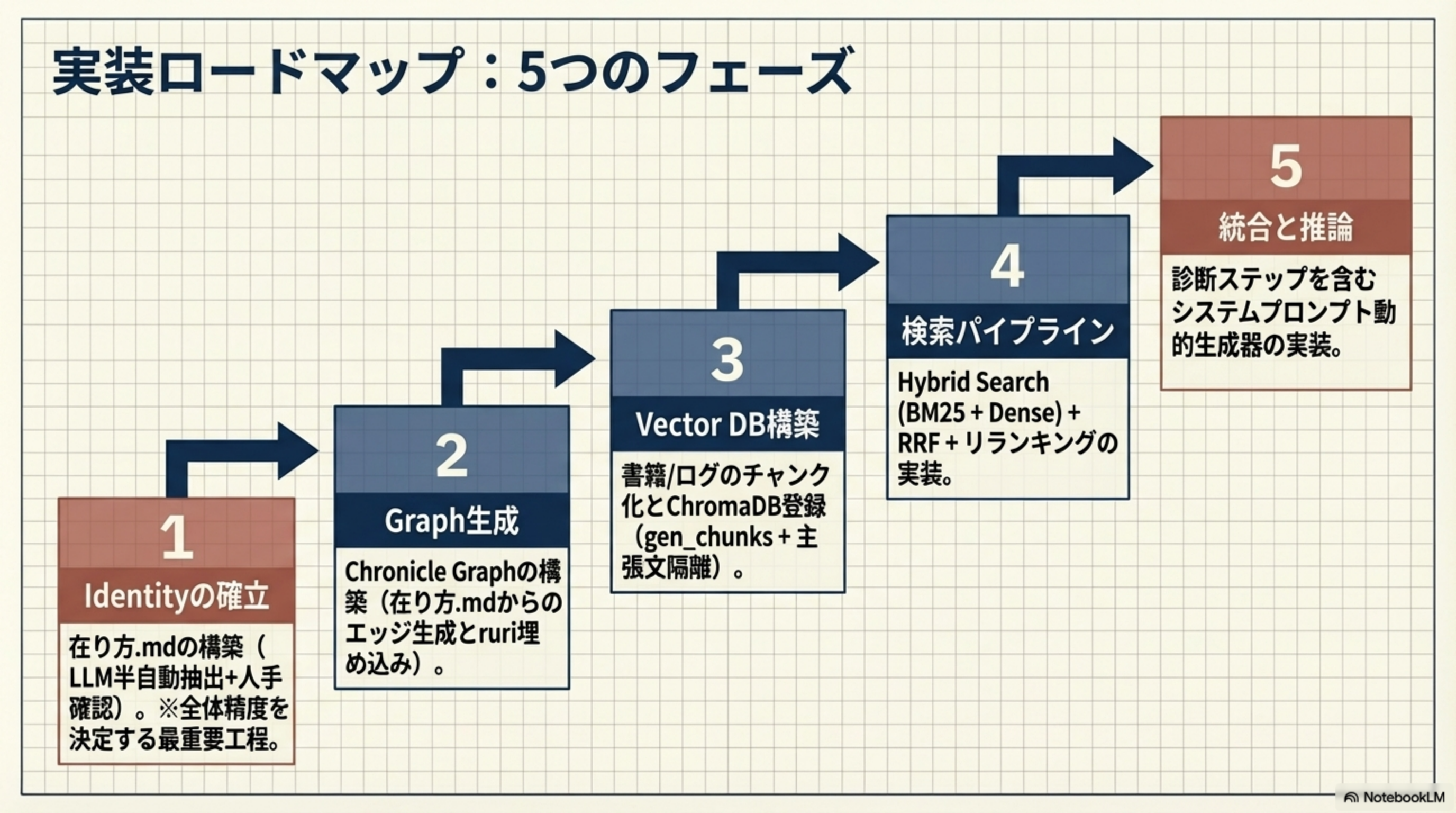
-
Identity の確立
在り方.mdの構築(LLM半自動抽出 + 人手確認)。全体精度を決定する最重要工程。 -
Graph生成
Chronicle Graphの構築(在り方.mdからのエッジ生成とruri埋め込み)。 -
Vector DB構築
書籍/ログのチャンク化とChromaDB登録(gen_chunks + 主張文隔離)。 -
検索パイプライン
Hybrid Search(BM25 + Dense) + RRF + リランキングの実装。 -
統合と推論
在り方 + 対話録 + Chronicle Graphを統合するシステムプロンプト動的生成器の実装。
11. アカデミック・バリデーション:研究最前線との合致
Project GENのアーキテクチャは、独立した設計でありながら、世界の研究最前線(SOTA)と驚くほど合致しています。
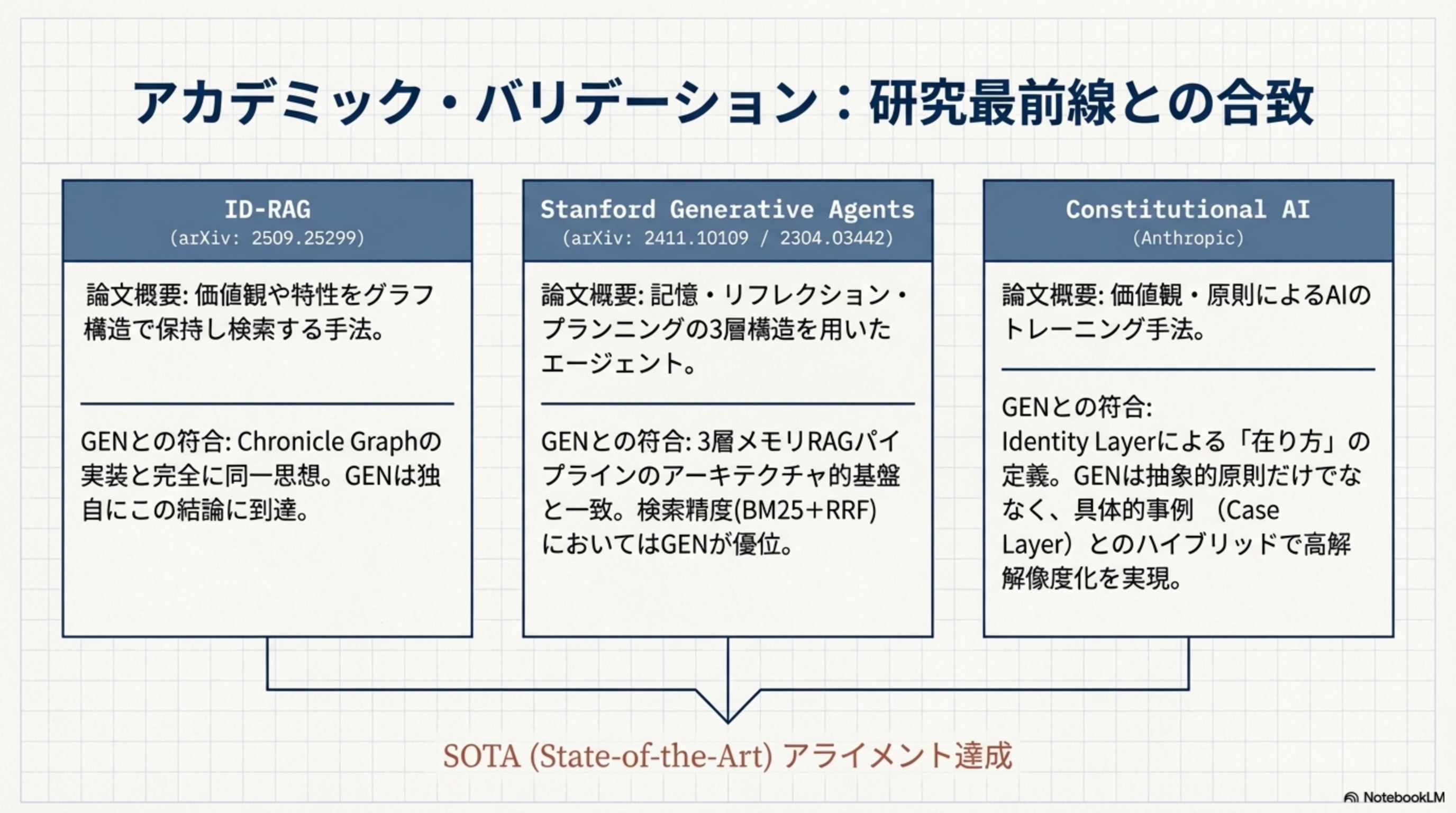
| 研究 | 論文概要 | GENとの符合 |
|---|---|---|
| ID-RAG arXiv: 2509.25299 |
価値観や特性をグラフ構造で保持し検索する手法 | Chronicle Graphの実装と完全に同一思想。GENは独自にこの結論に到達 |
| Stanford Generative Agents arXiv: 2411.10109 / 2304.03442 |
記憶・リフレクション・プランニングの3層構造を用いたエージェント | 3層メモリRAGパイプラインのアーキテクチャ的基盤と一致。検索精度(BM25+RRF)においてはGENが優位 |
