はじめに:「考える」から「働く」へ
生成AIは2017年のTransformer登場以来、驚異的な速度で進化してきました。しかし、その進化は単なるモデルの巨大化ではありません。「考える(Think)」→「行動する(Act)」→「働く(Work)」という、能力の質的な変化を辿っています。
この章では、基盤技術の誕生からAGI(汎用人工知能)への到達までを8つのフェーズに分解し、各フェーズで何が起き、何が可能になったかを体系的に解説します。

- 8つのフェーズで構成されるAGIへのマスタープラン
- Phase 1-3:考える(Think) - 基盤技術、ツール拡張、専門化
- Phase 4-5:行動する(Act) - エージェント化、組織化
- Phase 6-8:働く(Work) - 推論強化、長期自律行動、身体性獲得
- AGI到達を支える4つの柱と、識者たちの見解
- データ還流ループ:AGIを駆動する隠れたエンジン
知能拡張のマスタープラン
8つのフェーズは、3つの大きなカテゴリ — 考える(Think)、行動する(Act)、働く(Work) — に分類されます。
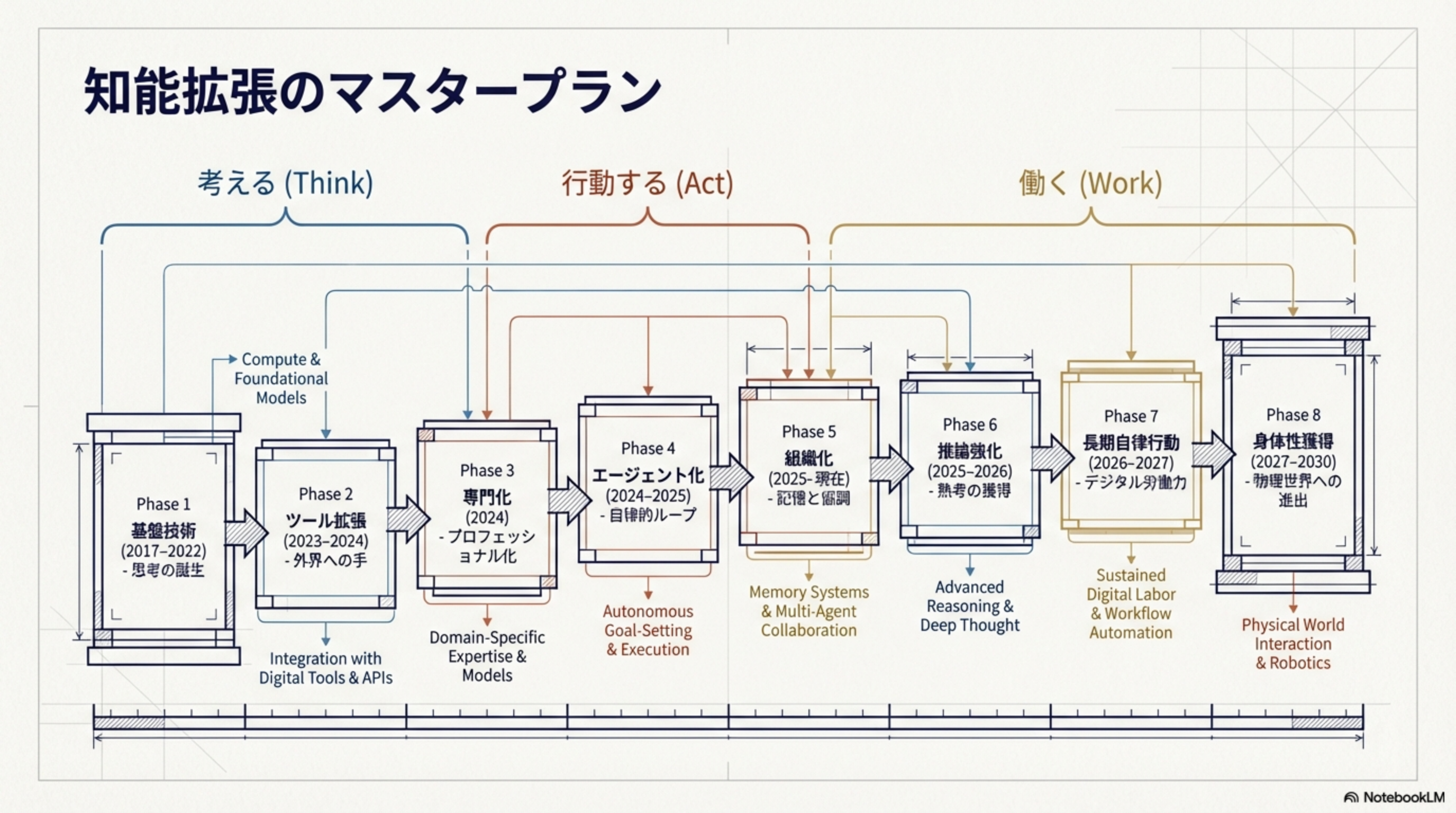
| カテゴリ | Phase | 名称 | 時期 | キーワード |
|---|---|---|---|---|
