はじめに:LLMは「覚えている」のか?
ChatGPTやClaudeと会話していると、まるでAIが前回の話を覚えているように感じます。しかしその「記憶」は錯覚です。LLMの核心的性質は完全にステートレス(状態を持たない)であり、前回の会話を内部的に保持することはありません。ユーザーが体験する「ステートフル」な挙動は、すべてアプリケーション層が過去の会話履歴を毎回プロンプトに含めて再送信することで実現されています。
- LLMが完全にステートレスである理由と、アプリ層による疑似ステートフル化の仕組み
- 記憶を持っているのは「誰」か ― 4つの層のステート管理構造
- トークン累積の O(N²) 爆発メカニズムとコスト影響
- コンテキストウィンドウの4つの限界
- 「Lost in the Middle」問題とゴールデンルール
- プロンプトキャッシュによるコスト84%削減の仕組み
- 3層コンテキスト管理(Full History → 圧縮 → RAG)
- 永続的エージェント(Hermes等)の認知科学的記憶設計
- プロバイダー別キャッシュ仕様の比較(Anthropic / OpenAI / Google)
- キャッシュ効率を最大化する5つのテクニック
- キャッシュを台無しにする6つのアンチパターン
LLMは完全にステートレスである
ChatGPTやClaudeなどのLLM本体は、基本的には純粋な関数(入力に対して出力を返すのみ)であり、モデルそのものが「前回の会話状態」を保持することはありません。Anthropic APIやOpenAI APIのモデル本体は、サーバー側にセッションや会話状態を一切持たない純粋な関数として機能します。
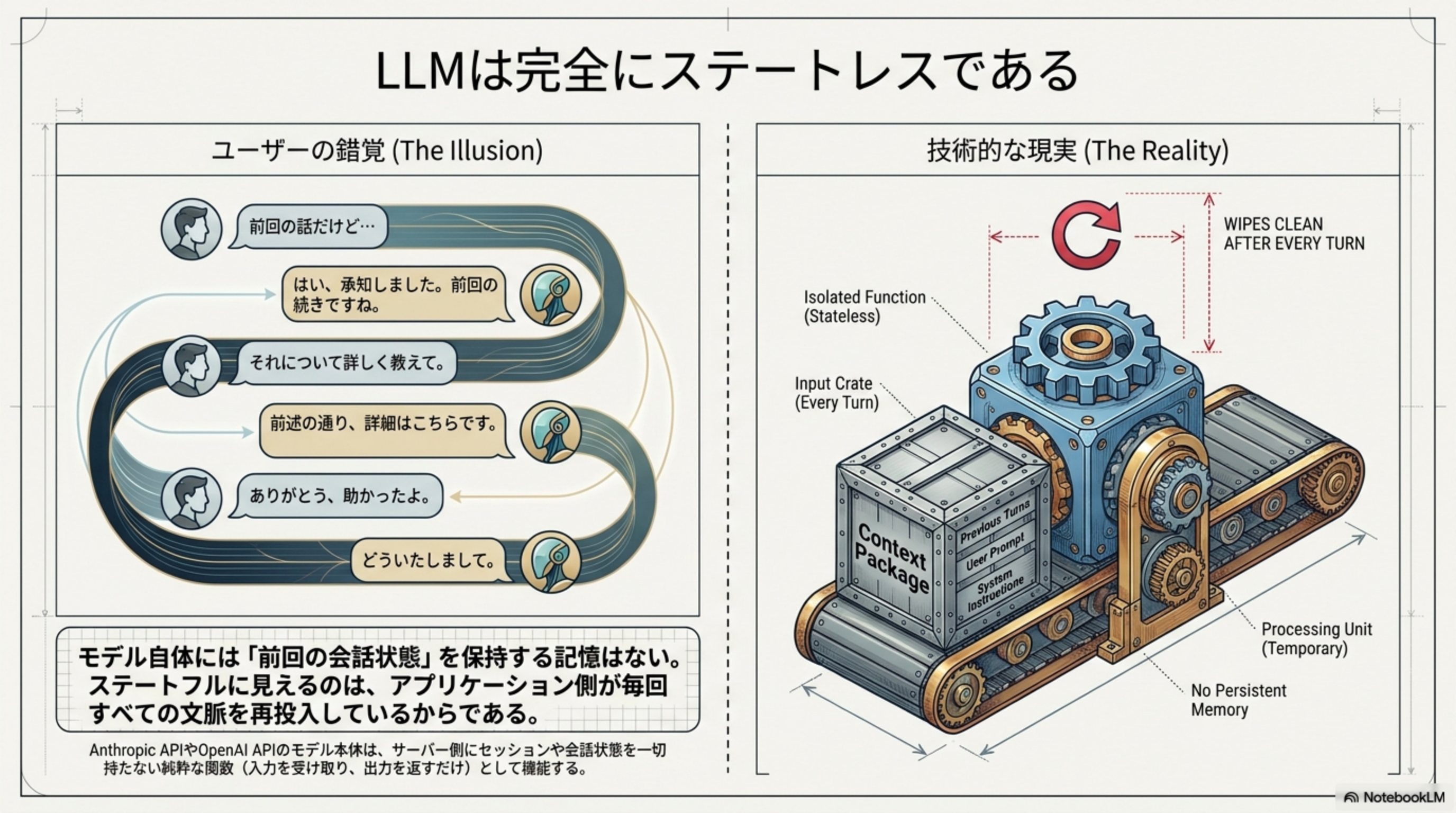
ステートフルに見えるのは、アプリケーション側が毎回すべての文脈を再投入しているからです。モデルは毎ターン完全にリセットされ、「Context Package」として過去の会話履歴・システムプロンプト・ユーザー入力がまとめて送信されます。
モデル自体には「前回の会話状態」を保持する記憶はない。ステートフルに見えるのは、アプリケーション側が毎回すべての文脈を再投入しているからである。
記憶を持っているのは「誰」か?