| Constitutional AI Anthropic |
価値観・原則によるAIのトレーニング手法 | Identity Layerによる「在り方」の定義。GENは抽象的原則だけでなく、具体的事例(Case Layer)とのハイブリッドで高解像度化を実現 |
Project GENは独立した設計でありながら、ID-RAG、Stanford Generative Agents、Constitutional AIの3つの研究最前線と同じ思想的結論に到達しています。これは設計の妥当性を学術的に裏付けるものです。
まとめ
- What → Why/How のシフト - 「何を言うか」ではなく「なぜそう関わるか」を再現。セッション対話録に対象者の関わり方が自然に内包されている
- 3層メモリRAG - エピソード記憶(Case Layer)+ セマンティック記憶(Chronicle Graph)+ 自己モデル(Identity Layer)の統合
- Chronicle Graph - エッジ(関係性)をベクトル検索可能にした、人格固定装置としてのナレッジグラフ
- 2コレクション戦略 - gen_chunks(網羅性)と gen_chunks_hi(人格純度)の両立
- 在り方.md - 全体精度を決定する最重要ドキュメント。LLM半自動 + 人手最終確認
- SOTA アライメント - ID-RAG、Stanford Generative Agents、Constitutional AIと独立して同一結論に到達
元のスライド一覧
クリックで拡大表示できます