| 考える (Think) |
1 | 基盤技術 | 2017-2022 | 思考の誕生 |
| 2 | ツール拡張 | 2023-2024 | 外界への手 | |
| 3 | 専門化 | 2024 | プロフェッショナル化 | |
| 行動する (Act) |
4 | エージェント化 | 2024-2025 | 自律的ループ |
| 5 | 組織化 | 2025-現在 | 記憶と協調 | |
| 働く (Work) |
6 | 推論強化 | 2025-2026 | 熟考の獲得 |
| 7 | 長期自律行動 | 2026-2027 | デジタル労働力 | |
| 8 | 身体性獲得 | 2027-2030 | 物理世界への進出 |
Phase 1:「考える」機能のモジュール化(2017-2022)
RNN/LSTMの「順番に読む」方式から、Transformerの「全トークンを同時に見比べる」方式への革命的な転換が起きました。
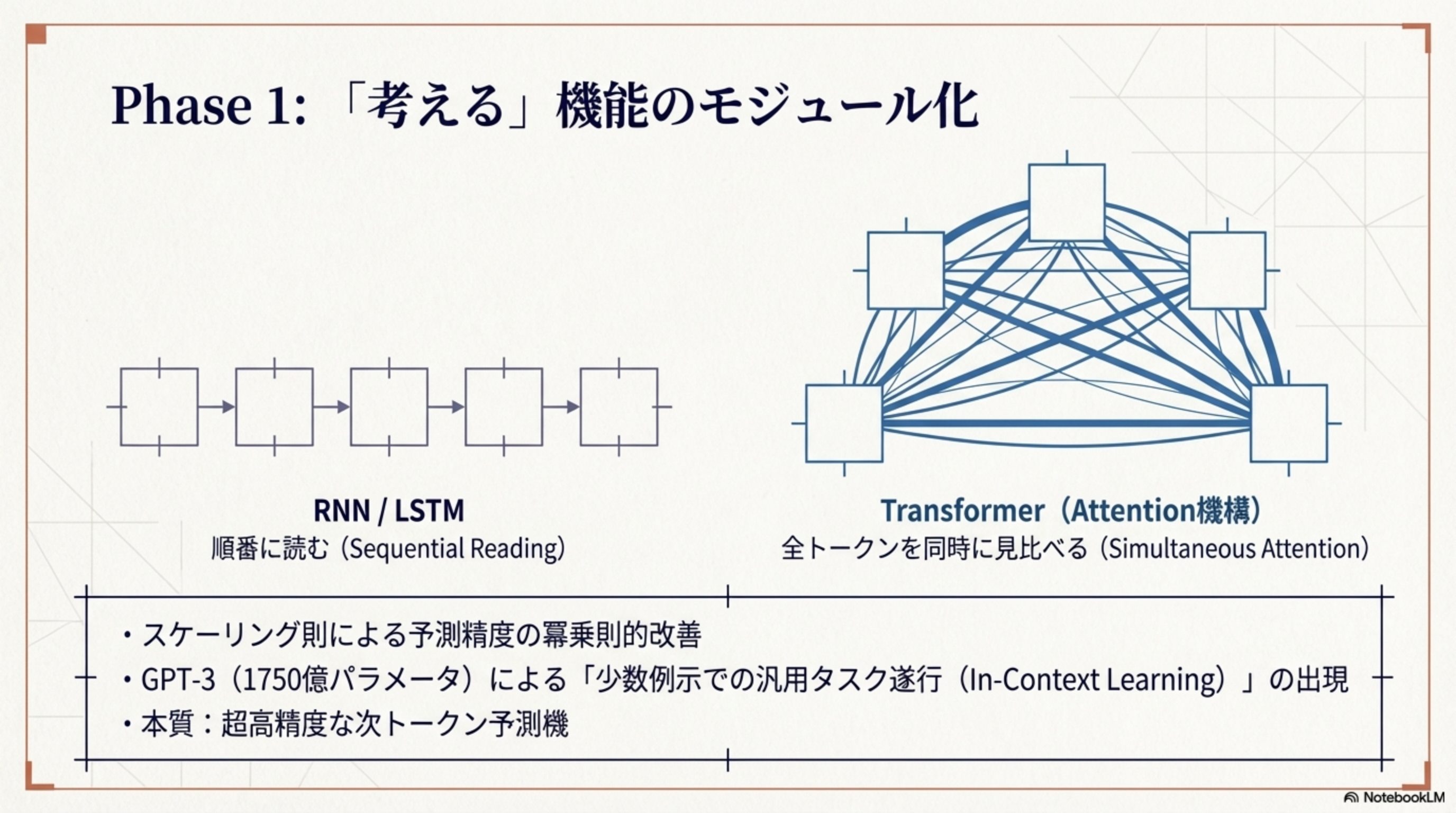
- スケーリング則による予測精度の冪乗則的改善
- GPT-3(1750億パラメータ)による「少数例示での汎用タスク遂行(In-Context Learning)」の出現
- 本質:超高精度な次トークン予測機
