はじめに:RAGの3つの構成要素
RAG(Retrieval-Augmented Generation)は、LLMの知識を外部データで拡張する技術です。その構造は、検索(Engine)、記憶(Fuel)、生成(Vehicle)の3つの要素で構成されています。
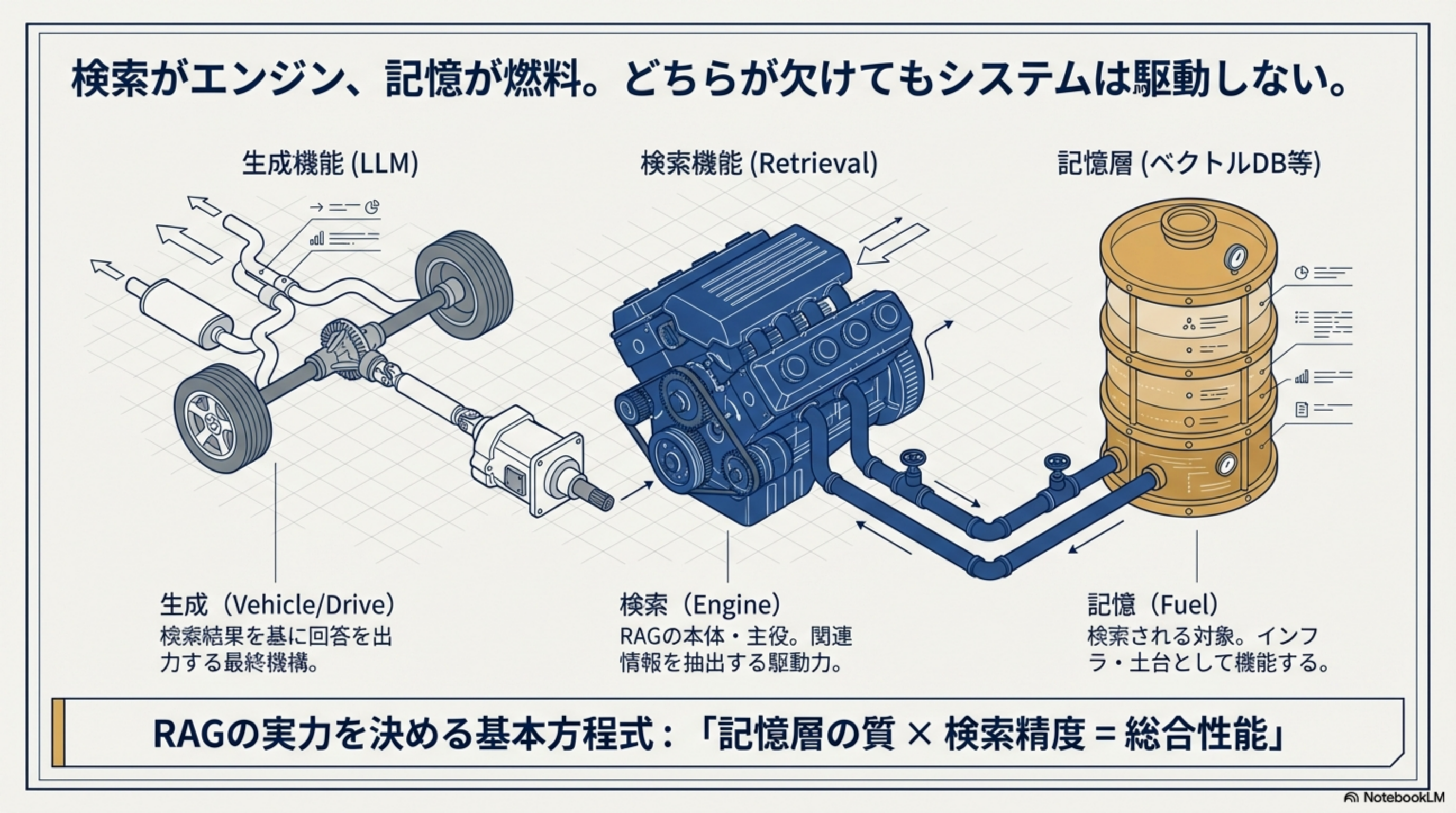
| 要素 | メタファー | 役割 |
|---|---|---|
| 検索機能(Retrieval) | Engine(エンジン) | RAGの本体・主役。関連情報を抽出する駆動力 |
| 記憶層(ベクトルDB等) | Fuel(燃料) | 検索される対象。インフラ・土台として機能する |
| 生成機能(LLM) | Vehicle(車体) | 検索結果を基に回答を出力する最終機構 |
RAGの実力を決める基本方程式
記憶層の質 × 検索精度 = 総合性能。どちらが欠けてもシステムは駆動しません。
この章で学べること
- 5つの検索方式(Vector / Keyword / Hybrid / Graph / Structured)