「文脈を覚えている」と感じる背後には、4つの異なる層がそれぞれの役割でステート管理を担っています。
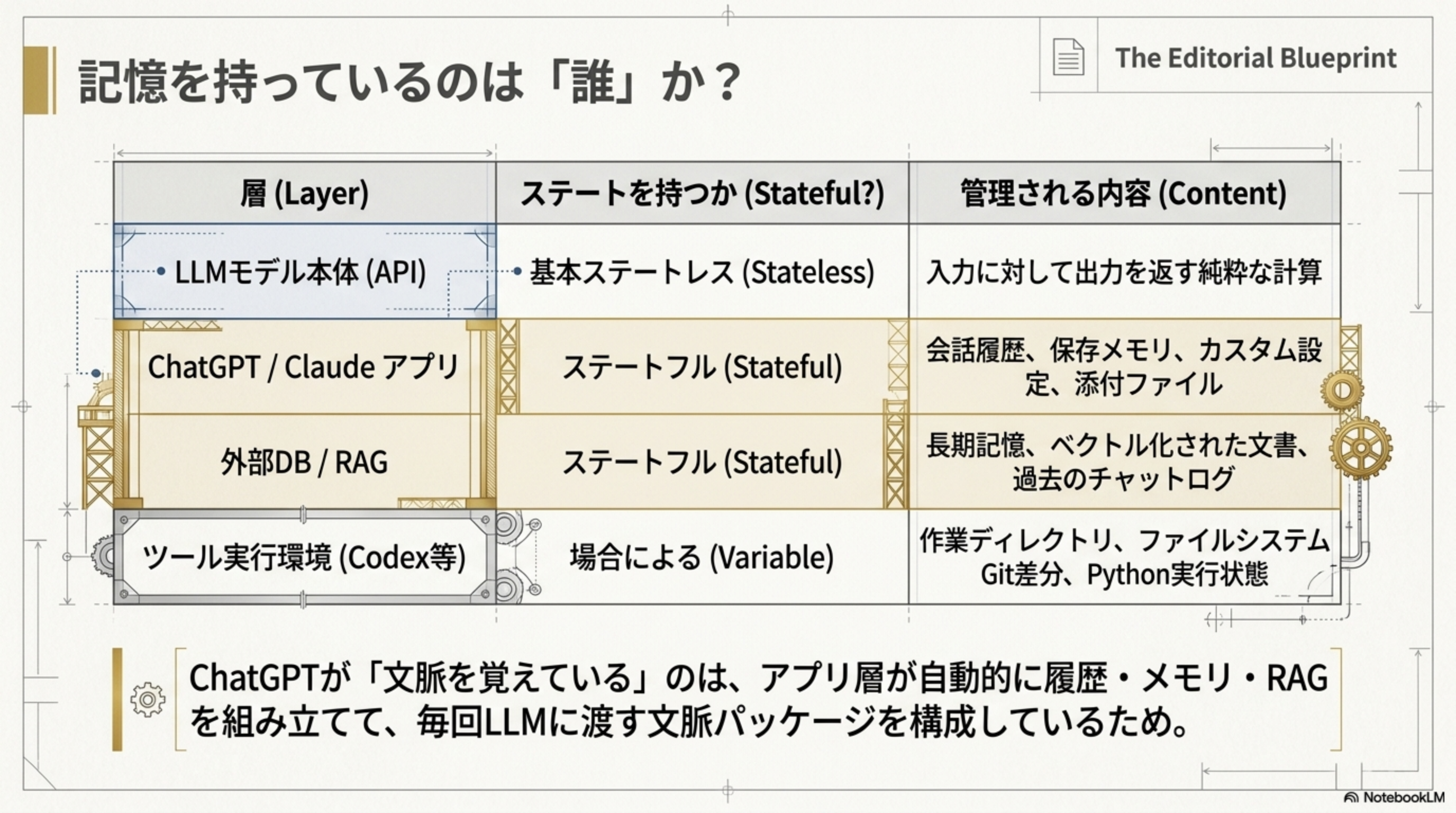
| 層(Layer) | ステートを持つか | 管理される内容 |
|---|---|---|
| LLMモデル本体(API) | 基本ステートレス(Stateless) | 入力に対して出力を返す純粋な計算 |
| ChatGPT / Claude アプリ | ステートフル(Stateful) | 会話履歴、保存メモリ、カスタム設定、添付ファイル |
| 外部DB / RAG | ステートフル(Stateful) | 長期記憶、ベクトル化された文書、過去のチャットログ |
| ツール実行環境(Codex等) | 場合による(Variable) | 作業ディレクトリ、ファイルシステム、Git差分、Python実行状態 |
Claude CLIでは、セッションID(UUID)やローカルのJSONLファイルを用いて会話状態を管理しています。
--continue (-c):直前のセッションを継続--resume (-r):セッションIDを指定して特定の会話を再開--fork-session:共通のベースセッションから別の思考プロセスを分岐
トークン累積のメカニズム(毎回フル送信)
会話履歴をすべて再送信する方式では、新しいメッセージを送るたびに過去の会話履歴をすべて再送信する必要があります。会話が何ターン続けられるかは、固定のターン数ではなく「合計トークン量」に依存します。
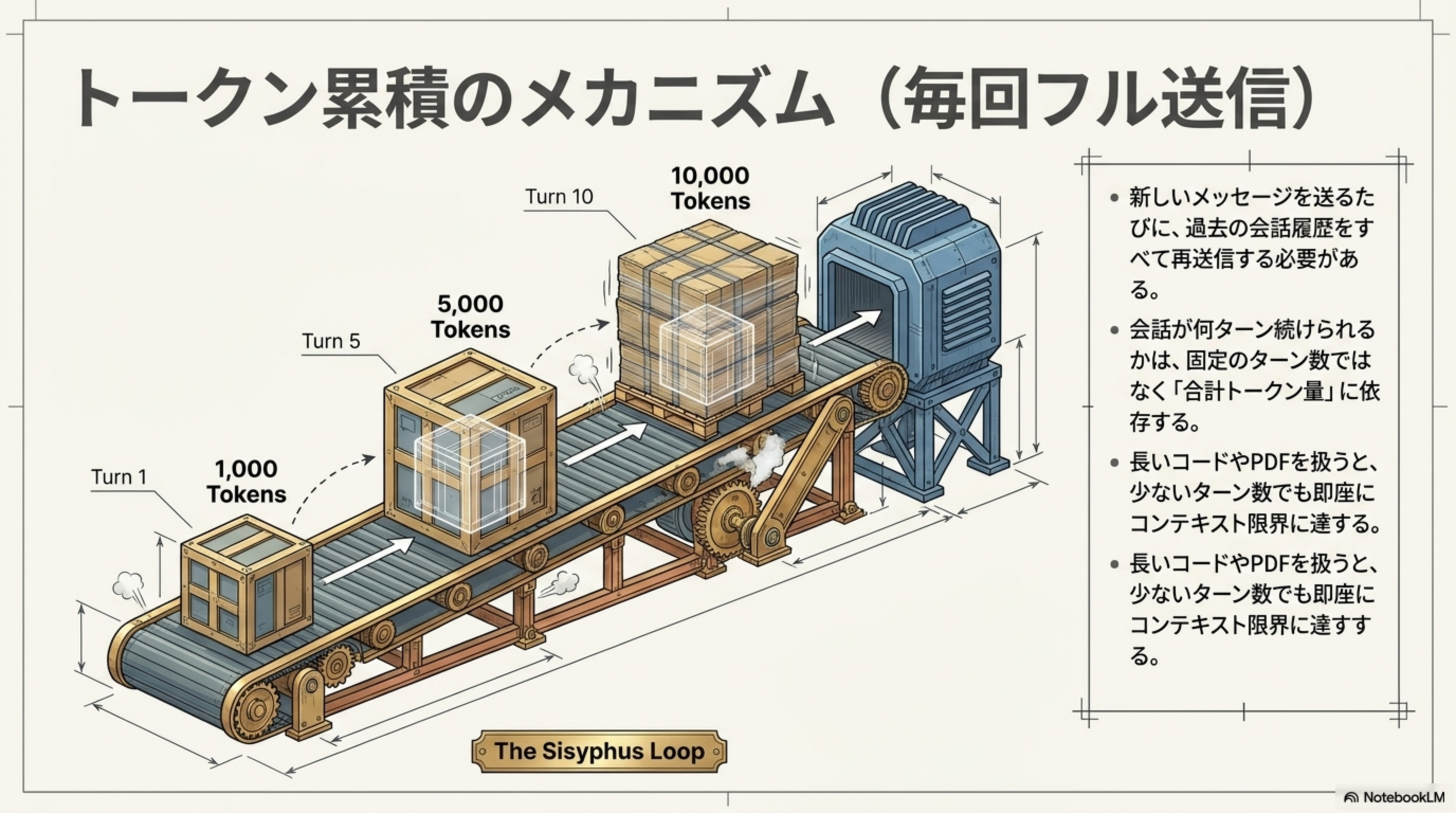
長いコードやPDFを扱うと、少ないターン数でも即座にコンテキスト限界に達します。100Kトークンの文書を読み込ませて20ターン議論すると、累計約2,000Kトークンを消費します。
履歴の累積が引き起こす「O(N²)のトークン爆発」
送信トークン総量は会話の長さの2乗に比例して増加します。1ターンあたり1,000トークン増加するケースでは、50ターン目には累計1,275,000トークンに達します。
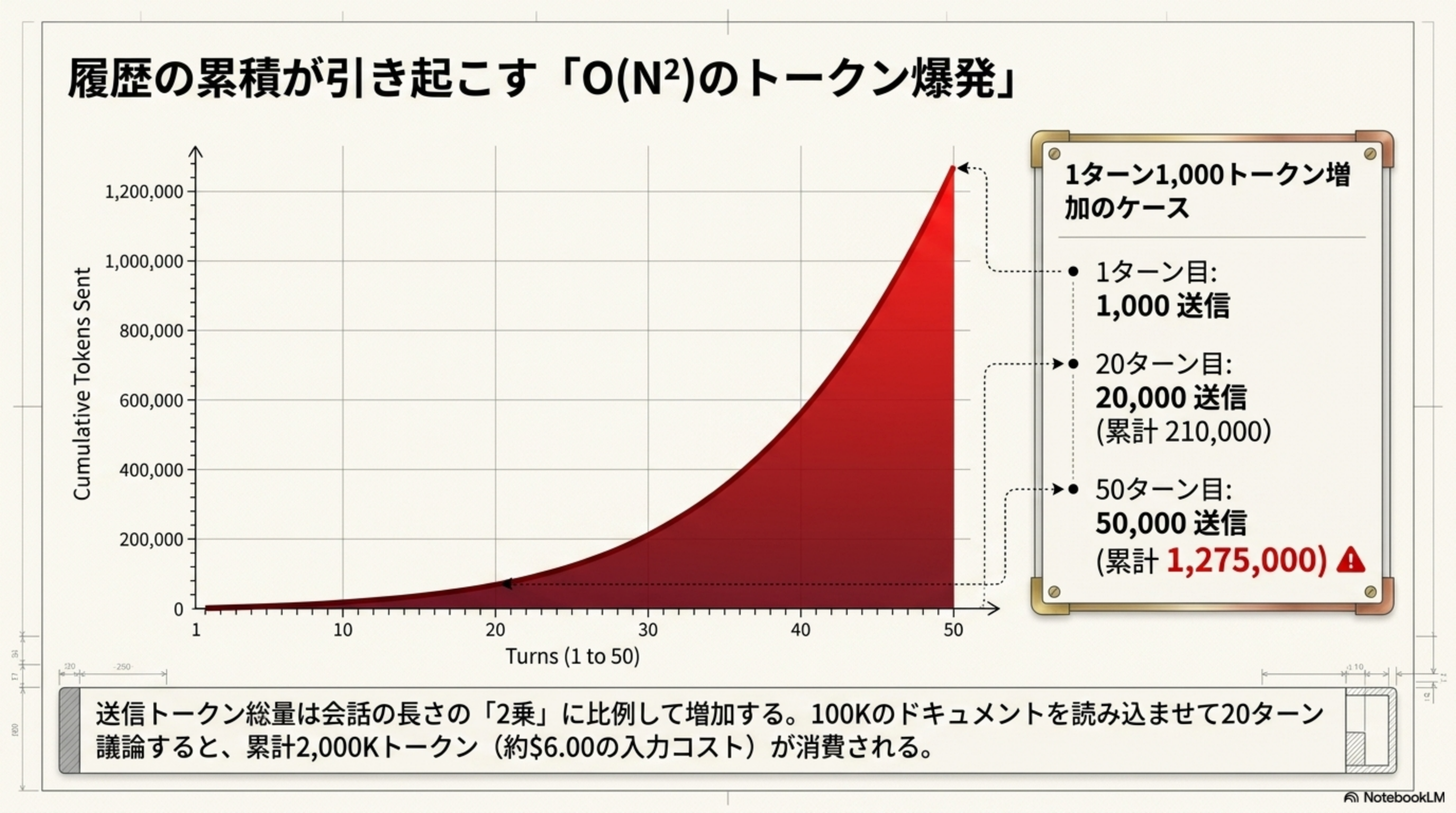
| ターン数 | そのターンの送信量 | 累計送信トークン |
|---|---|---|
| 1 | 1,000 | 1,000 |
| 20 | 20,000 | 210,000 |
| 50 | 50,000 | 1,275,000 |
コスト影響:サブスクリプションモデルで「上限に当たりやすくなる」現象や、API利用におけるコスト急増の主因となります。
コンテキストウィンドウの4つの限界
コンテキストウィンドウには、単に「枠を広げる」だけでは解決しない4つの根本的な制約があります。物理的(VRAM)および数学的(計算量)な制約が重なり合っています。
| 制約 | 種類 | 内容 |