Phase 2:外界へ接続する「手」の獲得(2023-2024)
LLM(頭脳)が外部API(外界)と直接接続する手段を獲得しました。Bashターミナルのラッパーではなく、JSON構造化によるプロトコル標準化です。
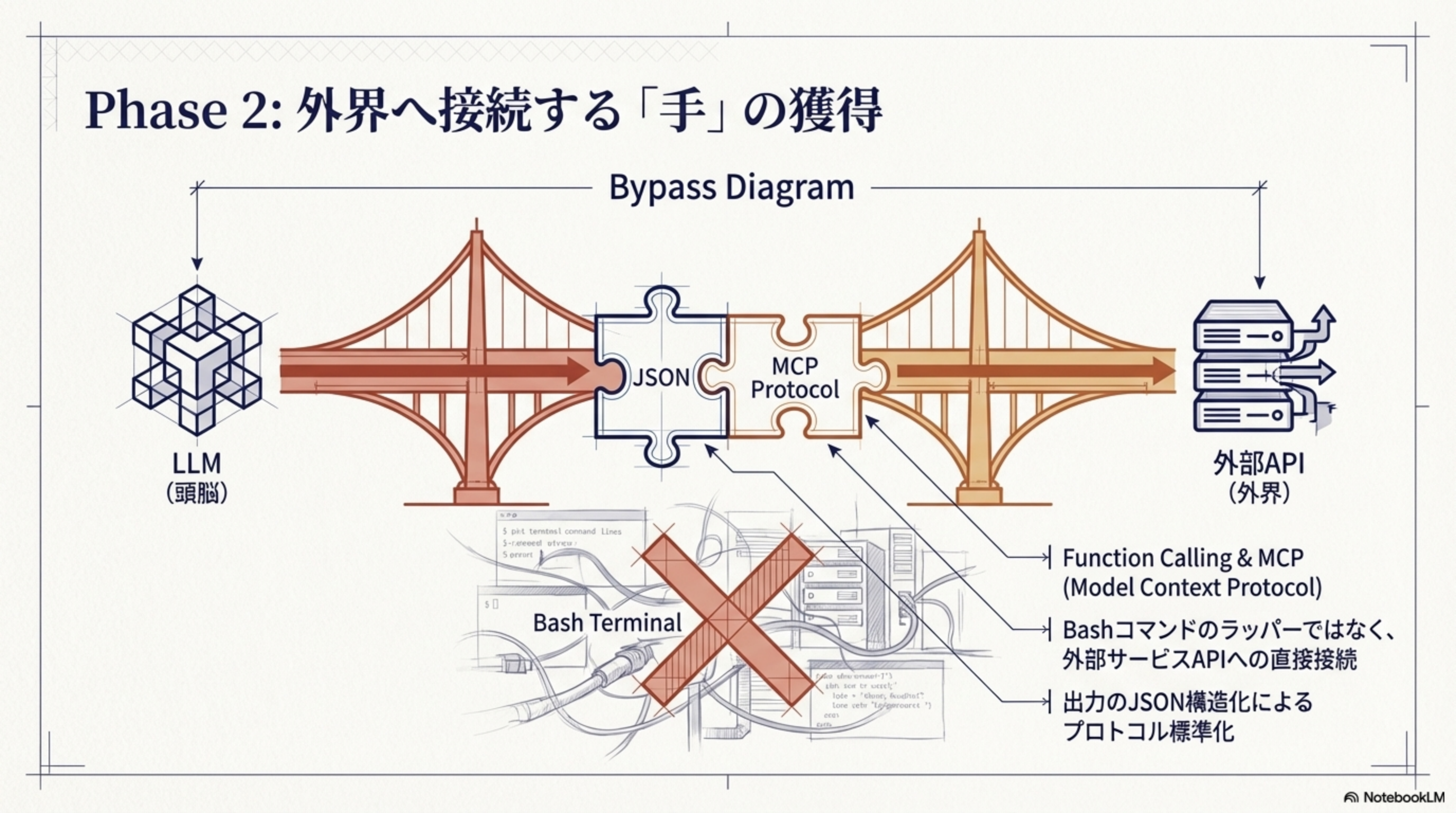
- Function Calling:LLMがJSON形式で関数呼び出しを構造的に出力
- MCP(Model Context Protocol):Anthropicが提唱する「何でも繋がるUSBC」のような接続規格
- Bashコマンドのラッパーではなく、外部サービスAPIへの直接接続
Phase 3:条件付き確率のプロフェッショナル化(2024)
「context」を戦略的に制御することで、同一のモデルを全く異なる専門家に変換する数学的プロセスです。
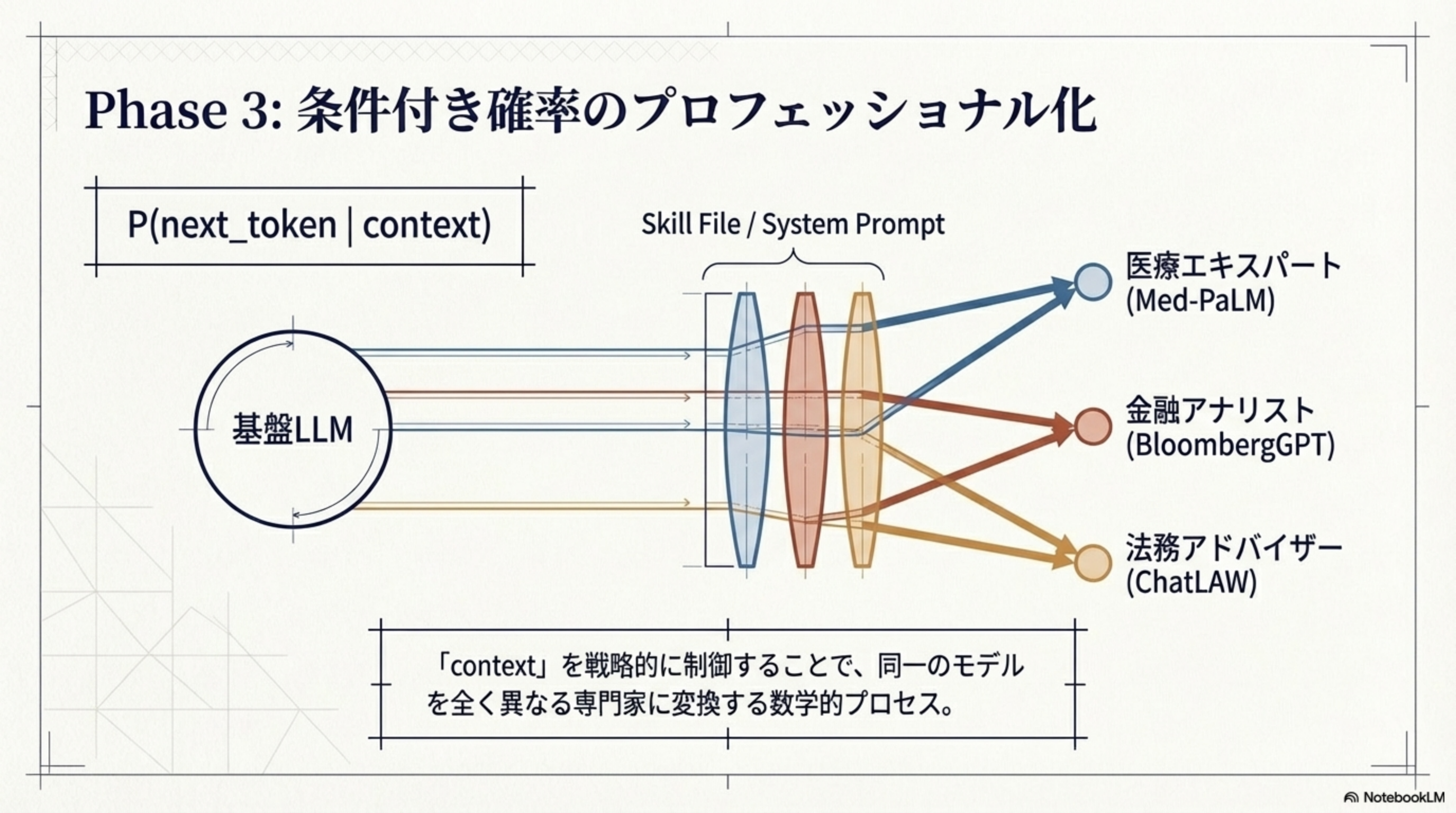
P(next_token | context) の「context」部分を変えるだけで、同じ基盤LLMが医療エキスパート(Med-PaLM)、金融アナリスト(BloombergGPT)、法務アドバイザー(ChatLAW)として振る舞えるようになります。Skill FileやSystem Promptは、この「context」を戦略的に設定するための装置です。
