はじめに:LLMの心臓部を解剖する
ChatGPTやClaudeが文章を生成できるのは、その内部でトランスフォーマーというアーキテクチャが動いているからです。その心臓部にあるのがアテンション・メカニズム — 「どの単語に注目すべきか」を計算する仕組みです。
この章では、入力テキストがトークンに分割され、ベクトルに変換され、Query・Key・Valueという3つのストリームに分岐し、アテンション計算を経て、最終的に「次の単語」が予測されるまでの全工程を、1ステップずつ解剖します。

- Phase 1:意味の座標化(Tokenization & Embedding)
- Phase 2:空間の指紋(Positional Encoding)
- Phase 3:Q, K, Vの誕生(3つの並列ストリーム)
- Phase 4:文脈のミキシング(Attention Calculation)
- Phase 5:推論の高速化(KV Cache Mechanism)
- Phase 6:確率への昇華(Output Generation)
データが辿る軌跡:トークンから予測までの全工程
まず全体像を掴みましょう。入力テキストが最終的に「次のトークン」として出力されるまでに、5つのフェーズを通過します。
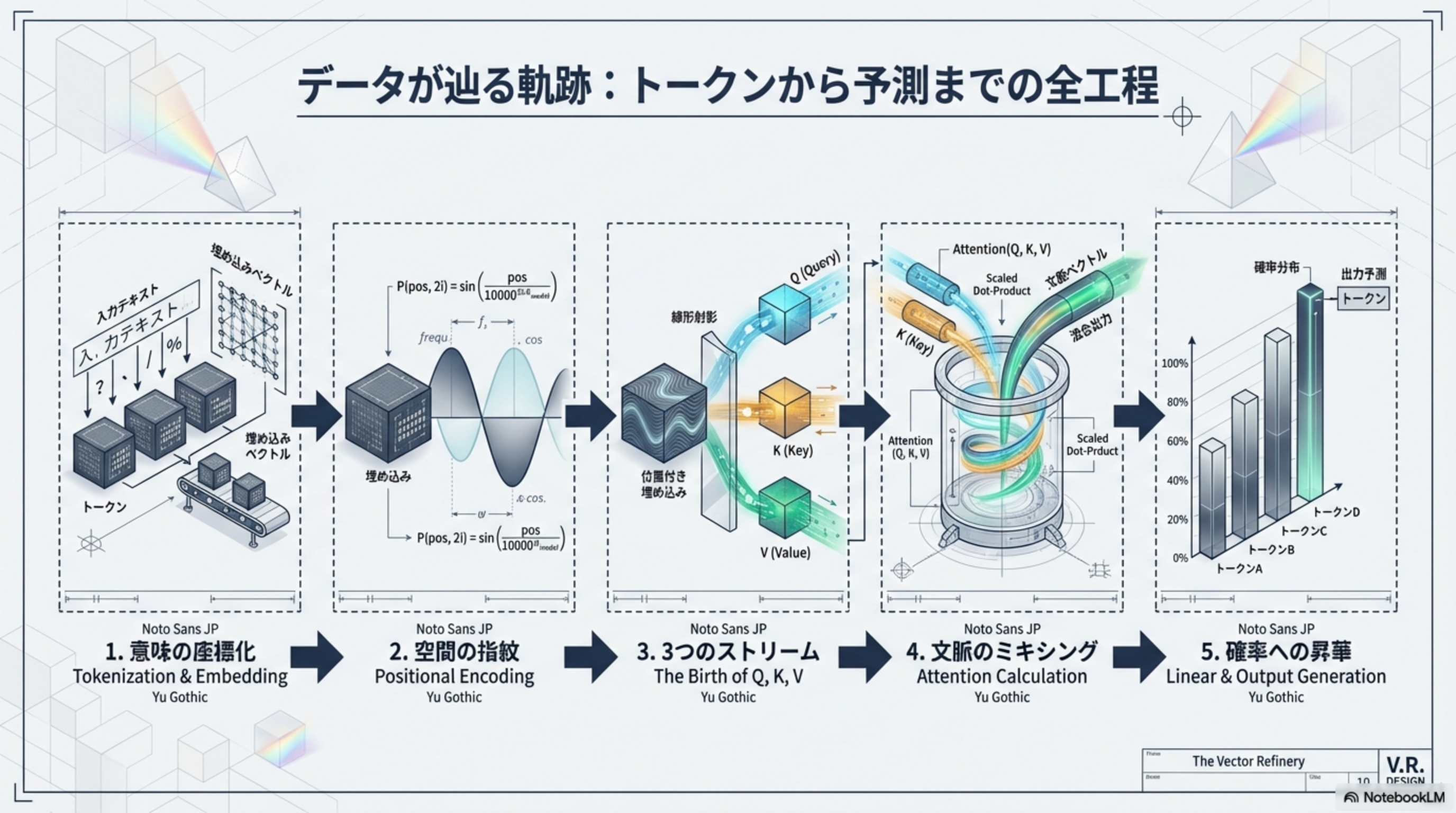
| フェーズ | 日本語名 | 英語名 | 概要 |
|---|---|---|---|
| 1 | 意味の座標化 | Tokenization & Embedding | テキストをトークンに切り出し、高次元ベクトルにマッピング |