|---|---|---|
| 1. アーキテクチャの根本制約 | Math | TransformerのSelf-AttentionはN×Nの行列計算(O(N²)) |
| 2. 推論時のメモリ限界 | Hardware | KVキャッシュの増大。200Kトークンで約520GBのVRAMが必要(H100の80GBを凌駕) |
| 3. 学習時の最大長 | Training | モデルが学習時に経験した最大長による制限 |
| 4. 性能劣化 | Performance | 実効的な精度の低下。複数事実の統合の失敗や「Lost in the Middle」 |
巨大なコンテキストの死角「Lost in the Middle」
長いコンテキストウィンドウを詰め込むと、入力の先頭や末尾の情報は処理されやすいが、中間に配置された重要な情報が見落とされる現象が発生します。これが「Lost in the Middle」問題です。
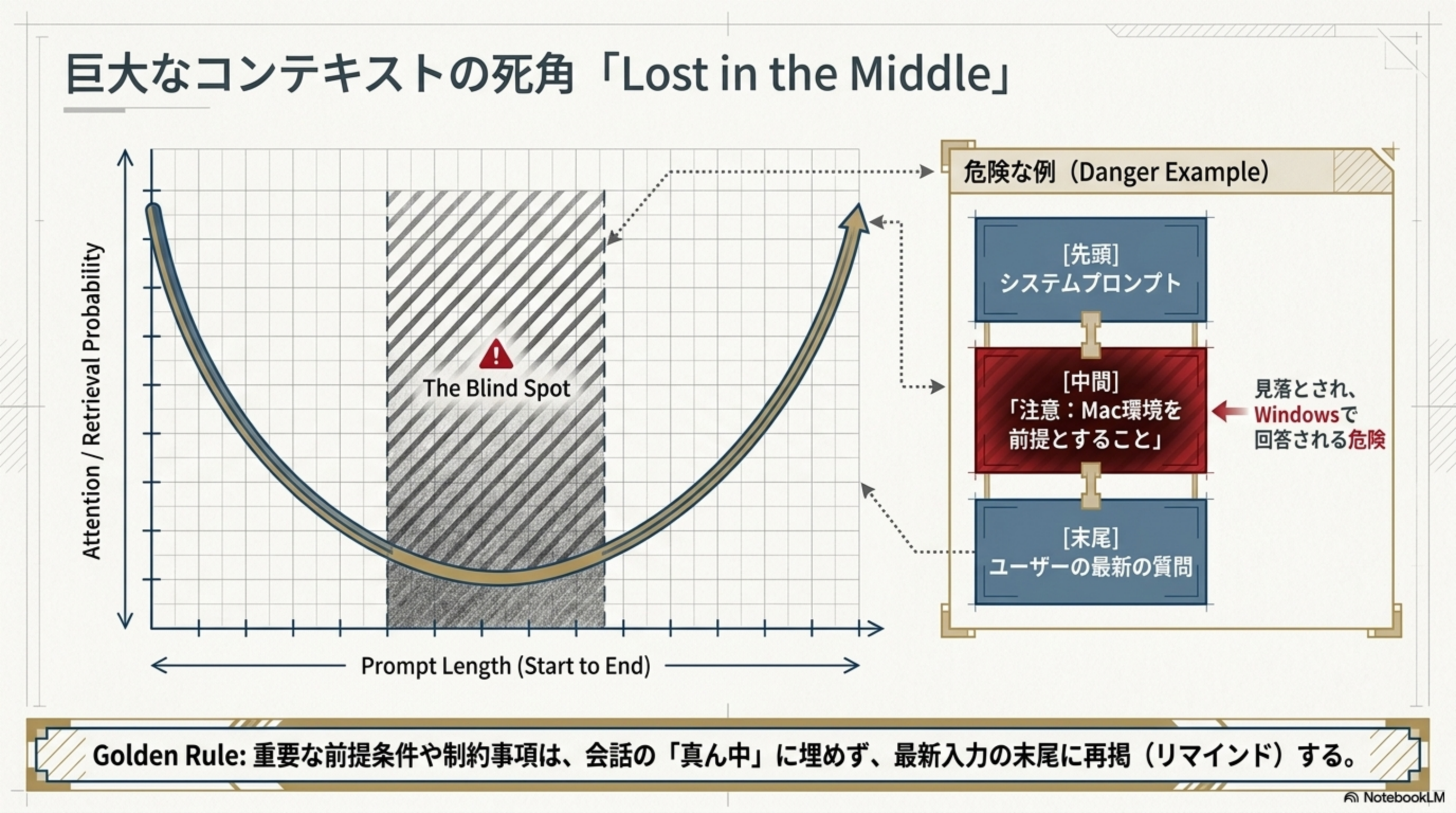
具体例:冒頭で環境を「Mac」と指定し、中盤に大量の履歴を挟んだ後で質問をすると、モデルがWindows前提の回答をするリスクがあります。
重要な前提条件や制約事項は、会話の「真ん中」に埋めず、最新入力の末尾に再掲(リマインド)する。
トークン爆発の救世主:プロンプトキャッシュ
プロンプトキャッシュは、APIサーバー側でリクエストの先頭部分(Prefix)を一時保存し、再計算をスキップする技術です。同じプロンプトの「接頭辞(Prefix)」が一致すると、サーバー側で計算済みのKV状態を再利用します。
- 「変わらないもの」を前に:システムプロンプト、ツール定義、固定資料を先頭に配置
- 「変わるもの」を後ろに:検索結果、日時、毎回変わるメタ情報は末尾に配置
- Prefix一致が崩れるとキャッシュが機能しないため、配置順序が極めて重要
キャッシュの経済学(100Kコンテキスト × 20ターンの場合)
プロンプトキャッシュのコスト効果は劇的です。損益分岐点はわずか「2ターン目」。システムプロンプトやRAGの固定資料を先頭に固めることで、APIコストを劇的に圧縮できます。

| 方式 | コスト | 削減率 |
|---|---|---|
| キャッシュなし(No Cache) | $6.00 | - |
| キャッシュあり(With Cache) | $0.945 | 84%削減 |
- 通常 Input:1.0x(基準)
- Cache Write(初回登録):1.25x(やや割高)
- Cache Read(2回目以降):0.1x(10倍安い)
キャッシュを最大化する設計ルール
キャッシュは「前方一致」で効くため、プロンプトの構造化が極めて重要です。「Bedrock to Sand」アーキテクチャに従い、固い(変わらない)情報を土台に、変動する情報を上に積みます。
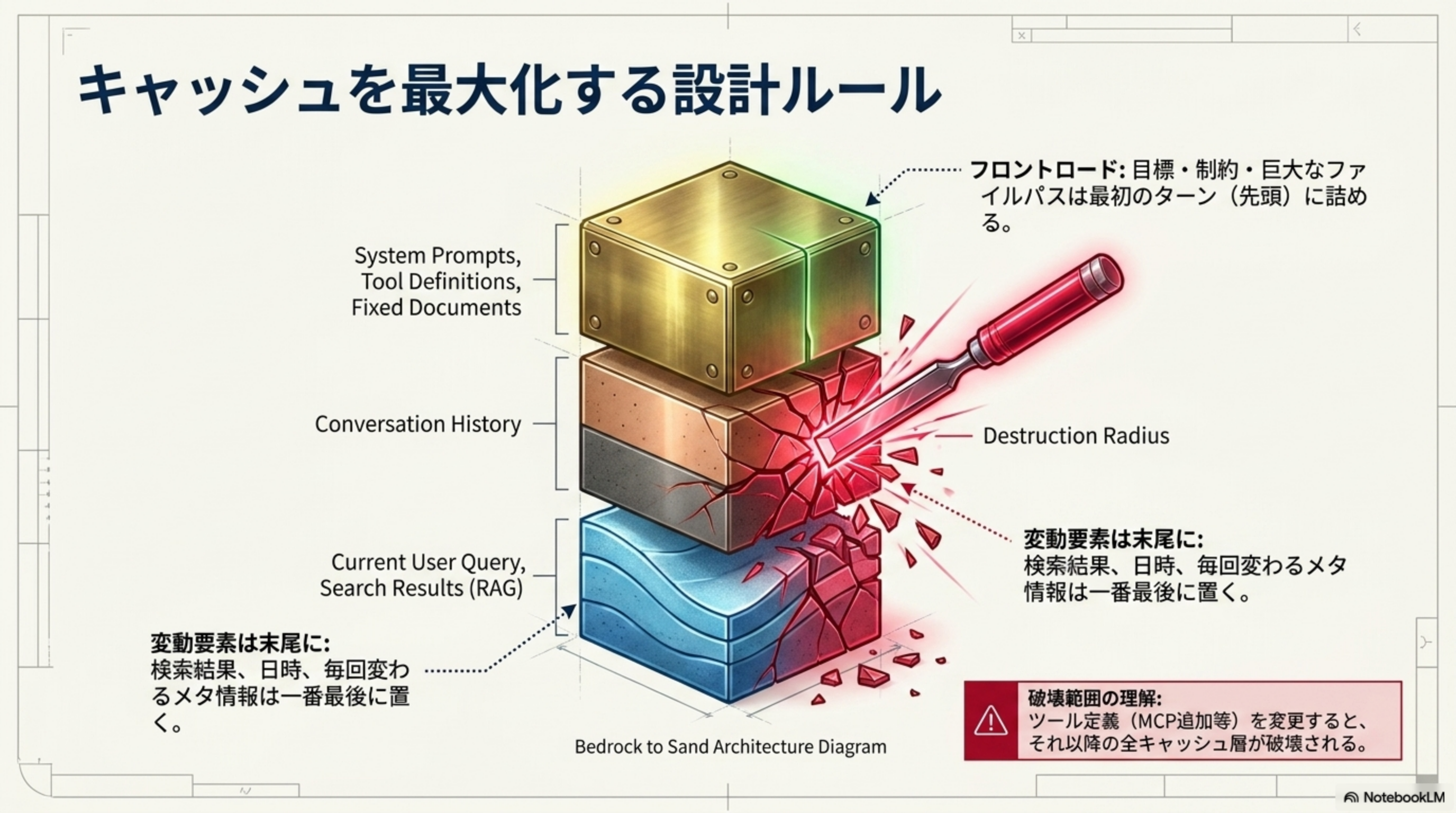