- Graph RAGの深掘り:5種類のグラフ構造
- アーキテクチャの進化階層(Naive → AI分身 RAG)
- 記憶インフラの設計:寿命 × スコープ
- 記憶パラダイムの転換:Read-only → Write-back
- 認知科学に基づく人間の記憶モデルのAI実装
- 全体統合ツリー:3層のマスターブループリント
1. 検索方式の最適化:エンジンの駆動モデルを選択する
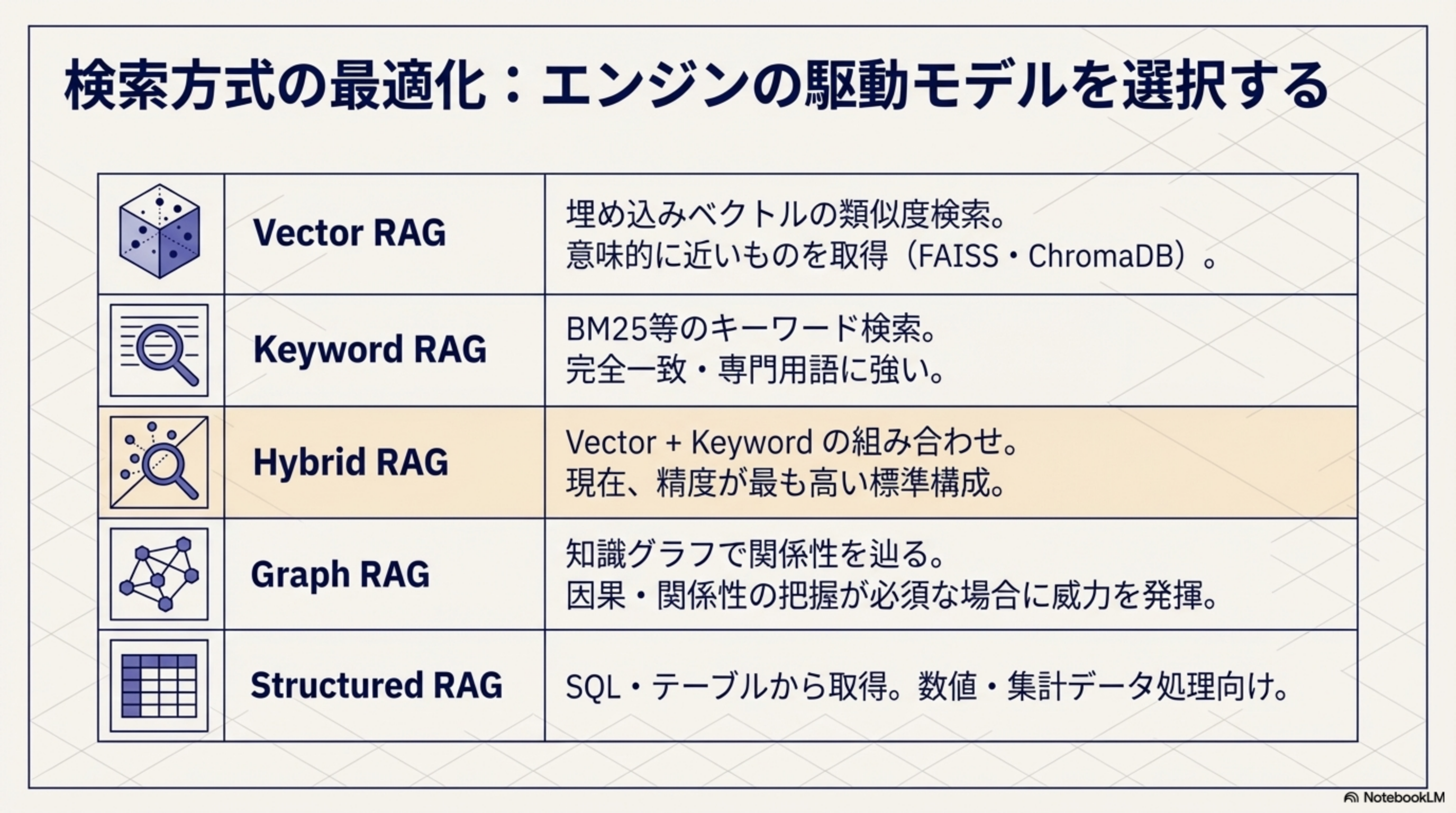
| 検索方式 | 仕組み | 強み |
|---|---|---|
| Vector RAG | 埋め込みベクトルの類似度検索 | 意味的に近いものを取得(FAISS・ChromaDB) |
| Keyword RAG | BM25等のキーワード検索 | 完全一致・専門用語に強い |
| Hybrid RAG | Vector + Keyword の組み合わせ | 現在、精度が最も高い標準構成 |
| Graph RAG | 知識グラフで関係性を辿る | 因果・関係性の把握が必須な場合に威力を発揮 |
