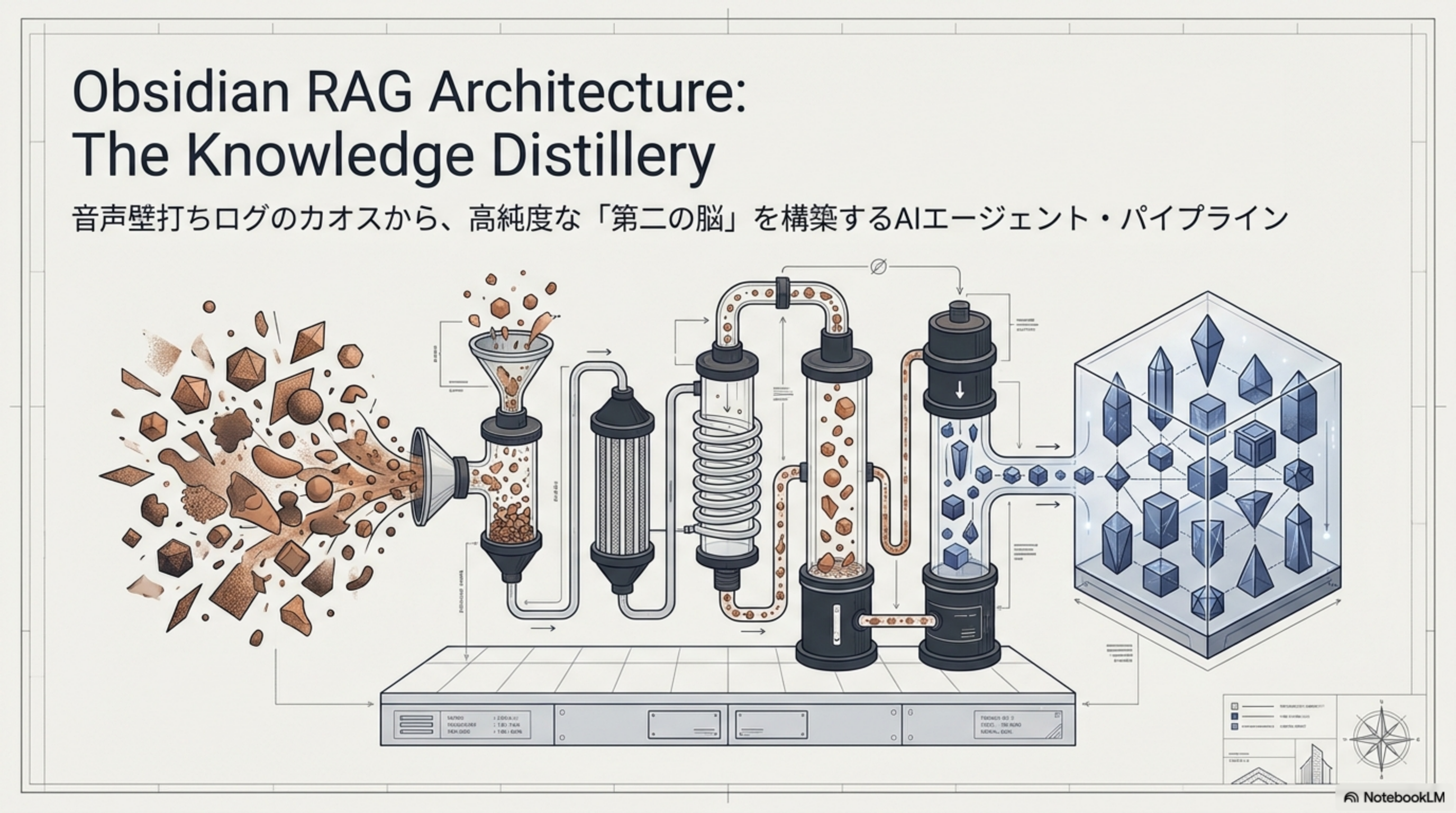
はじめに:カオスから結晶を取り出す蒸留装置
Obsidian Vault に蓄積された大量の音声書き起こしログ。そのままでは「未整理データの海」に過ぎません。The Knowledge Distillery は、この混沌から高純度な知識を蒸留するための AI エージェント・パイプラインです。RAG(Retrieval-Augmented Generation)アーキテクチャと組み合わせ、ノイズを除去し、ハルシネーションの自己強化ループを断ち切り、真に使える「第二の脳」を構築します。
- Obsidian RAG の4つのアプローチと採用戦略(ハイブリッド・アプローチ)
- 理想(Zettelkasten)と現実(未整理 2,345 ファイル)のギャップ