| 2 | 空間の指紋 | Positional Encoding | 語順を持たないベクトルに、波長を合成して絶対位置を付与 |
| 3 | 3つのストリーム | The Birth of Q, K, V | 1つのベクトルが学習済み重み行列を通過し、3つに分岐 |
| 4 | 文脈のミキシング | Attention Calculation | Q×K内積 → スケーリング → Softmax → V加重平均 |
| 5 | 確率への昇華 | Linear & Output Generation | 文脈ベクトルを辞書サイズに拡張し、確率分布へ変換 |
Phase 1:意味の座標化(Tokenization & Embedding)
テキストは切り出され、高次元の空間座標にマッピングされます。
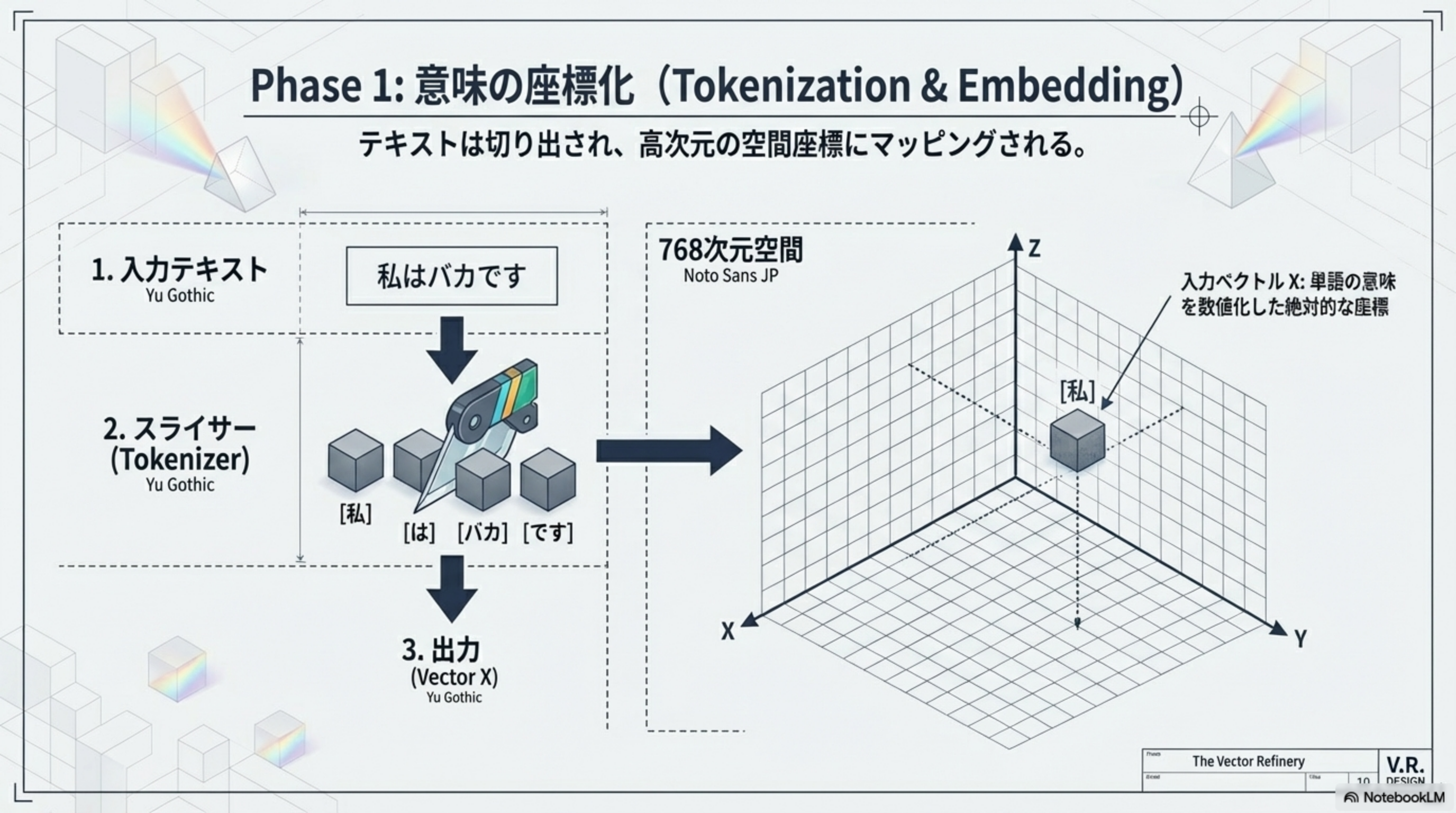
- 入力テキスト:「私はバカです」
- スライサー(Tokenizer):[私] [は] [バカ] [です] の4つのトークンに切り出し
- 出力(Vector X):各トークンが768次元空間上の座標(入力ベクトル X)に変換される
入力ベクトル X は単語の意味を数値化した絶対的な座標です。この段階ではまだ「どの位置にあるか」の情報は含まれていません。意味だけが空間上にマッピングされた状態です。
Phase 2:空間の指紋を刻む(Positional Encoding)
語順を持たない並列ベクトルに、波長を合成して絶対位置を付与します。