| Structured RAG | SQL・テーブルから取得 | 数値・集計データ処理向け |
2. Graph RAGの深掘り:ベクトルを超えた関係性・因果律の抽出
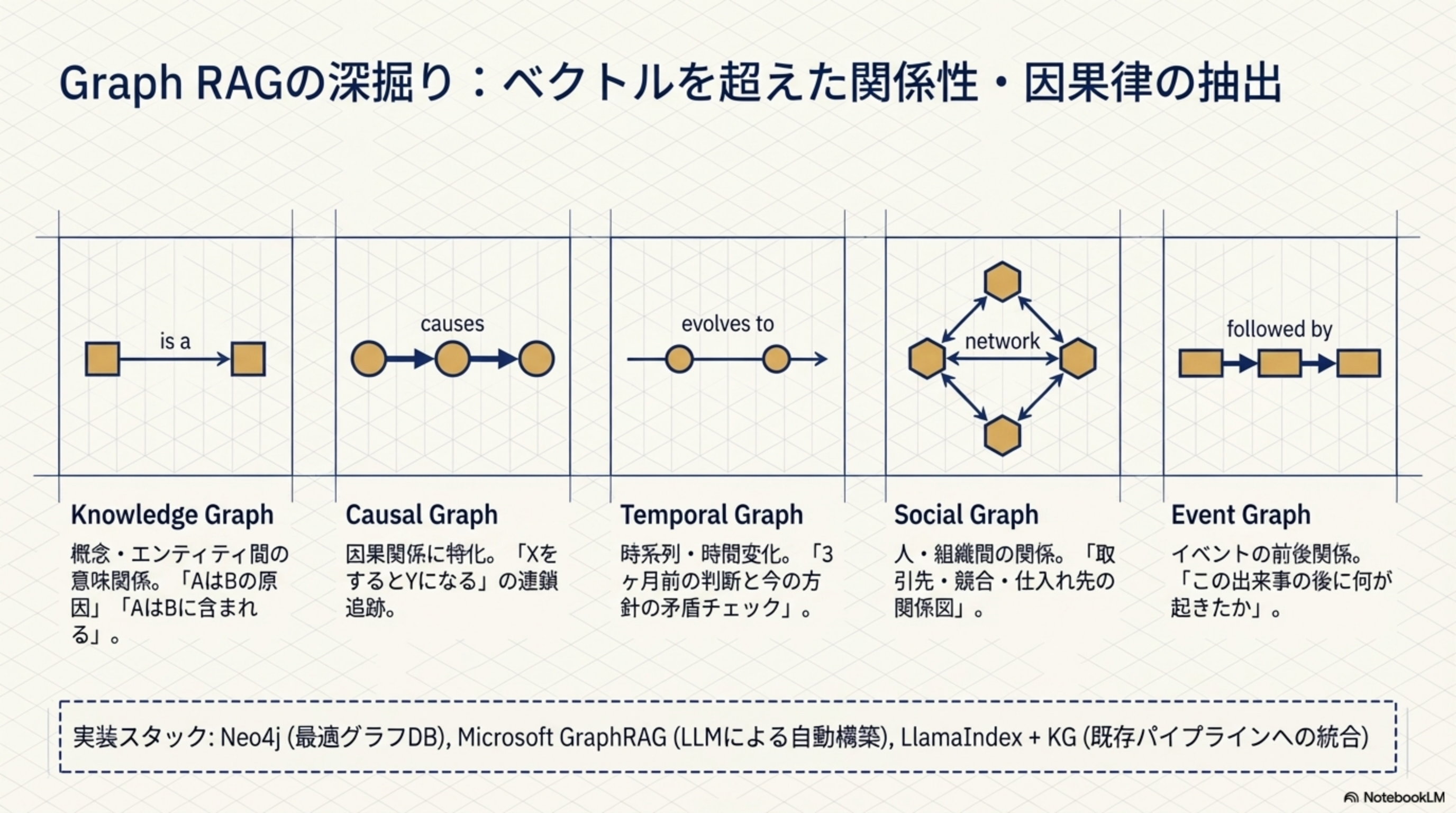
| グラフ種類 | 関係タイプ | 用途例 |
|---|---|---|
| Knowledge Graph | is a(意味関係) | 概念・エンティティ間の意味関係。「AはBの原因」「AはBに含まれる」 |
| Causal Graph | causes(因果関係) | 因果関係に特化。「XをするとYになる」の連鎖追跡 |
| Temporal Graph | evolves to(時間変化) | 時系列・時間変化。「3ヶ月前の判断と今の方針の矛盾チェック」 |
| Social Graph | network(人間関係) | 人・組織間の関係。「取引先・競合・仕入れ先の関係図」 |
| Event Graph | followed by(前後関係) | イベントの前後関係。「この出来事の後に何が起きたか」 |
実装スタック