Phase 4:イベントループによる自律的タスク遂行(2024-2025)
一問一答から脱却し、観察(Observe)→ 思考(Think)→ 行動(Act)の自律的サイクルが確立されました。
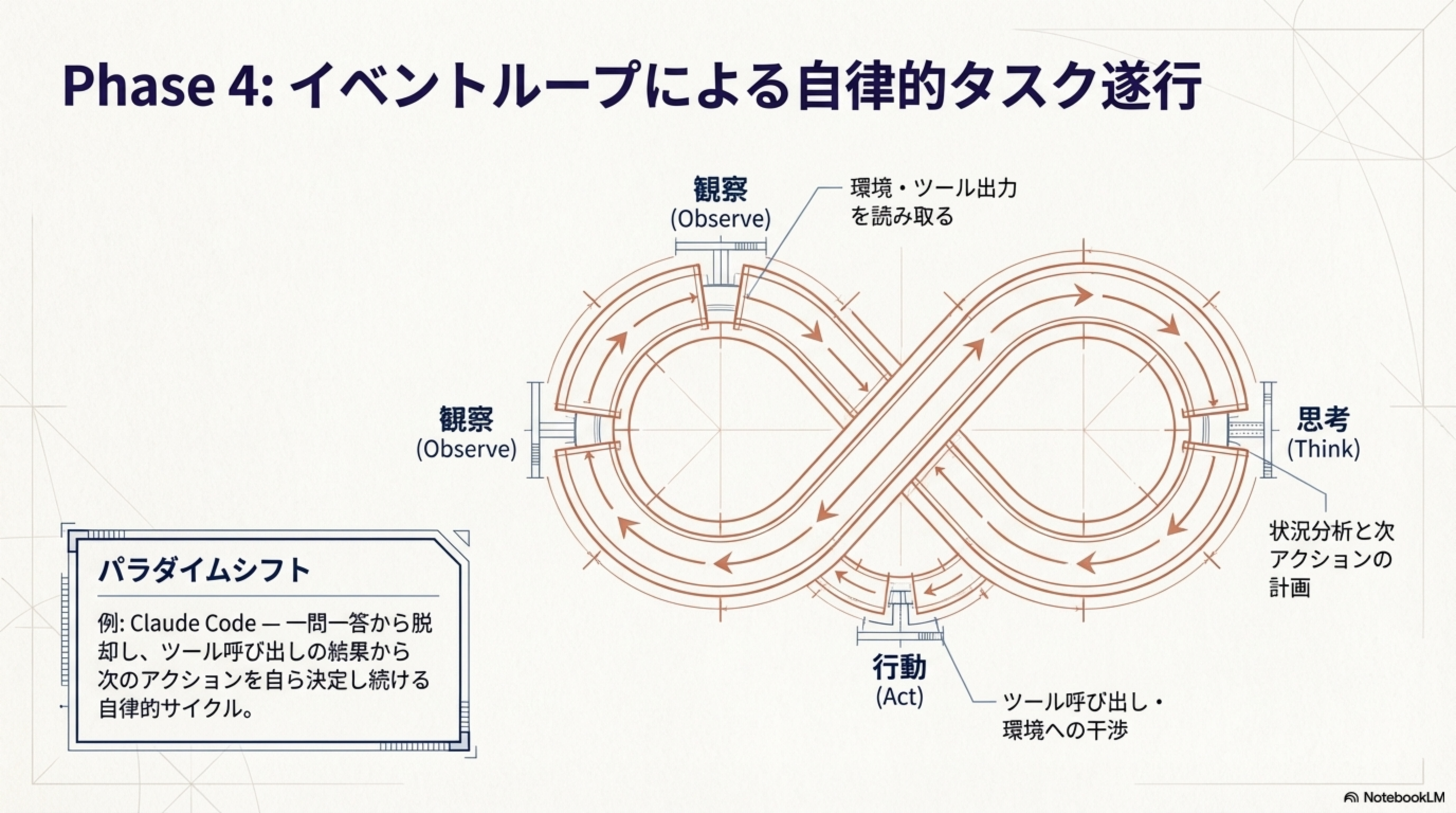
例:Claude Code — 一問一答から脱却し、ツール呼び出しの結果から次のアクションを自ら決定し続ける自律的サイクル。環境・ツール出力を読み取り(Observe)、状況分析と次アクションの計画を立て(Think)、ツール呼び出し・環境への干渉を行う(Act)。このループがタスク完了まで自動的に回り続けるのがエージェントの本質です。
Phase 5:「個」から「組織」への拡張(2025-現在)
単体エージェントの限界を超え、複数エージェントが階層的に協調する組織構造が出現しました。
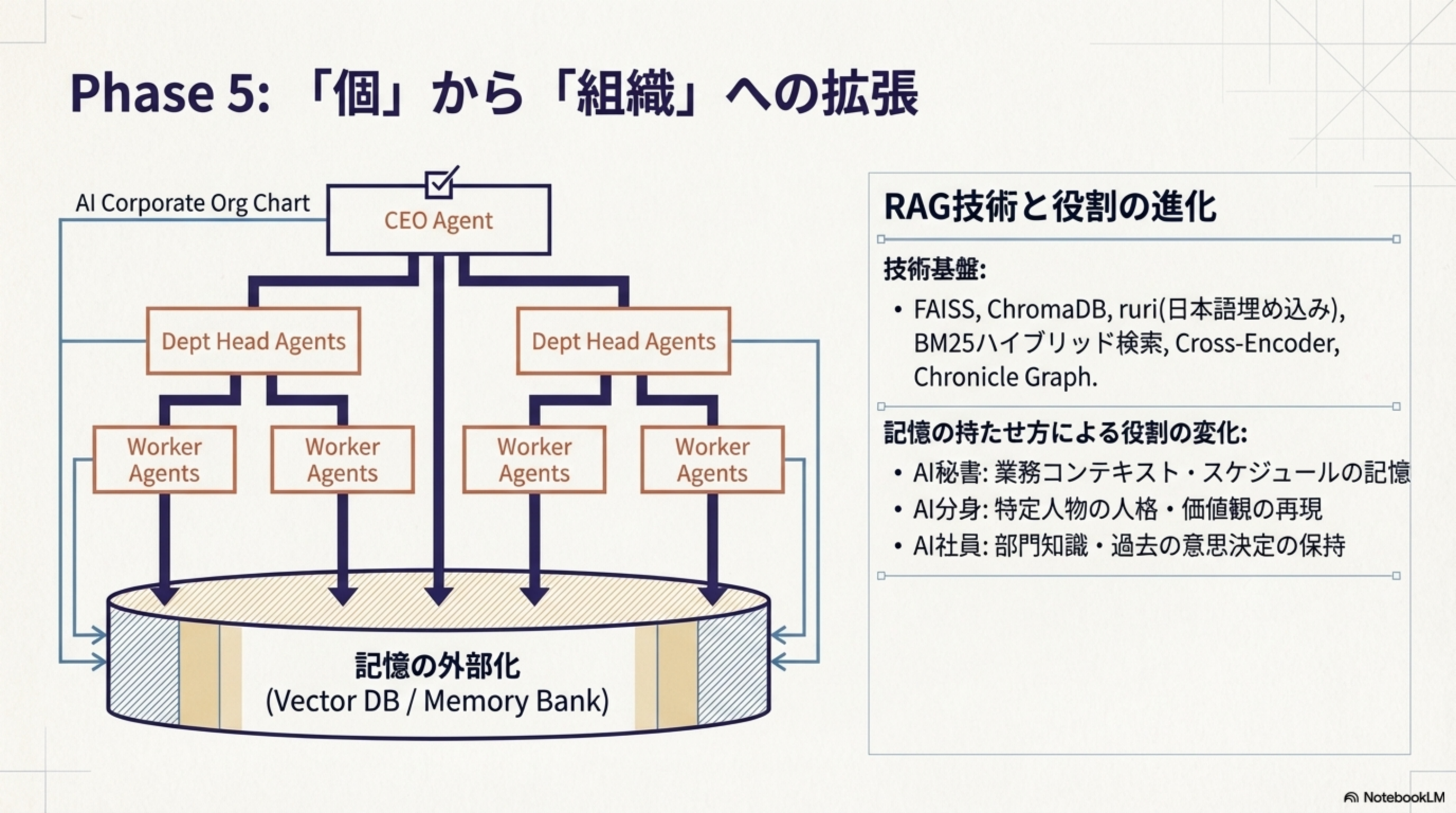
AI組織図
CEO Agent → Dept Head Agents → Worker Agents の階層構造。全エージェントが記憶の外部化(Vector DB / Memory Bank)を共有し、組織的に協調します。
RAG技術と役割の進化