トランスフォーマーは全トークンを並列に処理するため、そのままでは「犬が猫を追いかけた」と「猫が犬を追いかけた」の区別がつきません。sin/cos波を使った周波数ミキサー(Frequency Mixer)が、各トークンに唯一無二の「空間の指紋」を刻み込みます。複数の波が組み合わさることで、360度ループしても絶対に重複しない座標が完成します。
Phase 3:Q, K, Vの誕生(3つの並列ストリーム)
1つの入力ベクトルが、学習済みの重み行列を通過し、役割の異なる3つのベクトルに分岐します。
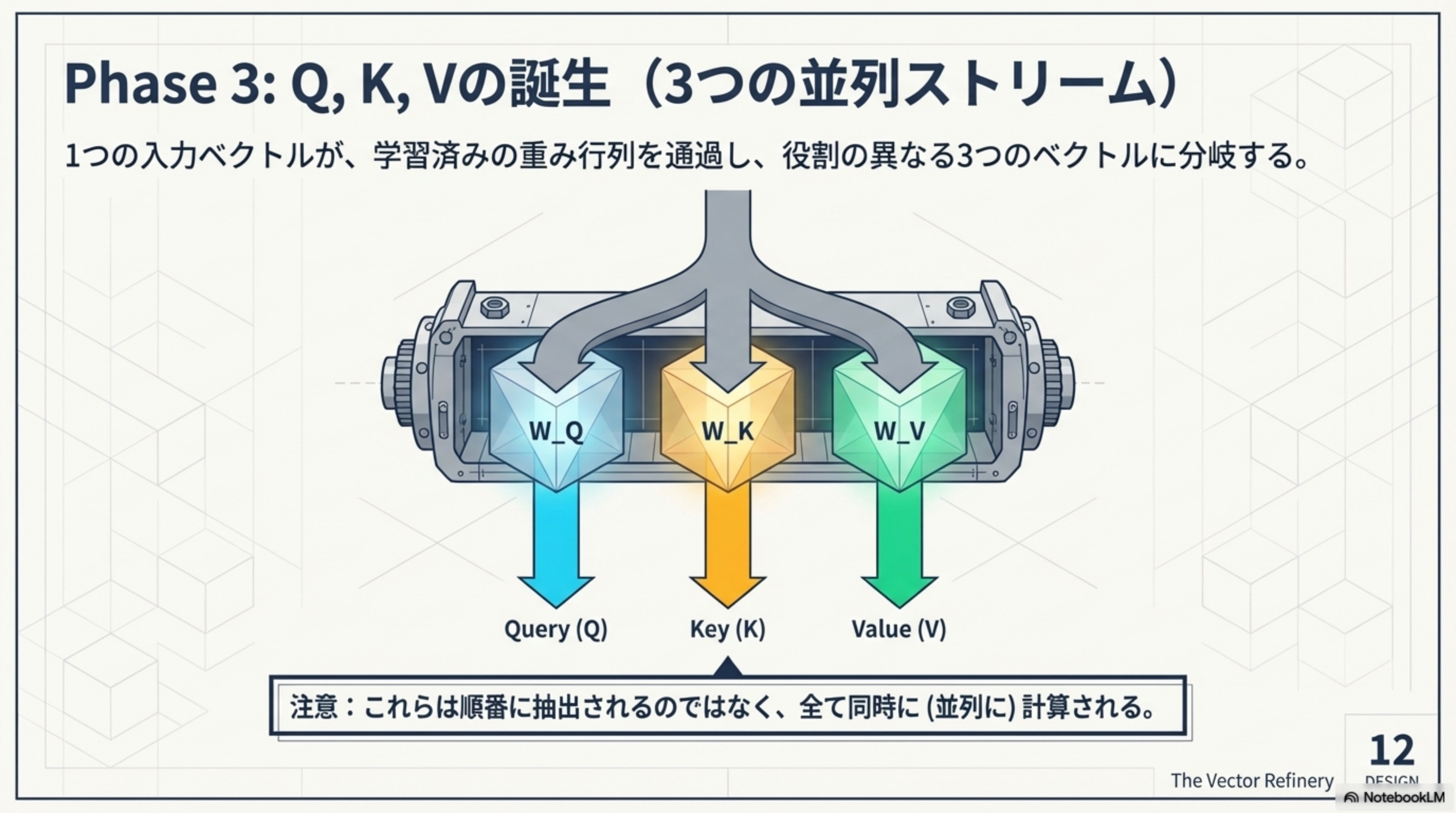
Q, K, V は順番に抽出されるのではなく、全て同時に(並列に)計算されます。
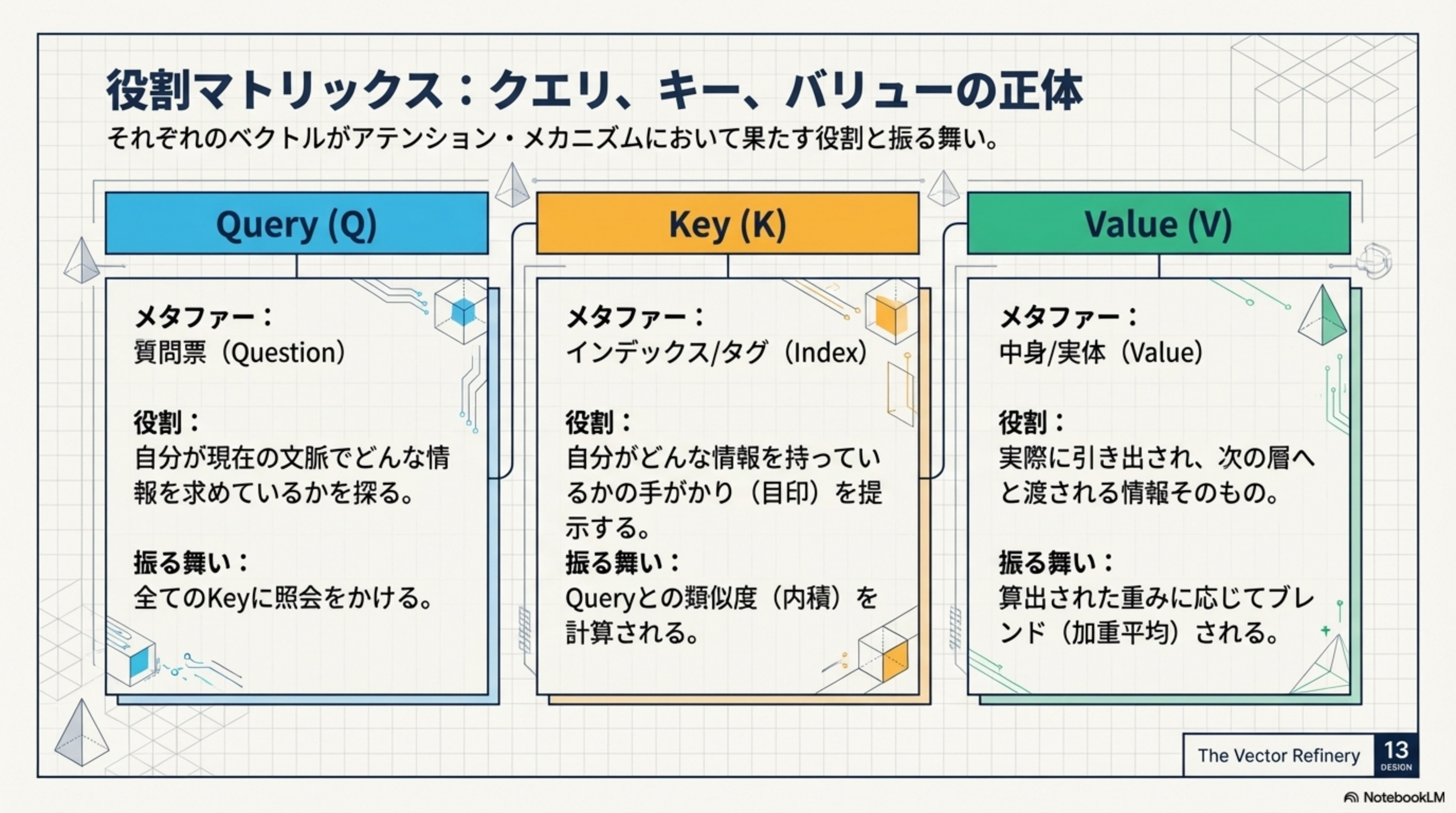
| ベクトル | メタファー | 役割 | 振る舞い |
|---|---|---|---|
| Query (Q) | 質問票 | 自分が現在の文脈でどんな情報を求めているかを探る | 全てのKeyに照会をかける |
| Key (K) | インデックス/タグ | 自分がどんな情報を持っているかの手がかり(目印)を提示する | Queryとの類似度(内積)を計算される |
| Value (V) | 中身/実体 | 実際に引き出され、次の層へと渡される情報そのもの | 算出された重みに応じてブレンド(加重平均)される |
- Query = 「AIの歴史について知りたい」という質問
- Key = 各本の背表紙に書かれたタイトルやタグ(「AI」「歴史」「機械学習」...)