| 配置順序 | 要素 | 変動頻度 |
|---|---|---|
| 先頭(フロントロード) | System Prompts, Tool Definitions, Fixed Documents | ほぼ不変 |
| 中間 | Conversation History | 徐々に増加 |
| 末尾(バックロード) | Current User Query, Search Results (RAG) | 毎回変動 |
ツール定義(MCP追加等)を変更すると、それ以降の全キャッシュ層が破壊されます。先頭付近に日時やセッションIDなど毎回変わるメタ情報を入れることも、キャッシュ効率を大幅に低下させます。
限界を突破する3層のコンテキスト管理
トークン爆発とコンテキスト制限に対応するため、単一のコンテキストウィンドウにすべてを詰め込むのではなく、情報の鮮度と重要度に応じて3つの層を使い分けます。
| レイヤー | 名称 | 内容 |
|---|---|---|
| Layer 1 | 履歴の保持と再送信(Full History) | 短期的な会話のやり取りをそのまま保持。O(N²)で爆発するまでの初期フェーズ |
| Layer 2 | コンテキスト圧縮(Compression) | 古い履歴を定期的に要約(Rolling summarization)に置き換え、トークン数を能動的に圧縮 |
| Layer 3 | 外部記憶への退避(External RAG) | ベクトルDBやグラフ構造を用いて、クエリに関連する情報だけを外部から動的に取得 |
- 自動圧縮:一定量(例:167Kトークン)を超えると、古い履歴をLLM自身に要約させ、要約文に置き換え
- 手動圧縮:
/compactコマンド等でユーザーが任意に整理
永続的な心を作る:自律型エージェントの正体
「Hermes Agent」などの先進的な設計では、LLMのステートレス性を前提に、外側のシステムで「永続的な知能体」を構成しています。AIエージェントは、LLMの進化を待つのではなく、「外側の記憶システム」を構築することでステートフルな知能体を実現しています。
| # | コンポーネント | 実装 | 役割 |
|---|---|---|---|
| 1 | 会話メモリ | SQLite + 全文検索 | クロスセッションの履歴を永続化 |
| 2 | ユーザーモデル | User Profile Memory Bank | ユーザーの好みや特性を弁証法的に蓄積(Honcho等) |
| 3 | 自動生成スキル | Skill Repository(Markdown) | 解決した解法をMarkdown化し、次回に再利用(自己改善ループ) |
| 4 | 永続環境 | Persistent Serverless Environment | サーバーレスコンテナでの作業環境の保持 |
エージェントを形作る「3つの記憶」