Neo4j(最適グラフDB)、Microsoft GraphRAG(LLMによる自動構築)、LlamaIndex + KG(既存パイプラインへの統合)
3. アーキテクチャの進化:単一クエリから自律型「AI分身」への階層
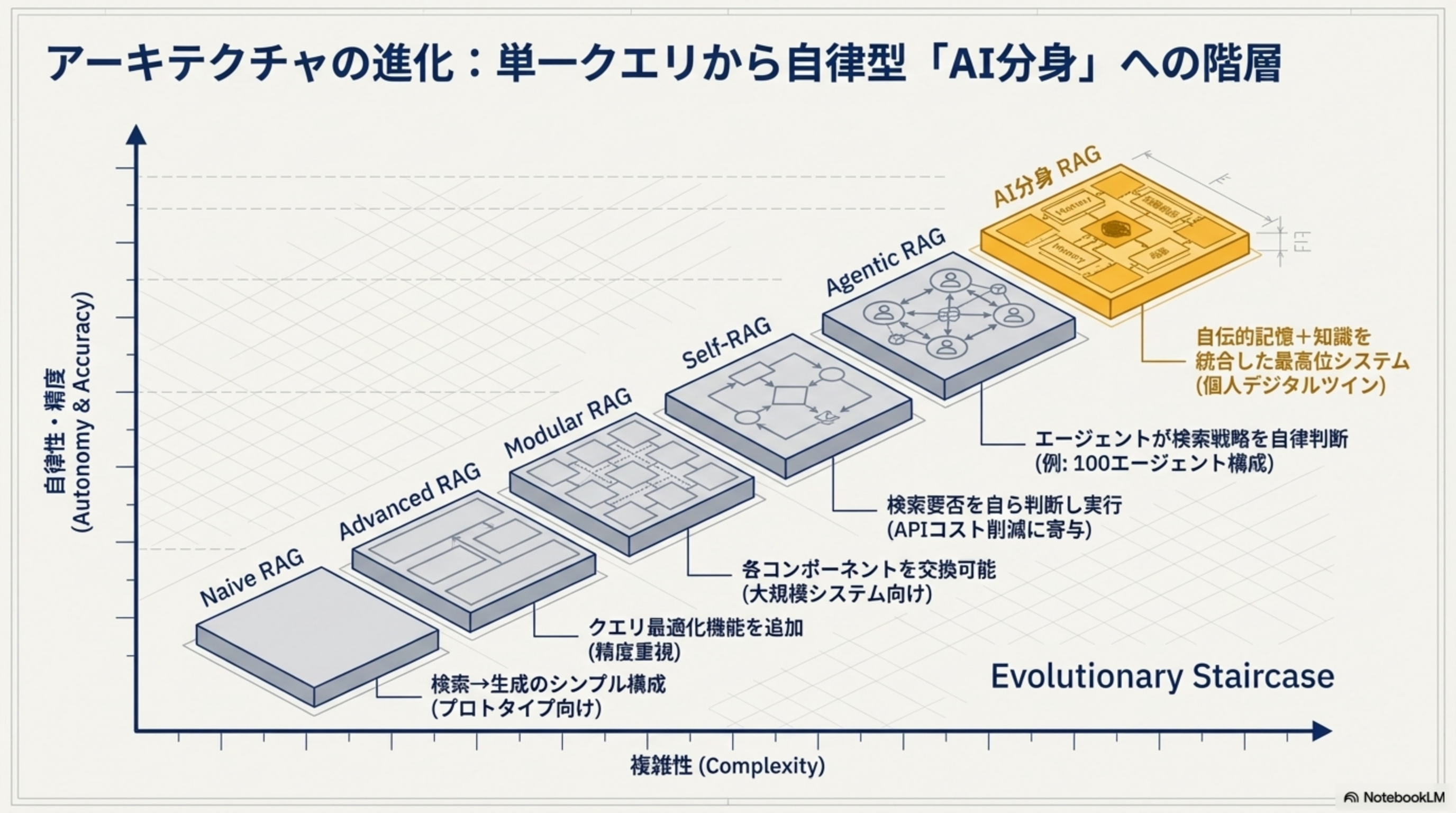
| 段階 | 特徴 |
|---|---|
| Naive RAG | 検索→生成のシンプル構成(プロトタイプ向け) |
| Advanced RAG | クエリ最適化機能を追加(精度重視) |
| Modular RAG | 各コンポーネントを交換可能(大規模システム向け) |
| Self-RAG | 検索要否を自ら判断し実行(APIコスト削減に寄与) |
| Agentic RAG | エージェントが検索戦略を自律判断(例:100エージェント構成) |
| AI分身 RAG | 自伝的記憶 + 知識を統合した最高位システム(個人デジタルツイン) |
4. 記憶インフラの設計:データの寿命と共有スコープ
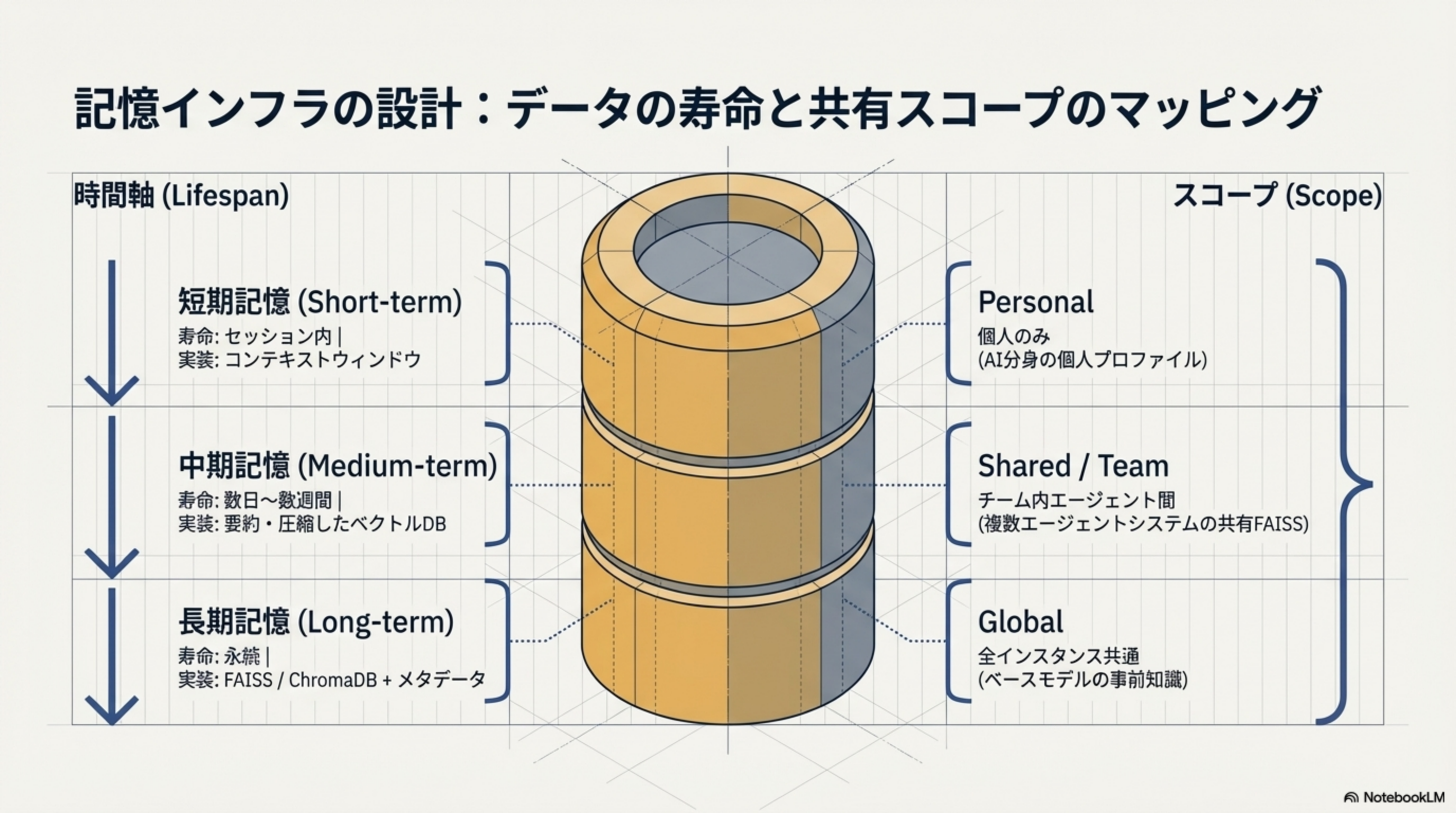
| 時間軸 | 寿命 | 実装 | スコープ |