- 技術基盤:FAISS, ChromaDB, ruri, BM25, Cross-Encoder, Chronicle Graph
- AI秘書:業務コンテキスト・スケジュールの記憶
- AI分身:特定人物の人格・価値観の再現
- AI社員:部門知識・過去の意思決定の保持
能力シフト・マトリクス:パラダイムの変遷

| 観点 | Phase 1: 基盤モデル | Phase 4: 自律エージェント | Phase 5: 組織化AI |
|---|---|---|---|
| 主な役割 | 高精度な次トークン予測 | 自律的なタスク実行者 | 協調するデジタル労働力 |
| コンテキスト | セッション内のみ | ループ中の作業記憶 | RAGによる永続的外部記憶 |
| 外部アクセス | なし(閉鎖系) | MCPを通じたAPI操作 | 組織間システムとの統合 |
| 動作モデル | 一問一答(Q&A) | イベントループ(Observe-Think-Act) | 分業・協調・自己検証 |
Phase 6:推論時のスケーリングとRLVR(2025-2026)
計算リソースの投入先が「訓練時」から「回答生成時(推論時)」へとシフトしています。
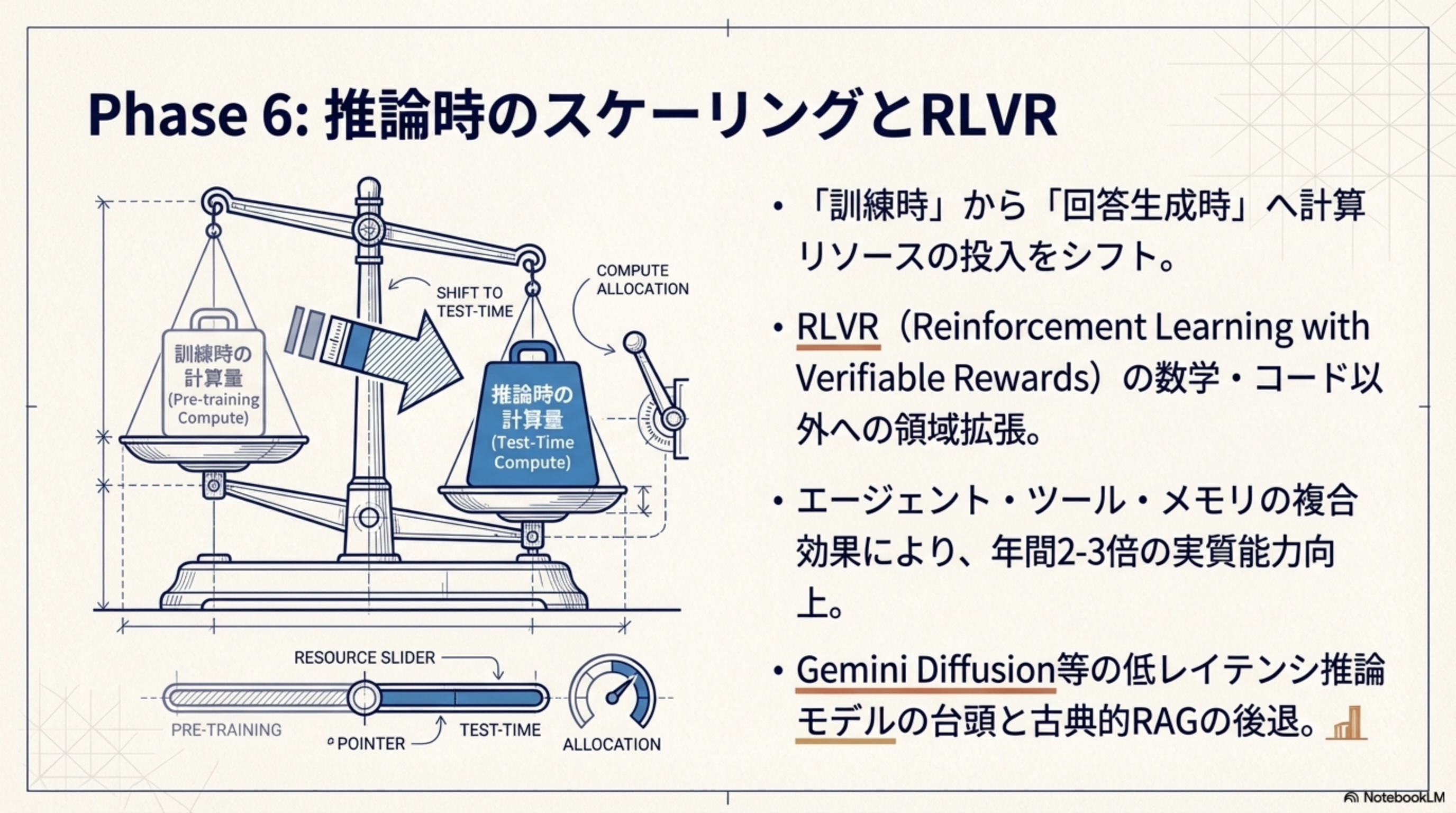
- 「訓練時」から「回答生成時」へ計算リソースの投入をシフト