認知科学における記憶の分類を、AIエージェントの設計に応用します。記憶は単一の構造ではなく、役割ごとに別々のデータベースと検索ロジックを持たせることが、高度なエージェントの条件です。

| 記憶の種類 | 認知科学的分類 | 実装 | 内容 |
|---|---|---|---|
| エピソード記憶 | Episodic|いつ何が起きたか | 会話DB(SQLite + FTS5) | 過去の関連会話を検索し、要約してコンテキストに注入 |
| 意味記憶 | Semantic|ユーザーはどんな人か | ユーザープロファイルDB | 文脈から人物像の解像度を上げ、永続的に保持 |
| 手続き記憶 | Procedural|どうやって解決するか | スキルファイル(Markdown) | ツール実行の結果得られた成功パターンを記録し、次回呼び出す |
compression.threshold:圧縮を発動させる閾値compression.protect_last_n:直近の文脈を保護するために要約から除外するターン数memory.memory_char_limit:個別の記憶エントリの詳細度
SYNTHESIS:認知アーキテクチャの全貌
すべてを統合すると、ステートレスな推論エンジンの周囲に、履歴管理・プロンプトキャッシュ・3層の外部記憶を緻密にオーケストレーションする「認知アーキテクチャ」が浮かび上がります。
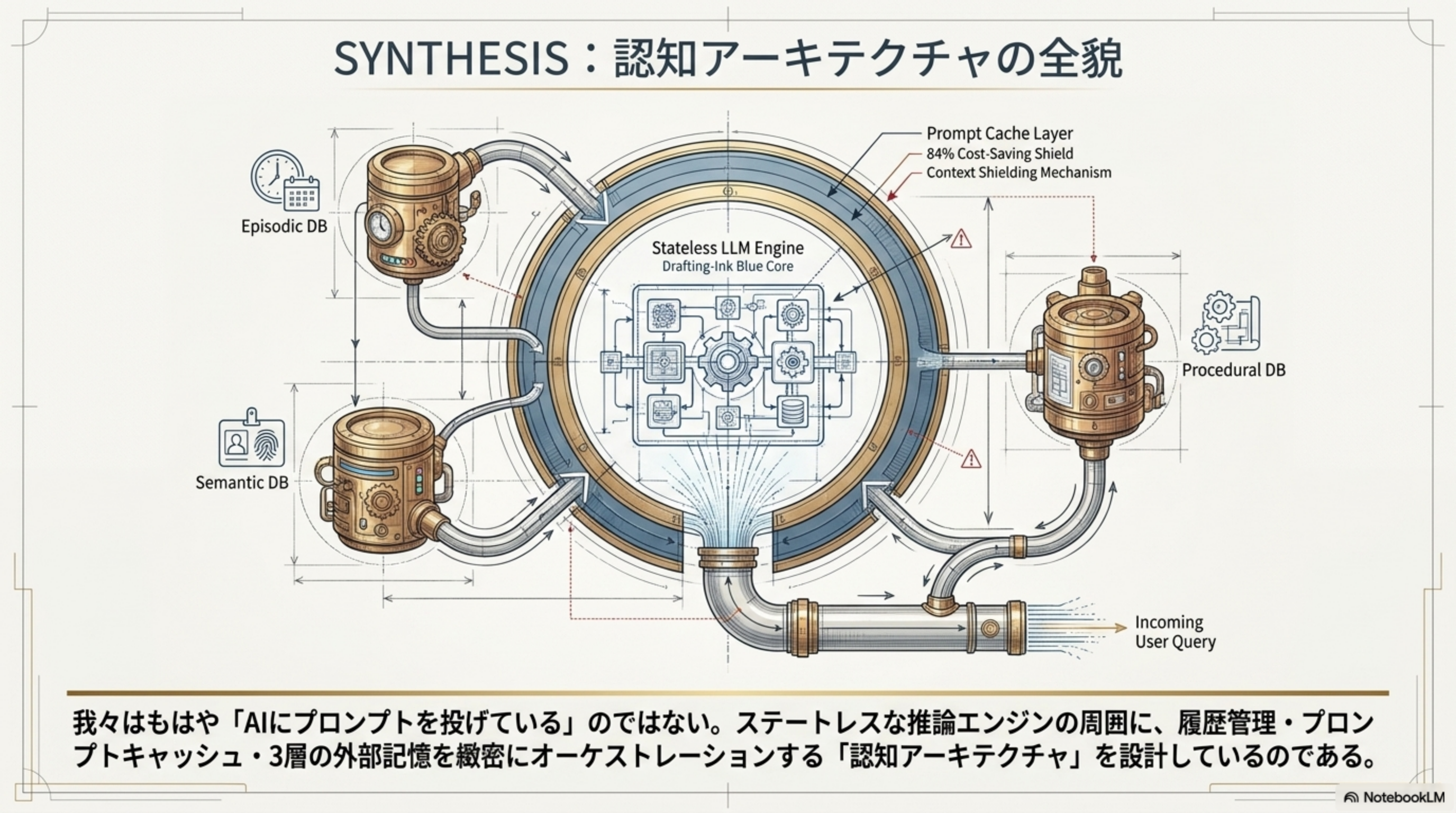
我々はもはや「AIにプロンプトを投げている」のではありません。ステートレスな推論エンジンの周囲に、履歴管理・プロンプトキャッシュ・3層の外部記憶を緻密にオーケストレーションする「認知アーキテクチャ」を設計しているのです。
開発者のための3つのゴールデンルール

- LLMは純粋な関数である:「記憶」はモデルの機能ではなく、アプリケーション層が責任を持って管理・構築するシステムであると認識せよ。
- O(N²)のトレードオフを支配せよ:フルコンテキストの送信は破綻する。「変わらないもの」を先頭にしてキャッシュの恩恵を最大化し、変動要素は末尾に分離せよ。
- 記憶を階層化し、外部化せよ:単一ウィンドウに頼るのをやめ、エピソード、意味、手続きを別々のストレージに分離して必要な時だけRAGで注入せよ。
ステートフルなAIは、プロンプトの工夫ではなく、外側のアーキテクチャ設計によってのみ実現される。「LLMは純粋な関数であり、記憶はアプリケーション層の責任である」という原則を理解することが、高度なAIシステム設計の出発点です。
実践編:プロンプトキャッシュのテクニックとアンチパターン
プロンプトキャッシュの理論を理解しても、実装で台無しにしてしまうケースは非常に多いです。ここでは、キャッシュ効率を最大化するための具体的なテクニックと、無意識にキャッシュを破壊してしまう6つのアンチパターンを解説します。