- ハルシネーションの自己強化ループというリスク
- 信号とノイズを分離する4つの戦略
- 4層 RAG システムアーキテクチャ
- 4段階の精製プロセス(Distillation Pipeline)
- Vault 再構築と「失われたナレッジ」の発見
- ファクトチェックの2つの次元とメトリクスの精緻化
Obsidian RAG の4つのアプローチ
Obsidian に RAG を導入する方法は大きく4つに分類できます。本設計図では、右上の「外部 RAG パイプライン」と左上の「ネイティブ機能の活用」を組み合わせたハイブリッド・アプローチを採用します。

| ネイティブ(Obsidian アプリ内) | 外部パイプライン | |
|---|---|---|
| 高度なバックエンド | ネイティブ機能の活用 バックリンク構造、Frontmatter (YAML)、Dataview クエリ |
外部 RAG パイプライン ★採用 ファイル監視による自動更新、ruri + ChromaDB + BM25 + RRF |
| 基本コーティリティ | プラグイン完結型 Smart Connections、Copilot for Obsidian、アプリ内の対話用途 |
同期ベース (Sync) PrivateGPT、AnythingLLM |
外部エージェントの自由度と、Obsidian の構造化メタデータを統合することで、最も柔軟で高品質な検索体験を実現します。
理想と現実:Vault のカオス
Obsidian の哲学は Zettelkasten(第二の脳)── ノード同士が密にリンクした知識のネットワークです。しかし現実の Vault は、未整理の音声書き起こしデータで溢れかえっています。