- RLVR(Reinforcement Learning with Verifiable Rewards)の数学・コード以外への領域拡張
- エージェント・ツール・メモリの複合効果により、年間2-3倍の実質能力向上
- Gemini Diffusion等の低レイテンシ推論モデルの台頭と古典的RAGの後退
Phase 7:長期自律行動と継続学習(2026-2027)
不可欠な飛躍:「継続学習(Continual Learning)」 — 訓練とデプロイの境界が消失します。
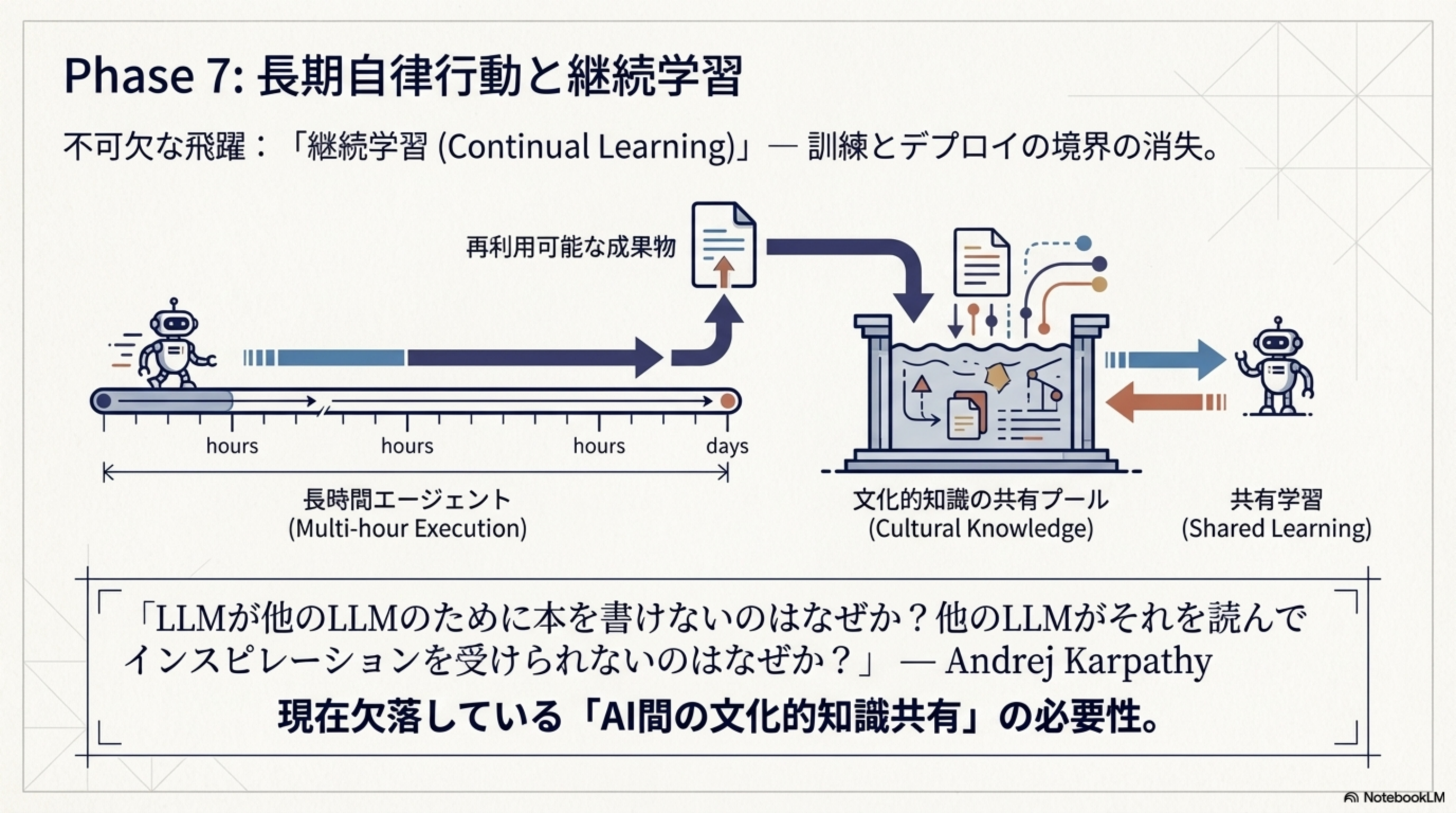
「LLMが他のLLMのために本を書けないのはなぜか?他のLLMがそれを読んでインスピレーションを受けられないのはなぜか?」— 現在欠落している「AI間の文化的知識共有」の必要性を指摘しています。長時間エージェントが生み出した再利用可能な成果物を、文化的知識の共有プールに蓄積し、他のエージェントが学習する。この循環こそがPhase 7の核心です。
Phase 8:身体性獲得 — Physical AI(2027-2030)
デジタル空間から物理世界での適応的行動へのパラダイムシフトです。
- LWM(Large World Models):物理世界のシミュレーションモデル