プロバイダー別:キャッシュの基本仕様
プロンプトキャッシュの仕様はプロバイダーごとに異なります。設計時に把握すべき主要な違いを整理します。
| 項目 | Anthropic(Claude) | OpenAI(GPT) | Google(Gemini) |
|---|---|---|---|
| キャッシュ方式 | 明示的(cache_control ブレイクポイント指定) |
自動(Prefix一致で自動適用) | 明示的(cached_content リソース作成) |
| 最小トークン数 | 1,024 トークン(Haiku) 2,048 トークン(Sonnet/Opus) |
1,024 トークン | 4,096 トークン |
| TTL(有効期限) | 5分(再ヒットで延長) | 5〜10分 | 明示指定(最低1分〜) |
| Cache Read コスト | 通常の 0.1x(90%OFF) | 通常の 0.5x(50%OFF) | 通常の 0.25x(75%OFF) |
| Cache Write コスト | 通常の 1.25x(25%増) | 追加コストなし | 通常の 1.0x(同額) |
Anthropicは Cache Read が通常の 10分の1 と最も割引率が高いため、長いシステムプロンプトやツール定義を多用するエージェント設計では特に大きなコスト効果を発揮します。ただし、最小トークン数の閾値に注意が必要です。
キャッシュ効率を最大化する5つのテクニック
| # | テクニック | 解説 |
|---|---|---|
| 1 | 静的コンテンツのフロントロード | システムプロンプト → ツール定義 → 固定参考資料 → 会話履歴 → ユーザー入力の順で配置。先頭の不変部分が長いほどキャッシュヒット率が上がる |
| 2 | ブレイクポイントの戦略的配置 | Anthropic APIでは最大4つの cache_control ブレイクポイントを設定可能。システムプロンプト末尾、ツール定義末尾、固定ドキュメント末尾など、論理的な区切りに配置する |
| 3 | TTLを意識したリクエスト間隔 | キャッシュのTTLは5分。5分以内に次のリクエストを送ればキャッシュが延長される。バッチ処理では間隔を5分以内に保つ設計にする |
| 4 | ツール定義の順序を固定 | MCP等でツールを動的に追加する場合も、ツール定義の配列順序を常に一定に保つ。順序が変わるだけでPrefix一致が崩れ、キャッシュが無効化される |
| 5 | 大きな参考資料はシステムメッセージに | RAGで取得した固定ドキュメントや大きなコードベースは、ユーザーメッセージではなくシステムメッセージの一部として先頭付近に配置する |
キャッシュを台無しにする6つのアンチパターン
以下は、キャッシュを「無意識に」破壊してしまう典型的なミスです。1つでも該当すると、キャッシュの恩恵が大幅に失われます。