- Value = 本の中身そのもの。Queryと最もマッチしたKeyの本から、中身(Value)が取り出される
Phase 4:文脈のミキシング(Attention Calculation)
アテンション計算は3つのサブステップで構成されています。これがトランスフォーマーの最も核心的な処理です。
Phase 4-1:関連度のマッチング(Q × KT 内積)
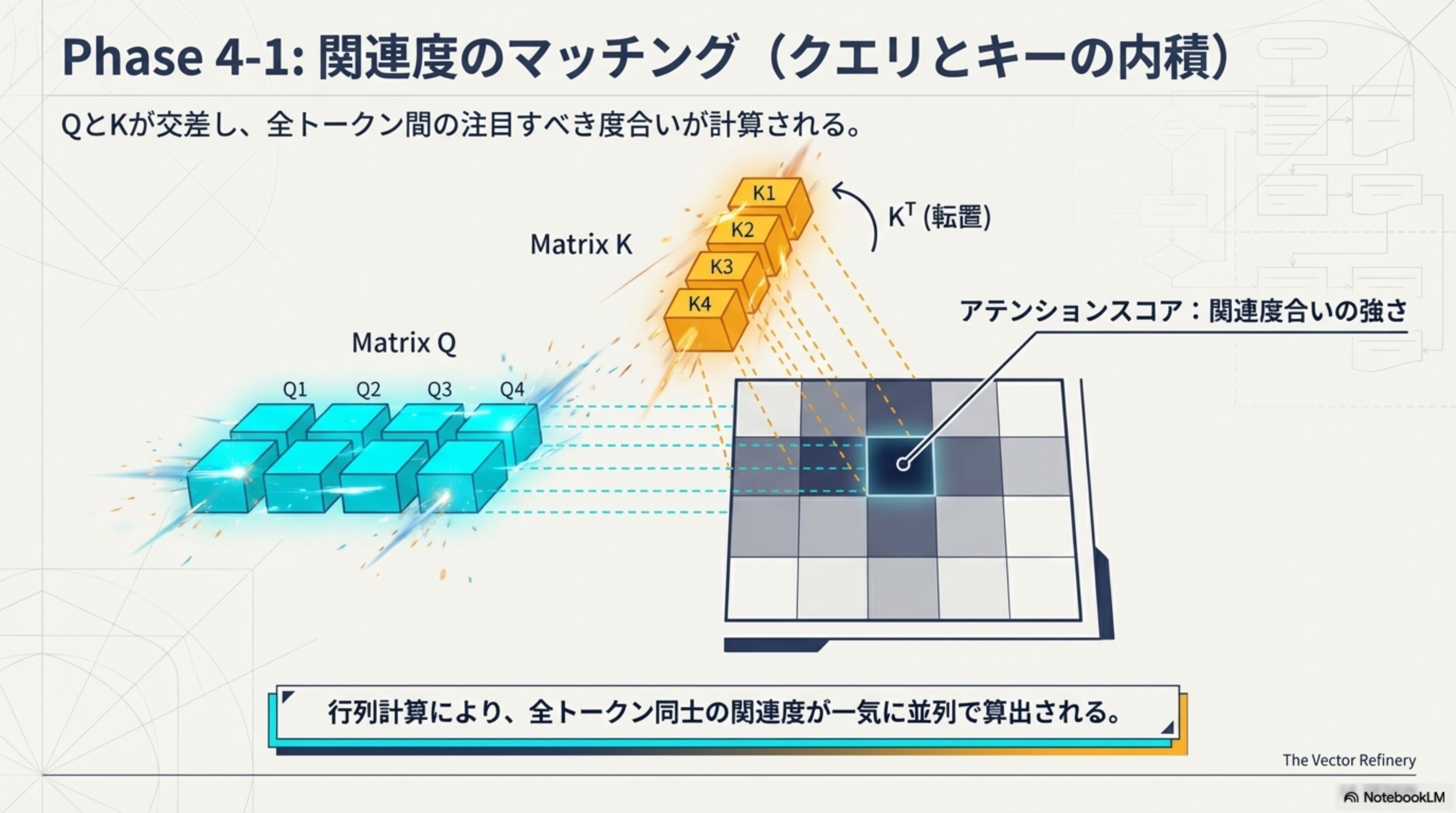
QとKが交差し、全トークン間の「注目すべき度合い」が計算されます。行列計算により、全トークン同士の関連度が一気に並列で算出されます。
Phase 4-2:スコアの正規化(Scaling & Softmax)
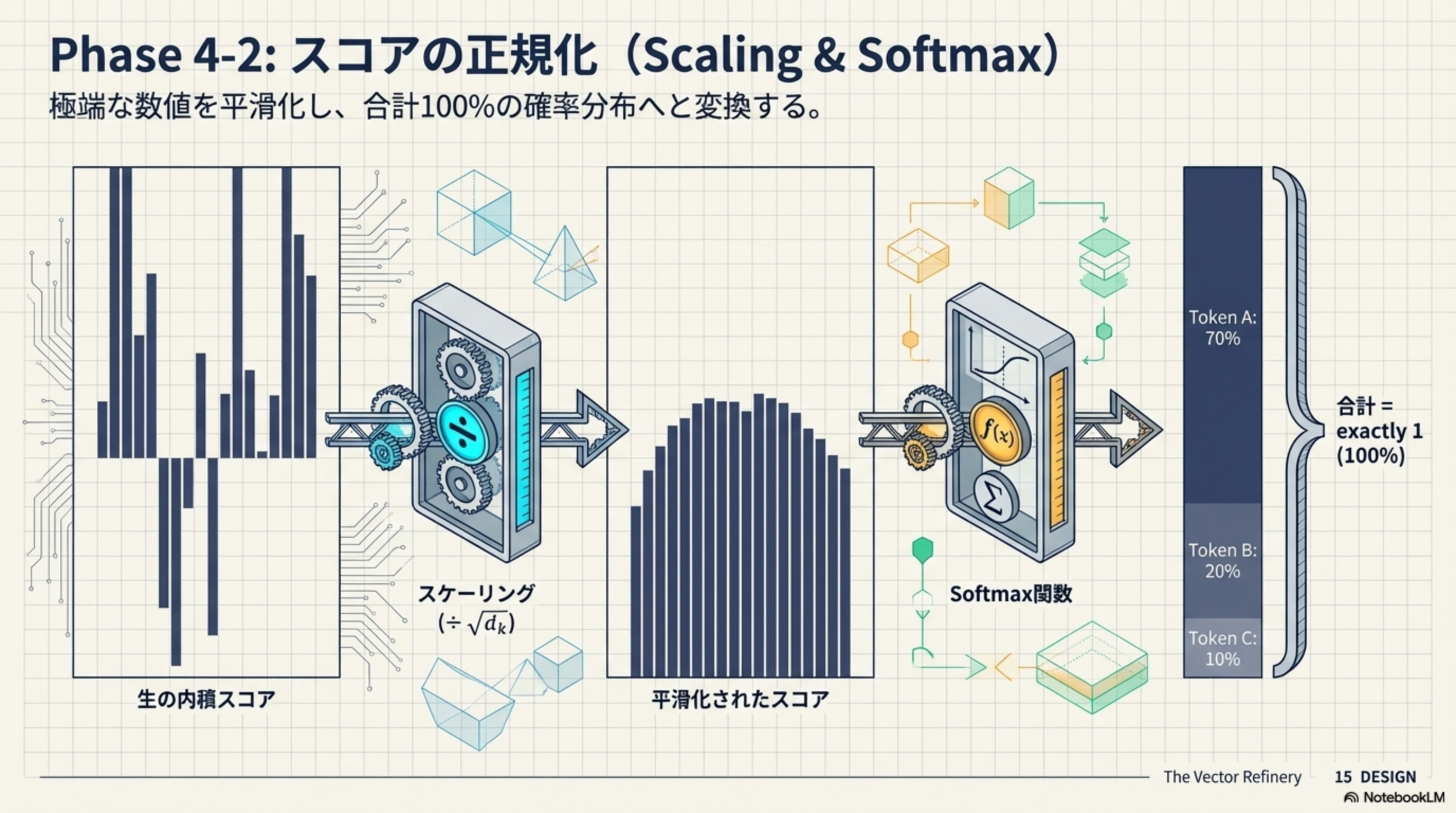
- スケーリング(÷ √dk):生の内積スコアは次元数が大きいと極端な値になりやすい。次元数の平方根で割ることで平滑化する
- Softmax関数:平滑化されたスコアを「合計 = exactly 1(100%)」の確率分布に変換。例:Token A: 70%、Token B: 20%、Token C: 10%