- VLA(Visual-Language-Action)Models:視覚・言語・行動を統合した基盤モデル
- ロボティクス基盤モデル
現在は「Stumbling Agent(つまずくエージェント)」フェーズ。非構造化環境での試行錯誤が進行中です。デジタル空間での自律性はPhase 4-5で確立されましたが、物理世界での信頼性の高い行動はまだ研究段階にあります。
AGI到達を支える4つの柱
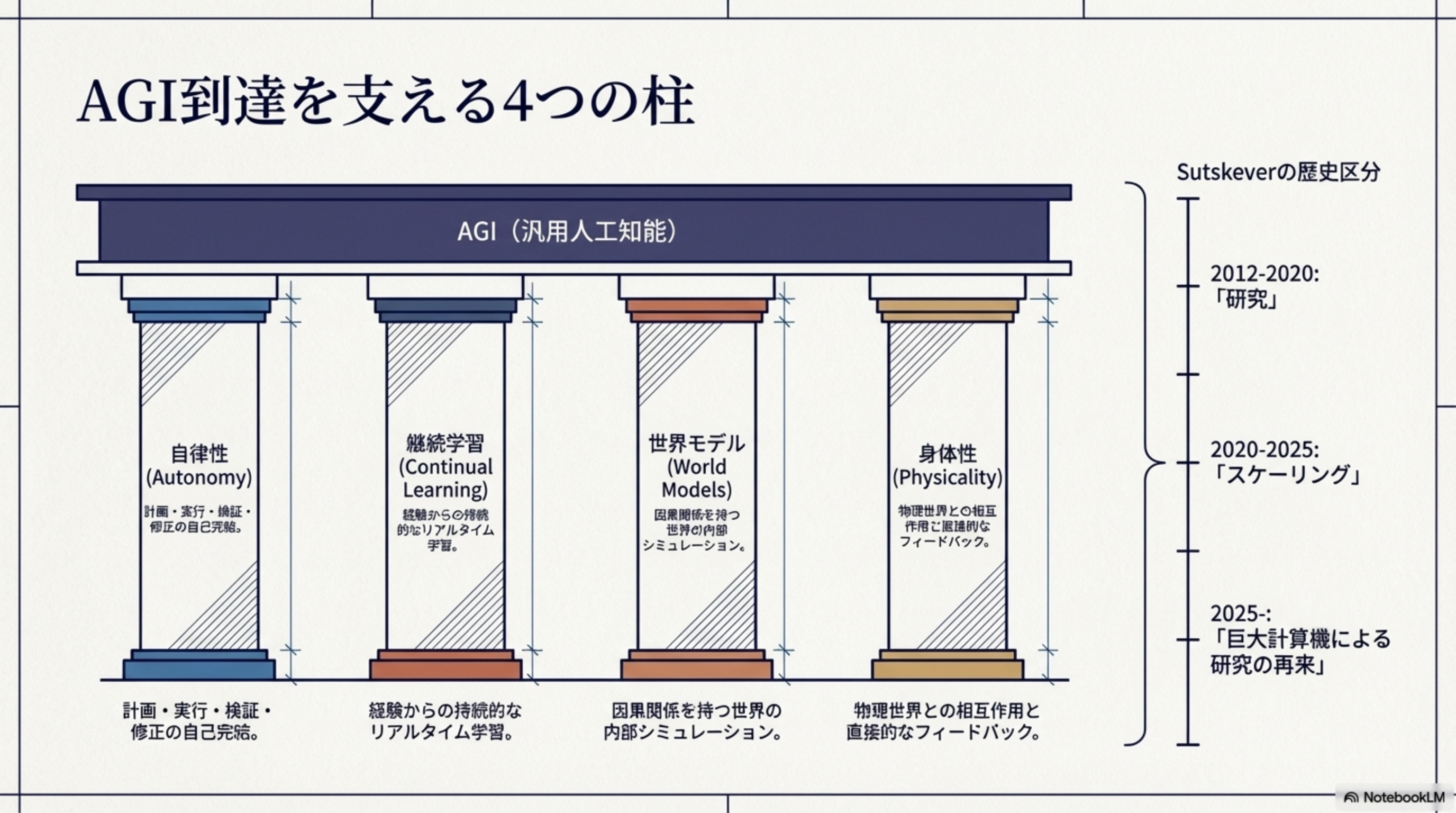
| 柱 | 概要 |
|---|---|
| 自律性(Autonomy) | 計画・実行・検証・修正の自己完結。Phase 4-5で確立されたエージェントループが土台 |
| 継続学習(Continual Learning) | 経験からの持続的なリアルタイム学習。訓練とデプロイの境界が消失する |
| 世界モデル(World Models) | 因果関係を持つ世界の内部シミュレーション。物理法則の理解 |
| 身体性(Physicality) | 物理世界との相互作用と直接的なフィードバック。ロボティクスとの融合 |
AGIへの道程:識者たちの見解
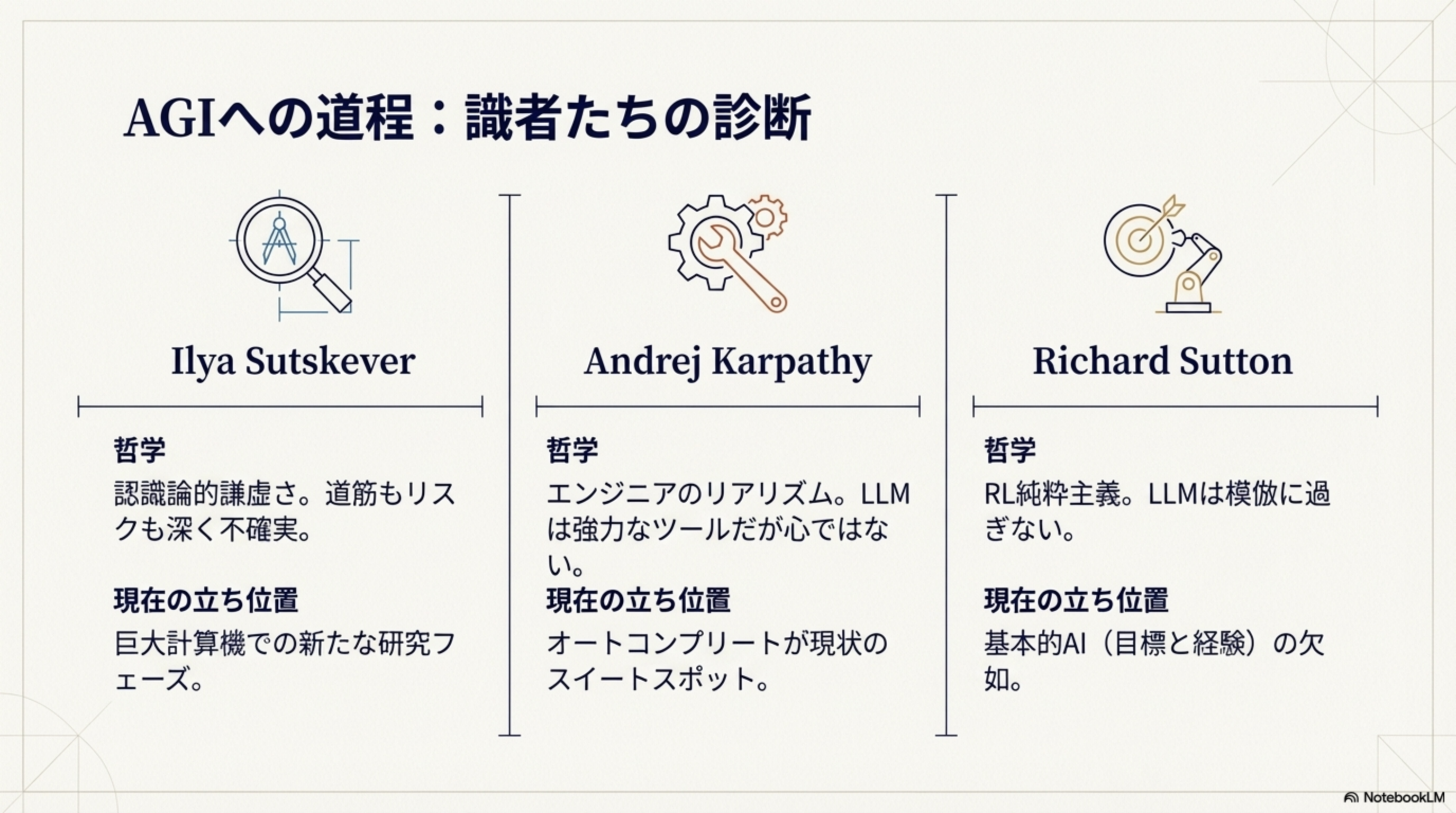
| 識者 | 哲学 | 現在の立ち位置 |
|---|---|---|