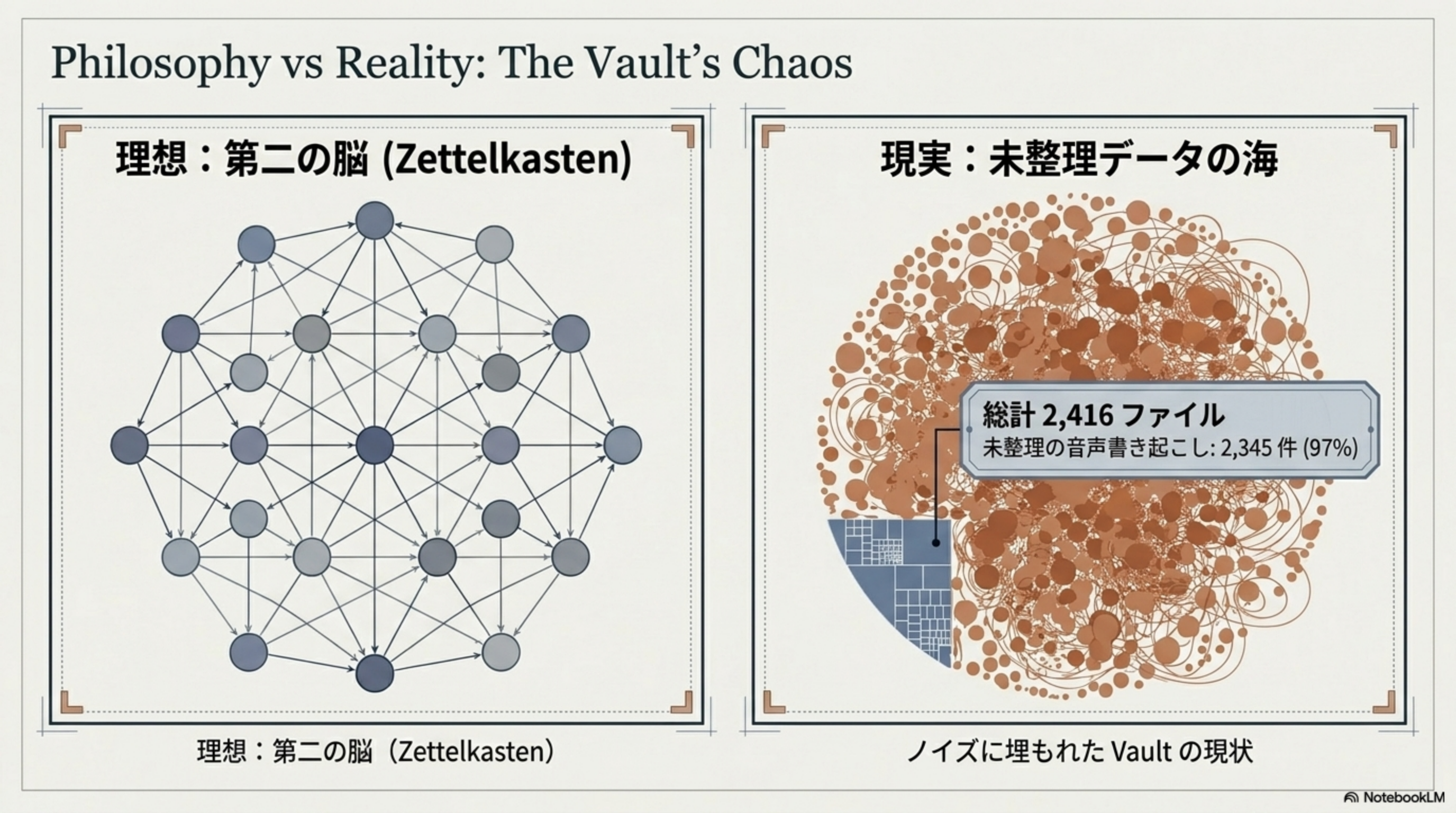
| 項目 | 理想 | 現実 |
|---|---|---|
| 構造 | ノード同士が密にリンクした知識ネットワーク | ノイズに埋もれた Vault |
| ファイル数 | 精選された構造化ノート | 総計 2,416 ファイル |
| データ品質 | 人間が整理・リンクした知識 | 未整理の音声書き起こし 2,345 件(97%) |
The Risk: ハルシネーションの自己強化ループ
未精製の壁打ちログをそのまま RAG のソースにすると、ハルシネーション(幻覚)が自己強化する危険な循環に陥ります。壁打ちログは人間の思考と AI の捏造の境界を曖昧にするのです。
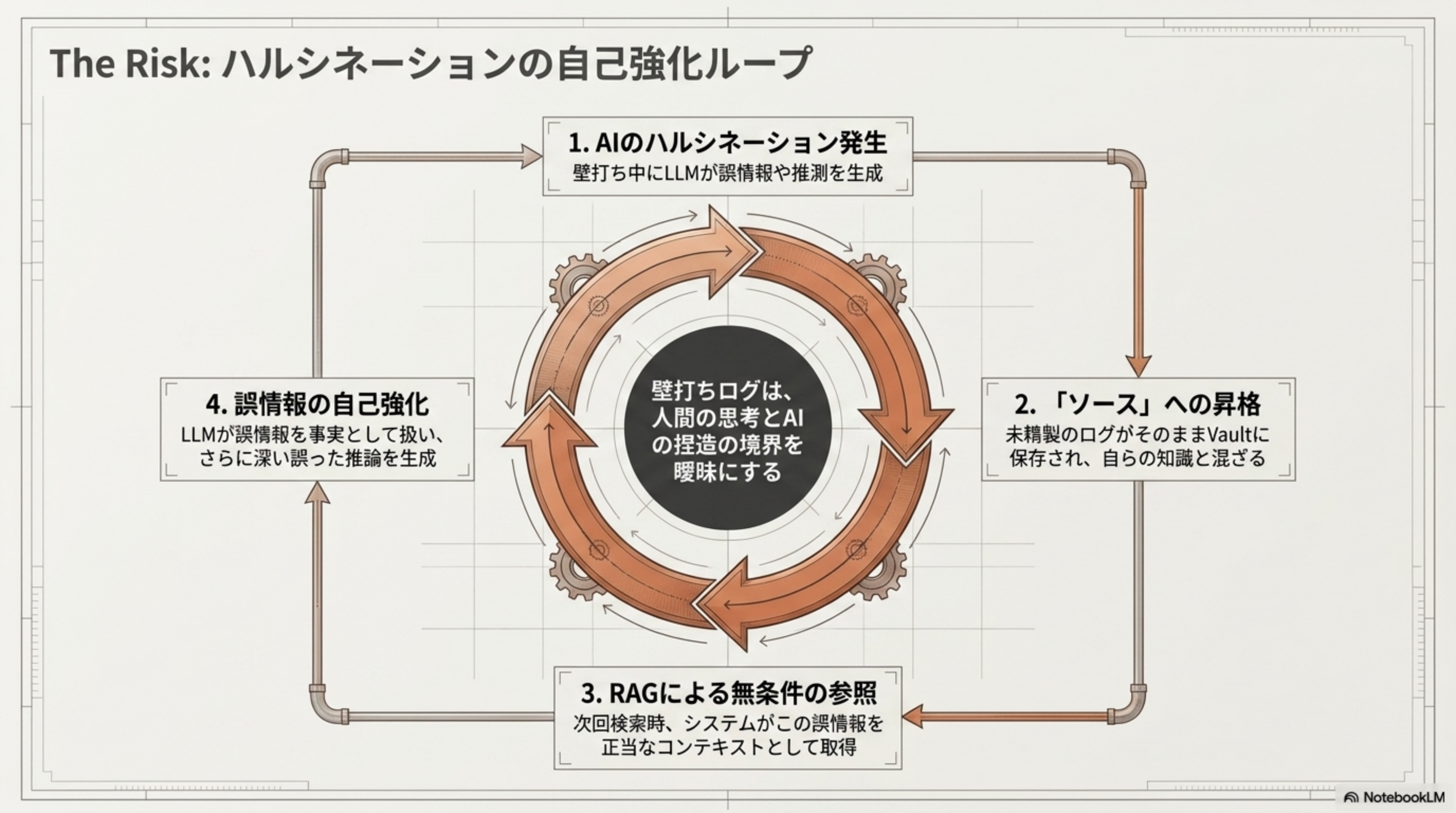
- AI のハルシネーション発生:壁打ち中に LLM が誤情報や推測を生成