Phase 4-3:文脈の抽出と統合(Valueの加重平均)
アテンションは最も近いものを1つ選ぶ(検索)のではなく、すべての要素を重み付けして『混ぜ合わせる』のがアテンションの真髄です。Value A: 70%、Value B: 20%、Value C: 10% のように、計算された確率(重み)を使って必要な情報だけをブレンドし、文脈ベクトル(Context Vector)を生成します。
The Attention Equation:数式の完全解剖
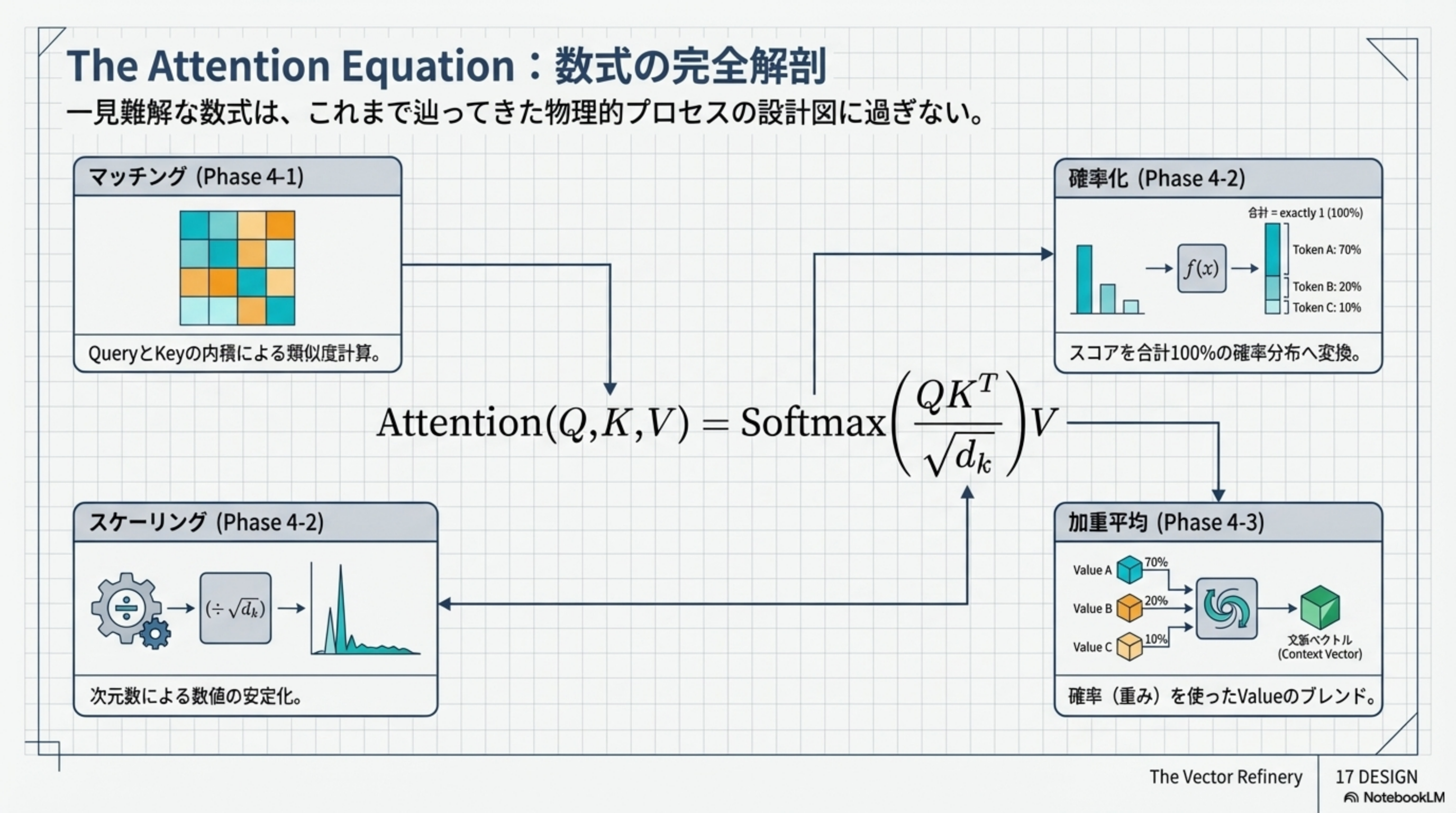
一見難解な数式 Attention(Q,K,V) = Softmax(QKT / √dk)V は、これまで辿ってきた物理的プロセスの設計図に過ぎません。マッチング(Phase 4-1)→ スケーリング(Phase 4-2)→ 確率化(Phase 4-2)→ 加重平均(Phase 4-3)の4ステップを1行で表現しています。
Phase 5:推論の高速化(KV Cache Mechanism)