|---|---|---|---|
| 短期記憶(Short-term) | セッション内 | コンテキストウィンドウ | Personal(個人のみ) |
| 中期記憶(Medium-term) | 数日〜数週間 | 要約・圧縮したベクトルDB | Shared / Team(チーム内エージェント間) |
| 長期記憶(Long-term) | 永続 | FAISS / ChromaDB + メタデータ | Global(全インスタンス共通) |
5. 記憶パラダイムの転換:Read-only → Write-back
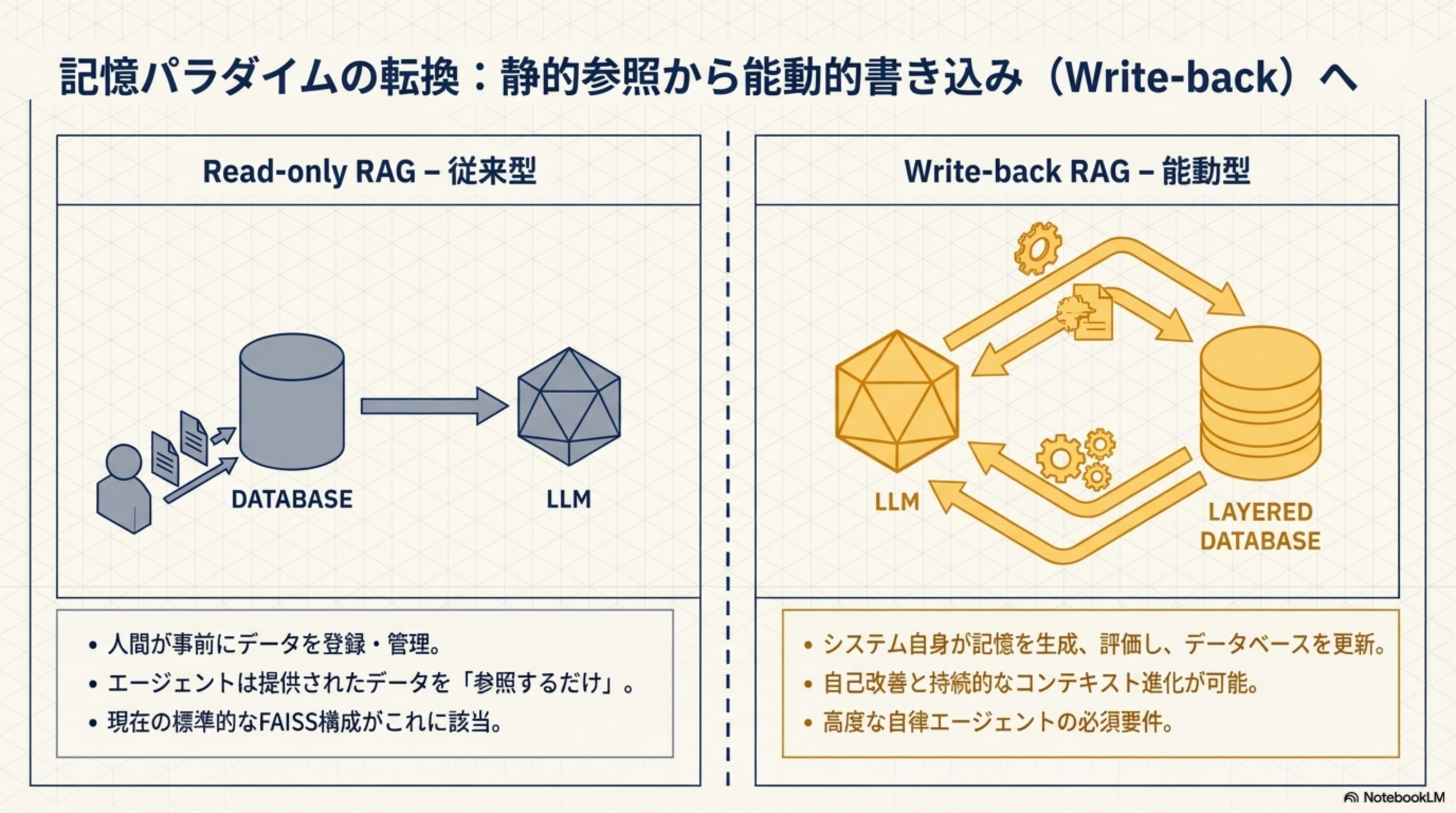
Read-only RAG — 従来型
- 人間が事前にデータを登録・管理
- エージェントは提供されたデータを「参照するだけ」
- 現在の標準的なFAISS構成がこれに該当
Write-back RAG — 能動型
- システム自身が記憶を生成、評価し、データベースを更新
- 自己改善と持続的なコンテキスト進化が可能
- 高度な自律エージェントの必須要件