- 「ソース」への昇格:未精製のログがそのまま Vault に保存され、自らの知識と混ざる
- RAG による無条件の参照:次回検索時、システムがこの誤情報を正当なコンテキストとして取得
- 誤情報の自己強化:LLM が誤情報を事実として扱い、さらに深く誤った推論を生成
信号とノイズを分離する4つの戦略
ハルシネーションの循環を断ち切るため、精製(Distillation)+ 分離(Separation)のアーキテクチャを採用します。4つの戦略で信号をノイズから救い出します。
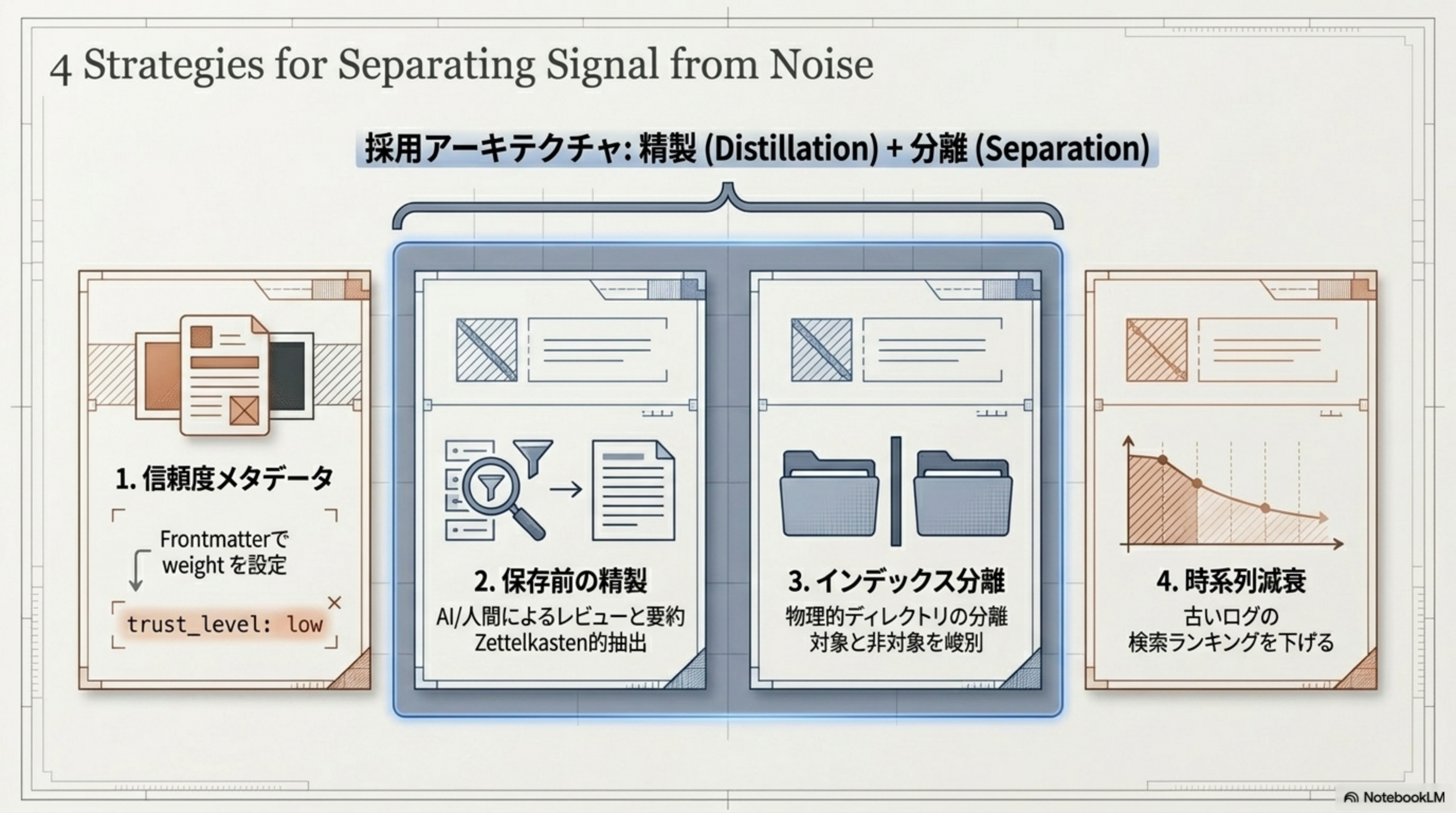
| # | 戦略 | 内容 |
|---|---|---|
| 1 | 信頼度メタデータ | Frontmatter で trust_level: low 等の weight を設定 |