生成プロセスにおいて、過去の計算結果を再利用する自己回帰の保存機構です。
トークンを1つずつ生成するとき、毎回ゼロから全トークンのK,Vを計算し直すのは無駄です。KV Cacheは過去に生成したトークンのK,Vをタンクに保存しておき、新しいトークンのQKVだけを計算して過去のKVと照合します。これにより推論コストを劇的に削減できます。
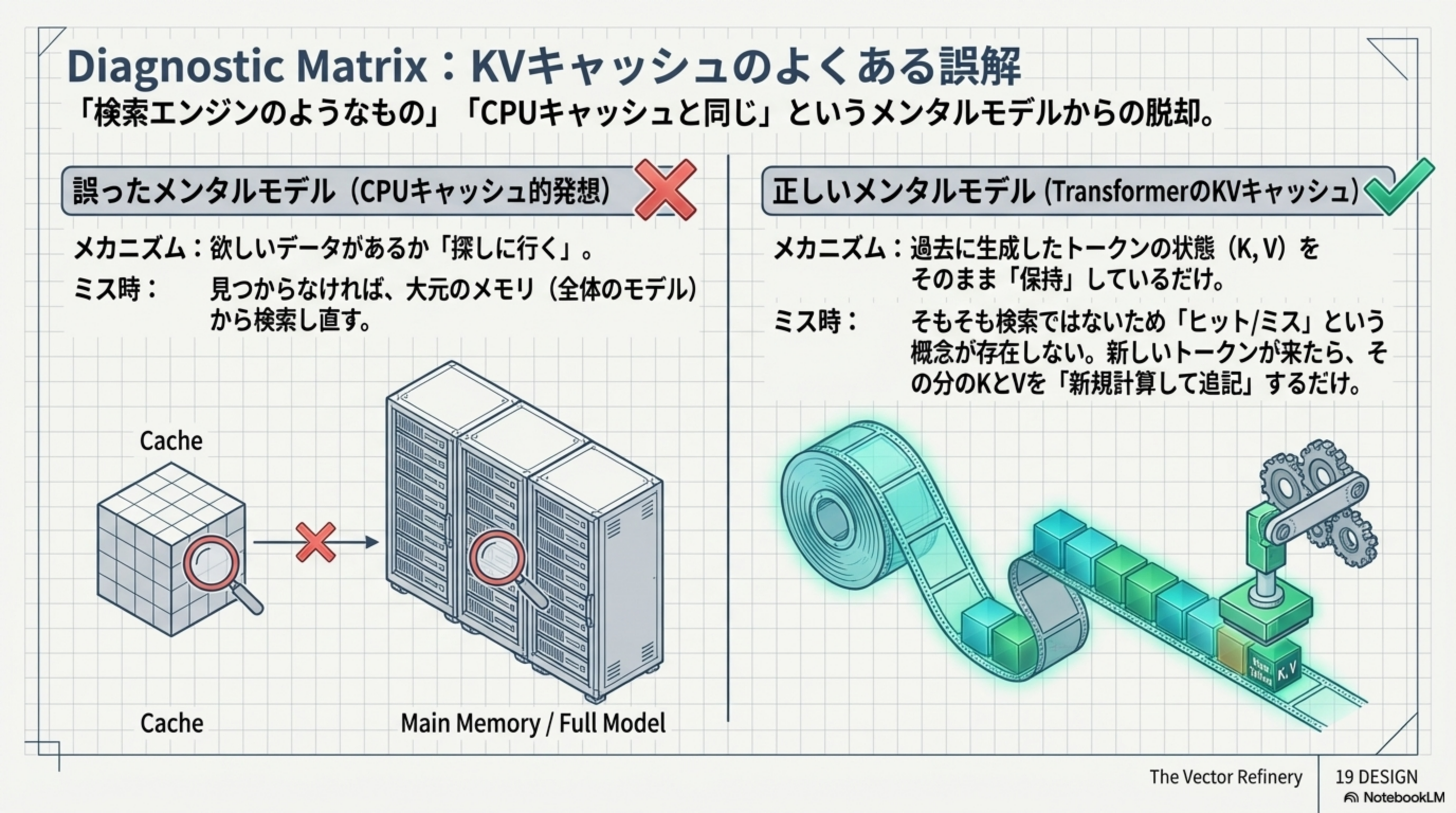
誤ったメンタルモデル(CPUキャッシュ的発想)
「欲しいデータがあるか探しに行く」。ミス時は大元のメモリ(全体のモデル)から検索し直す。これは間違い。
正しいメンタルモデル(TransformerのKVキャッシュ)
過去に生成したトークンの状態(K, V)をそのまま「保持」しているだけ。そもそも検索ではないため「ヒット/ミス」という概念が存在しない。新しいトークンが来たら、その分のKとVを「新規計算して追記」するだけ。
Phase 6:次の単語の予測(Output Generation)