| Ilya Sutskever | 認識論的謙虚さ。道筋もリスクも深く不確実 | 巨大計算機での新たな研究フェーズ |
| Andrej Karpathy | エンジニアのリアリズム。LLMは強力なツールだが心ではない | オートコンプリートが現状のスイートスポット |
| Richard Sutton | RL純粋主義。LLMは模倣に過ぎない | 基本的AI(目標と経験)の欠如 |
データ還流ループ:AGIを駆動する隠れたエンジン
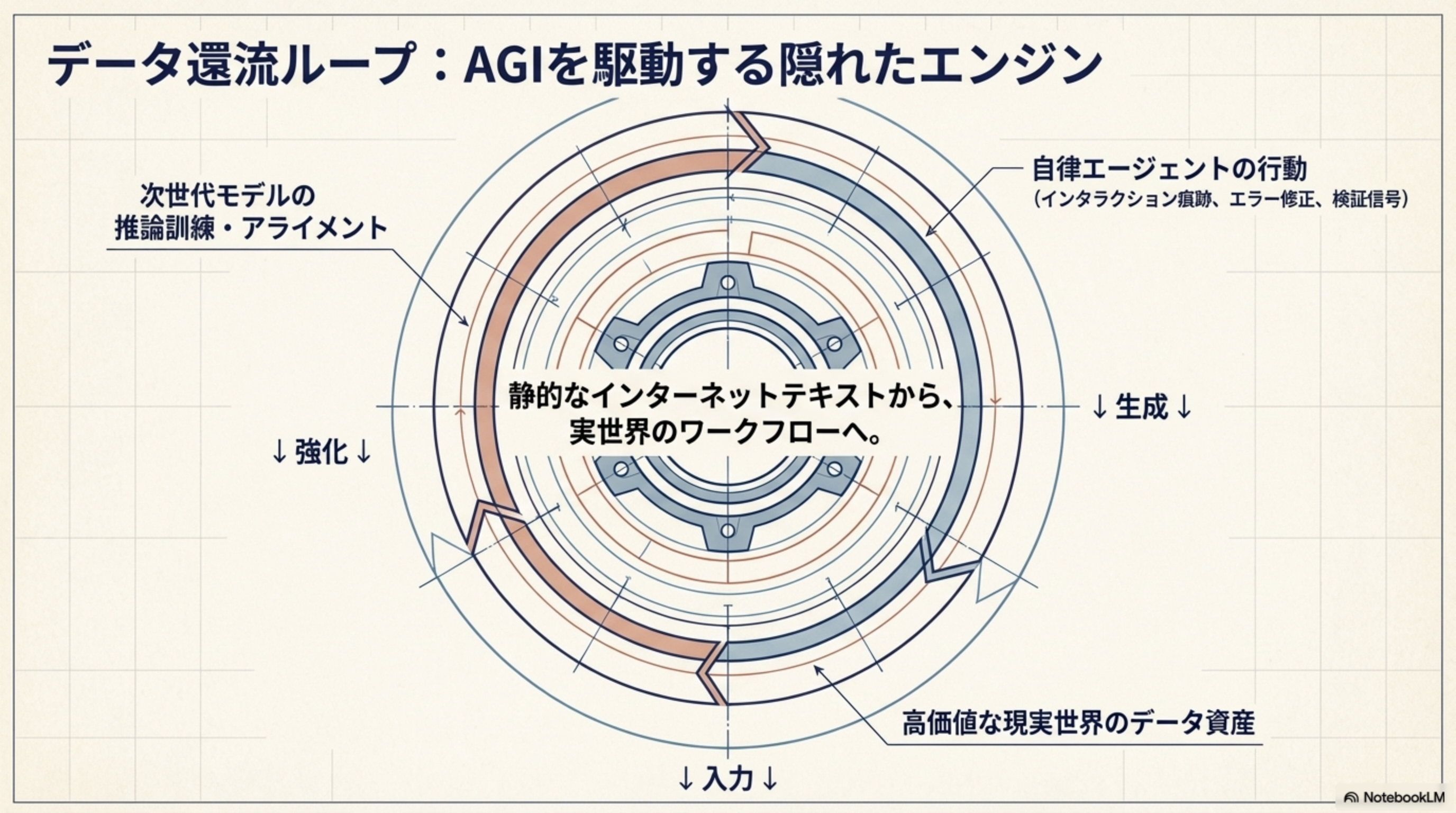
自律エージェントの行動(インタラクション痕跡、エラー修正、検証信号)が高価値な現実世界のデータ資産を生み出し、それが次世代モデルの推論訓練・アライメントに活用される。静的なインターネットテキストから、実世界のワークフローへ。このデータ還流ループこそが、AGIを駆動する隠れたエンジンです。
まとめ:進化の終着点は、単一のブレイクスルーではない
- AIは「チャット」から「推論」へ、そして「持続的作業」への第3の変曲点に到達した
- AGIへの道は、巨大モデルの一本道ではない
- アーキテクチャ、データ、計算資源、そしてツール呼び出しが複雑に絡み合い、同時に進化する複合的なエコシステムそのもの
元のスライド一覧
クリックで拡大表示できます