能動的記憶更新(Write-back)の4つのトリガーメカニズム
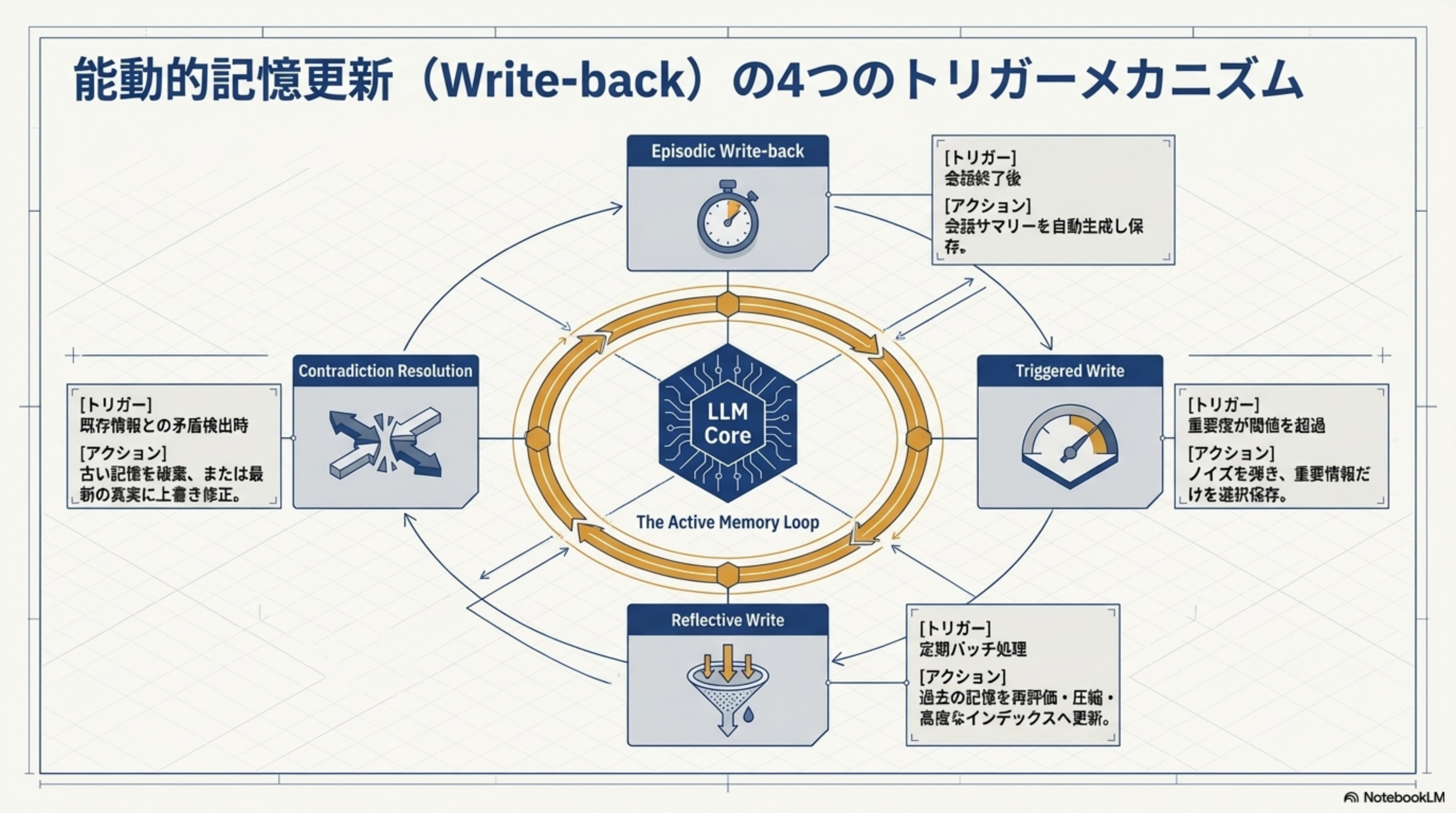
| メカニズム | トリガー | アクション |
|---|---|---|
| Episodic Write-back | 会話終了後 | 会話サマリーを自動生成し保存 |
| Triggered Write | 重要度が閾値を超過 | ノイズを弾き、重要情報だけを選択保存 |
| Reflective Write | 定期バッチ処理 | 過去の記憶を再評価・圧縮・高度なインデックスへ更新 |
| Contradiction Resolution | 既存情報との矛盾検出時 | 古い記憶を破棄、または最新の真実に上書き修正 |
6. 認知科学のアプローチ:人間の記憶モデルをAIに実装する
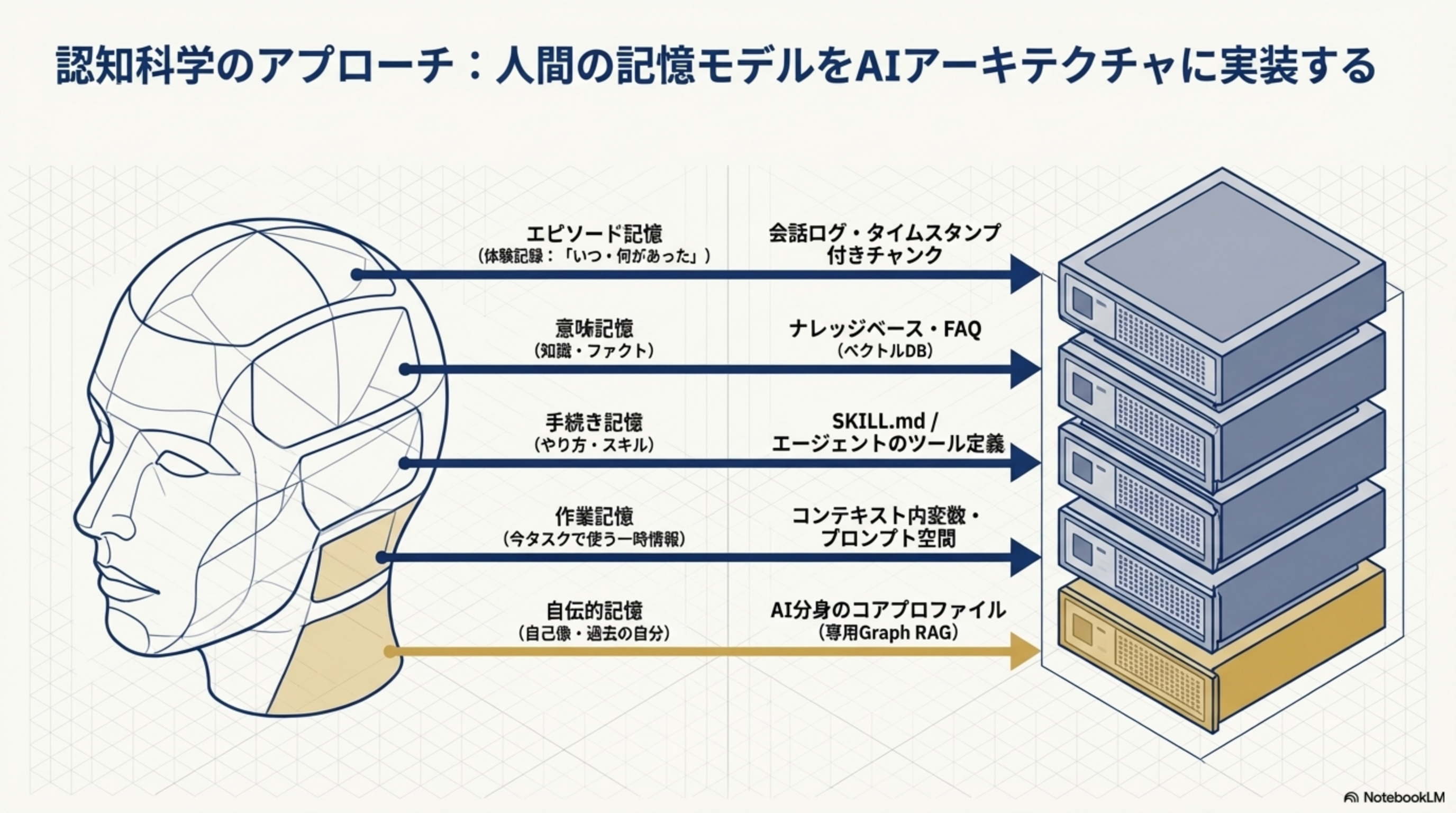
| 人間の記憶 | 内容 | AI実装 |
|---|---|---|
| エピソード記憶 | 体験記録:「いつ・何があった」 | 会話ログ・タイムスタンプ付きチャンク |