文脈ベクトルを拡張し、辞書内の全単語に対する確率分布へと変換します。
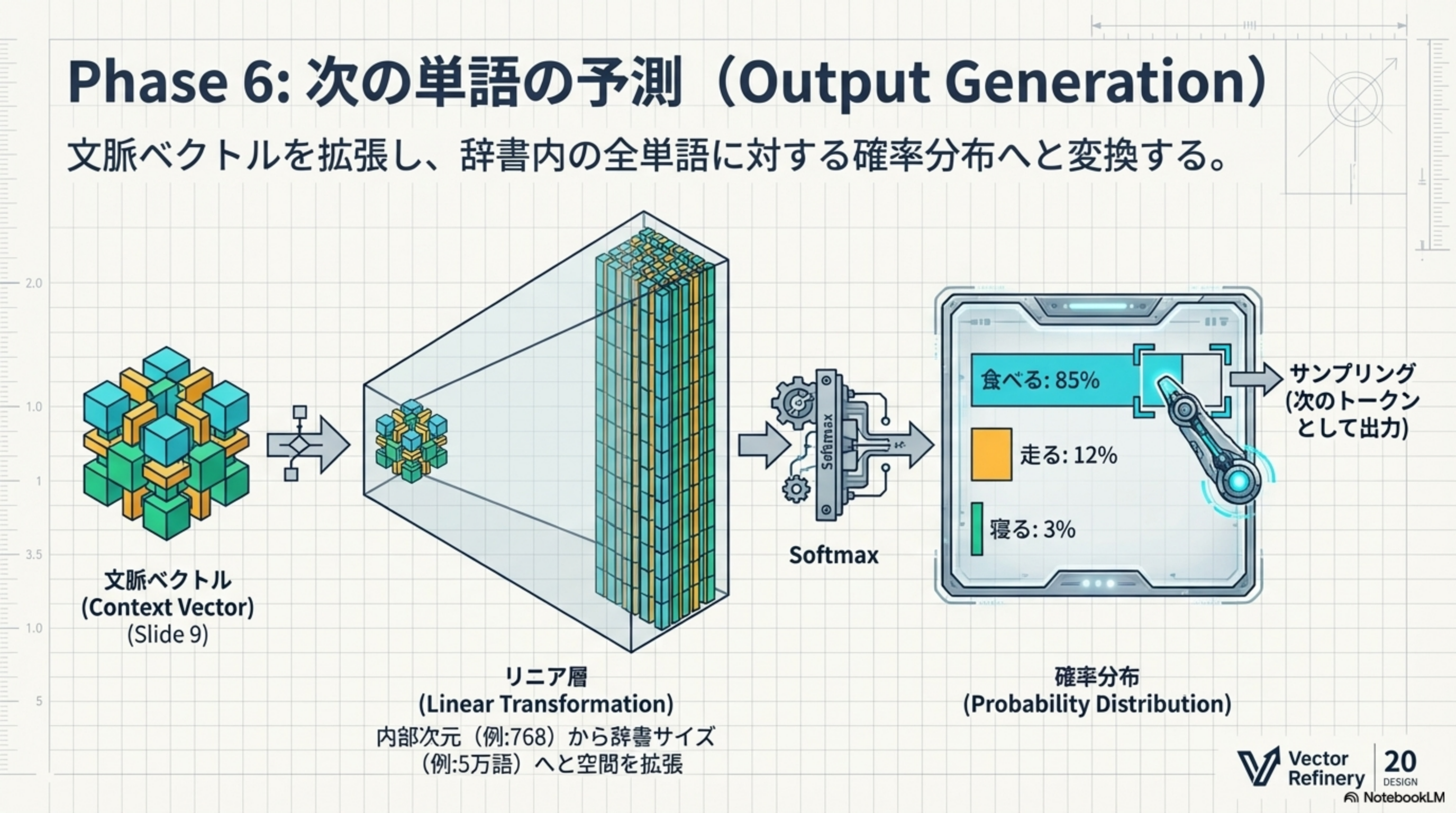
- 文脈ベクトル(Context Vector):Phase 4で生成された、文脈情報を凝縮したベクトル
- リニア層(Linear Transformation):内部次元(例:768)から辞書サイズ(例:5万語)へと空間を拡張
- 確率分布(Probability Distribution):Softmaxで各単語の確率を計算。例:「食べる」85%、「走る」12%、「寝る」3%
- サンプリング:確率に基づいて次のトークンを選択・出力
Synthesis:1つのトークンのライフサイクル
離散的な単語が確率の波へと姿を変えるまでの全軌跡を、5つのマイルストーンで振り返ります。
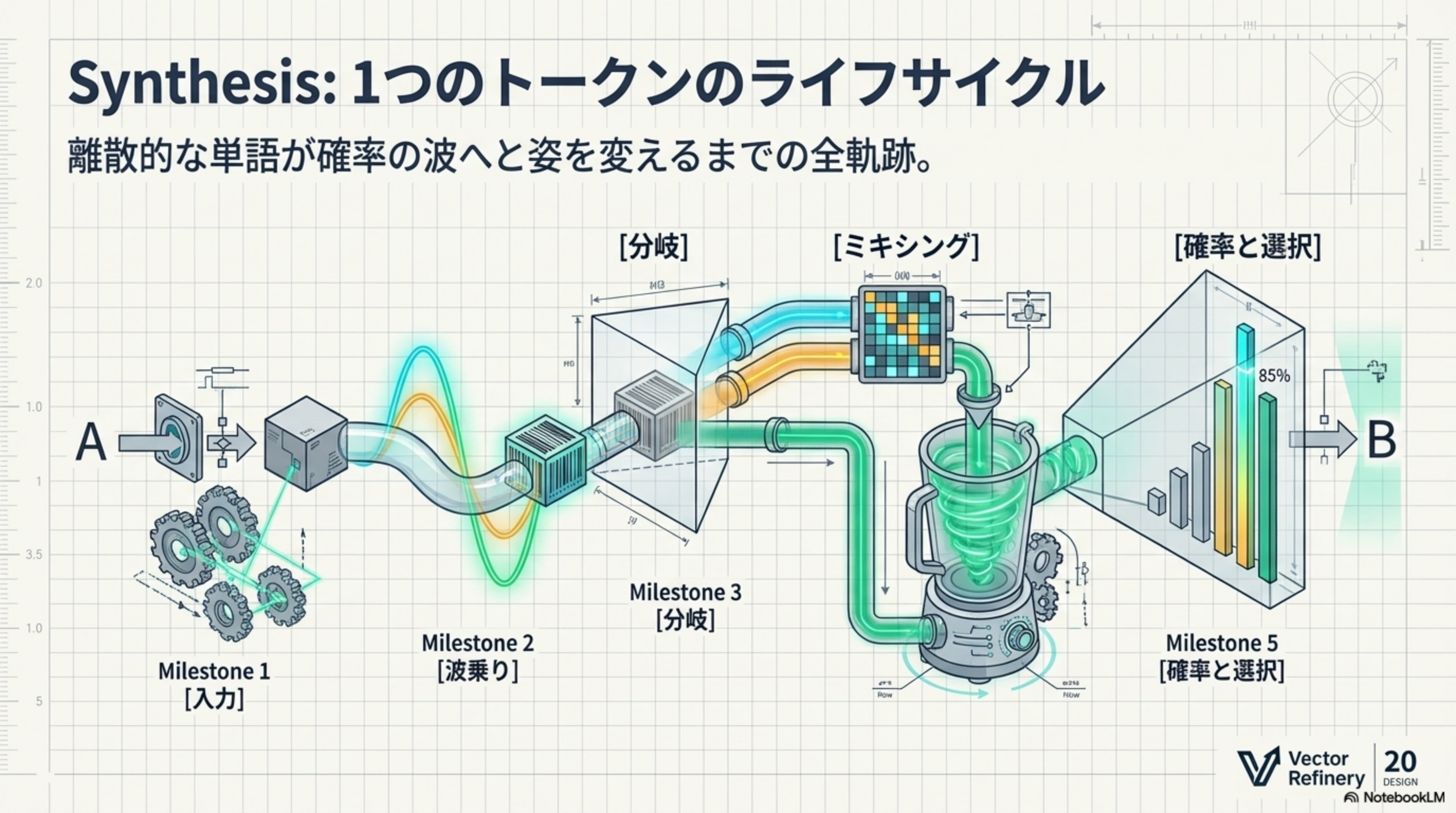
| Milestone | 名称 | 処理内容 |
|---|---|---|
| 1 | 入力 | テキストがトークンに分割され、ベクトル空間に埋め込まれる |