| # | アンチパターン | なぜ壊れるか | 対策 |
|---|---|---|---|
| 1 | 先頭にタイムスタンプを挿入 | システムプロンプトの冒頭に Current time: 2026-05-01T12:00:00Z などを入れると、毎リクエストでPrefix全体が変わり、キャッシュが100%ミスする |
タイムスタンプは末尾のユーザーメッセージに配置する |
| 2 | ツール定義の順序が不安定 | MCPサーバーの起動順やハッシュマップの列挙順で、ツール定義のJSON配列順序が毎回変わる。先頭から異なるためキャッシュが全滅する | ツール定義をアルファベット順等でソートしてから送信する |
| 3 | セッションIDをシステムプロンプトに含める | セッションごとに異なるIDやUUIDをシステムプロンプトに埋め込むと、セッションが変わるたびにキャッシュが無効化される | セッション固有情報はユーザーメッセージの末尾に配置する |
| 4 | RAG検索結果をシステムプロンプトの途中に挿入 | 動的に変わるRAG結果をシステムプロンプトの中間に配置すると、その位置以降のキャッシュがすべて破壊される | RAG結果は最後のユーザーメッセージ内か、システムメッセージの最末尾に配置する |
| 5 | 最小トークン閾値を下回るキャッシュ指定 | キャッシュ対象が最小トークン数(例:Sonnetなら2,048)に満たないと、キャッシュが書き込まれずCache Writeのコストだけ無駄に発生する | システムプロンプトが短い場合は、固定ドキュメントを追加して閾値を超えるようにする |
| 6 | 会話履歴の再構築方法が不安定 | 過去のメッセージを再構成する際に、メタデータの付与方法や空白・改行の扱いが微妙に変わると、バイト列レベルでPrefix一致が崩れる | 会話履歴のシリアライズ方法を完全に固定し、毎回同一のバイト列を生成する |
Anthropic APIのレスポンスヘッダには cache_creation_input_tokens と cache_read_input_tokens が含まれます。cache_read_input_tokens が 0 のまま推移している場合、上記のアンチパターンのいずれかに該当している可能性が高いです。本番環境では必ずこのメトリクスを監視しましょう。
Anthropic API でのキャッシュ実装例
# Anthropic API - プロンプトキャッシュの実装例
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-5-20250514",
max_tokens=1024,
system=[
{
"type": "text",
"text": "あなたはAIアシスタントです。...(長いシステムプロンプト)...",
"cache_control": {"type": "ephemeral"} # ← ブレイクポイント1