| 意味記憶 | 知識・ファクト | ナレッジベース・FAQ(ベクトルDB) |
| 手続き記憶 | やり方・スキル | SKILL.md / エージェントのツール定義 |
| 作業記憶 | 今タスクで使う一時情報 | コンテキスト内変数・プロンプト空間 |
| 自伝的記憶 | 自己像・過去の自分 | AI分身のコアプロファイル(専用Graph RAG) |
7. 全体統合ツリー:マスターブループリント
検索方式・アーキテクチャ・記憶層の3つのレイヤーが、どう組み合わさって最終的なシステムを構成するかの全体図です。
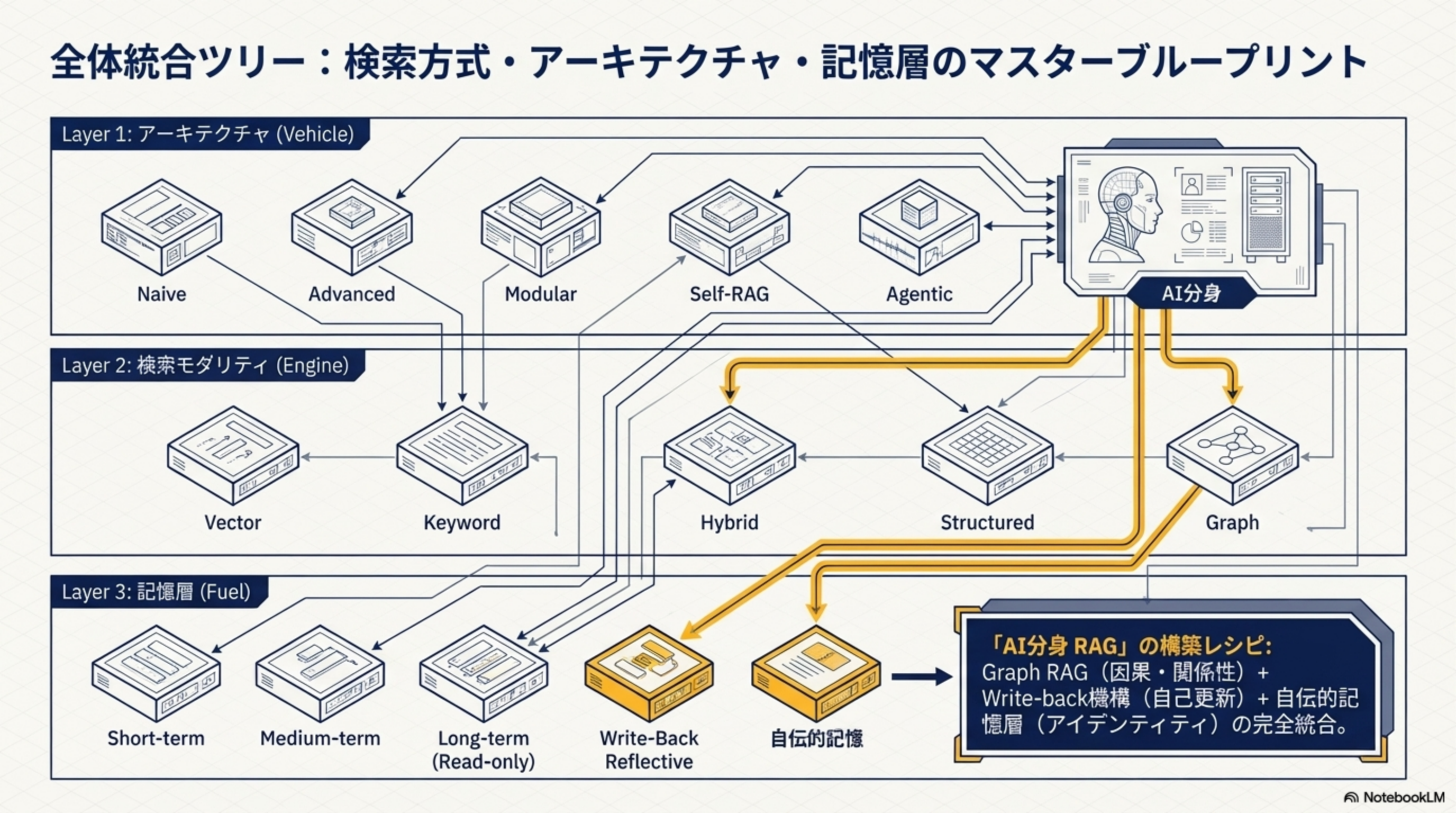
3層のマスターブループリント
- Layer 1: アーキテクチャ(Vehicle) - Naive → Advanced → Modular → Self-RAG → Agentic → AI分身
- Layer 2: 検索モダリティ(Engine) - Vector / Keyword / Hybrid / Structured / Graph
- Layer 3: 記憶層(Fuel) - Short-term / Medium-term / Long-term (Read-only) / Write-Back Reflective / 自伝的記憶
「AI分身 RAG」の構築レシピ
Graph RAG(因果・関係性)+ Write-back機構(自己更新)+ 自伝的記憶層(アイデンティティ)の完全統合。これが現時点で到達可能な最高位のRAGアーキテクチャです。
まとめ
核心メッセージ
- RAG = 検索(Engine)× 記憶(Fuel)× 生成(Vehicle)。どれが欠けても駆動しない
- 検索方式は5つ。現在の標準はHybrid RAG(Vector + Keyword)
- アーキテクチャは6段階の進化階層。最高位はAI分身 RAG
- 記憶は寿命(短期/中期/長期)× スコープ(Personal/Team/Global)の2軸で設計
- Read-only(参照型)→ Write-back(能動型)への転換が自律エージェントの鍵
- 人間の5つの記憶タイプ(エピソード/意味/手続き/作業/自伝的)をAIアーキテクチャに直接マッピングできる
元のスライド一覧
クリックで拡大表示できます