| 2 | 波乗り | 位置エンコーディングにより、sin/cos波で空間上の「指紋」が刻まれる |
| 3 | 分岐 | Q, K, V の3つの並列ストリームに分かれる |
| 4 | ミキシング | アテンション計算により文脈情報がブレンドされる |
| 5 | 確率と選択 | 確率分布に変換され、次のトークンとしてサンプリング・出力される |
まとめ:アテンション・メカニズムの真髄
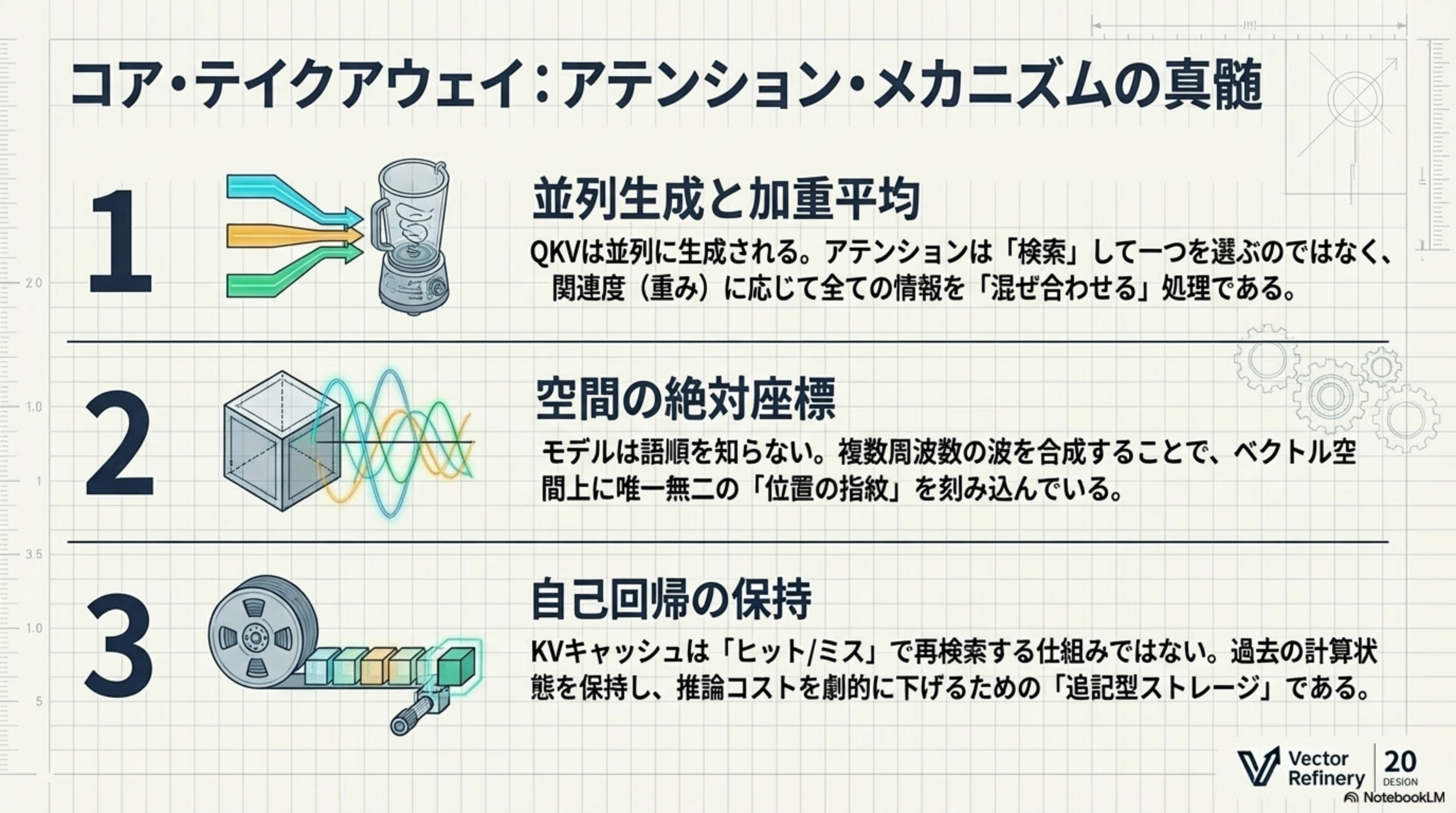
- 並列生成と加重平均 - QKVは並列に生成される。アテンションは「検索」して一つを選ぶのではなく、関連度(重み)に応じて全ての情報を「混ぜ合わせる」処理である
- 空間の絶対座標 - モデルは語順を知らない。複数周波数の波を合成することで、ベクトル空間上に唯一無二の「位置の指紋」を刻み込んでいる
- 自己回帰の保持 - KVキャッシュは「ヒット/ミス」で再検索する仕組みではない。過去の計算状態を保持し、推論コストを劇的に下げるための「追記型ストレージ」である
元のスライド一覧
クリックで拡大表示できます