}
],
tools=[
# ... ツール定義(順序を固定!)...
# 最後のツールに cache_control を付与
{
"name": "search",
"description": "...",
"input_schema": {...},
"cache_control": {"type": "ephemeral"} # ← ブレイクポイント2
}
],
messages=[
# 過去の会話履歴(シリアライズ方法を固定)
{"role": "user", "content": "前回の質問..."},
{"role": "assistant", "content": "前回の回答..."},
# 最新のユーザー入力(末尾 = 動的部分)
{"role": "user", "content": "今回の質問 + RAG結果 + タイムスタンプ"}
]
)
# キャッシュヒット率の確認
print(f"Cache Write: {response.usage.cache_creation_input_tokens}")
print(f"Cache Read: {response.usage.cache_read_input_tokens}") # ← これが大きいほど効率的
print(f"通常Input: {response.usage.input_tokens}")プロンプト全体を「岩盤(Bedrock)→ 砂(Sand)」の順に構造化します:
- System Prompt(不変) →
cache_control - Tools(ほぼ不変、順序固定) →
cache_control - 固定ドキュメント(セッション中不変) →
cache_control - 会話履歴(ターンごとに増加)
- ユーザー入力 + RAG + タイムスタンプ(毎回変動)
1〜3がキャッシュされ、4〜5だけが毎回新規計算されるのが理想形です。
参考文献
- rural writer「Prompt Cache:10倍コストを下げる仕組みと、それを無意識に台無しにする6つのミス」Zenn, 2025.
https://zenn.dev/ruralwritter/articles/4656b52b64a0ed - Nous Research「Hermes Agent」 ― 永続的記憶システムを備えた自律型AIエージェントフレームワーク.
https://github.com/NousResearch/hermes-agent - agentskills.io ― AIエージェントのスキル設計・オーケストレーションに関するリファレンス.
https://agentskills.io - Anthropic「Prompt Caching」公式ドキュメント.
https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching
全スライド一覧