| 2 | 保存前の精製 | AI/人間によるレビューと要約の Zettelkasten 的抽出 |
| 3 | インデックス分離 | 物理的ディレクトリの分離。対象と非対象を峻別 |
| 4 | 時系列減衰 | 古いログの検索ランキングを下げる |
The Architecture Stack: 4層 RAG システム
蒸留パイプラインを支えるのは、データ層 → 変換層 → 検索層 → エージェント層の4層アーキテクチャです。各層が独立しつつ、データフローで緊密に連携します。
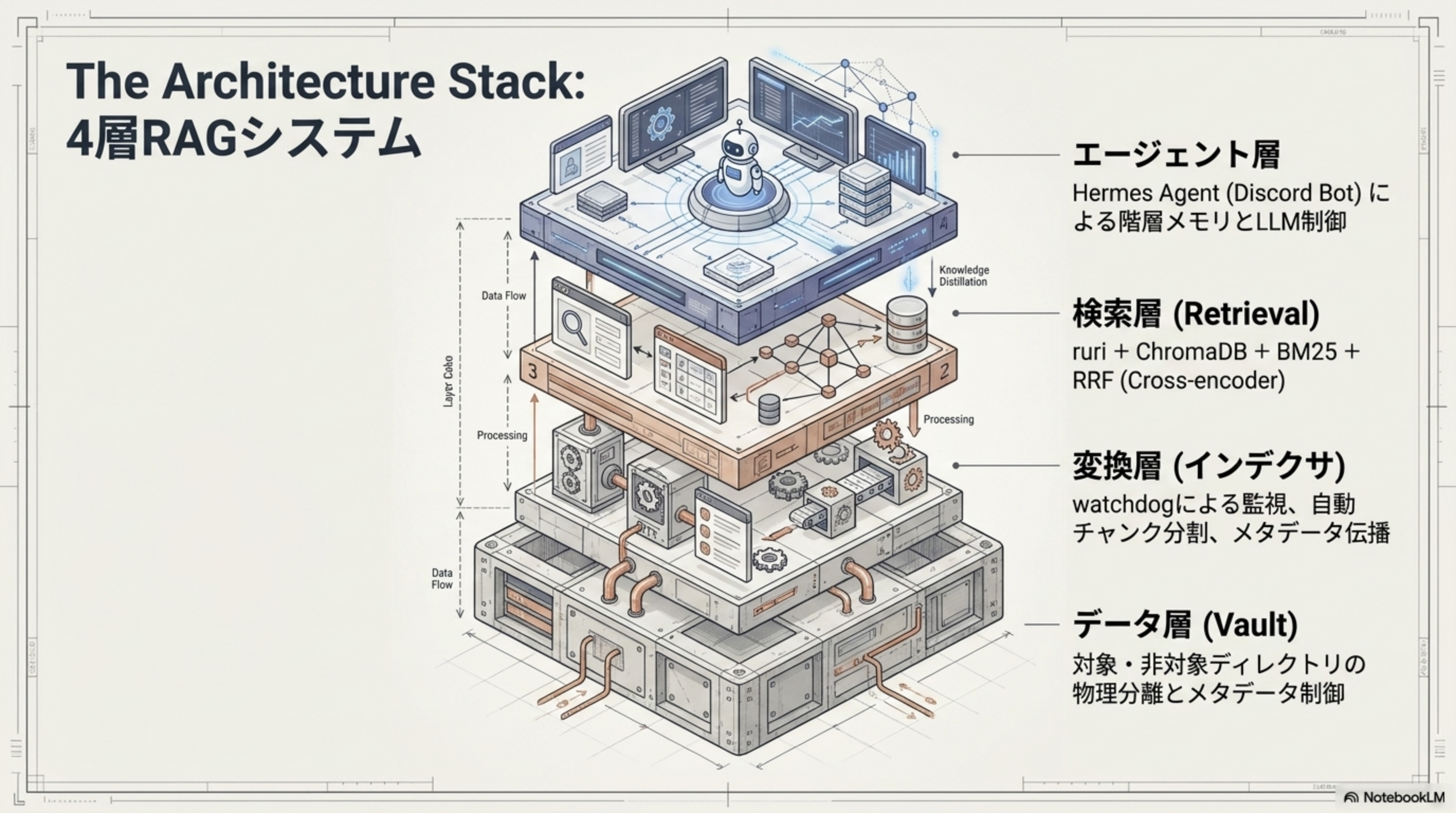
| レイヤー | 役割 | 主な技術要素 |
|---|---|---|
| エージェント層 | 階層メモリと LLM 制御 | Hermes Agent (Discord Bot) |
| 検索層 (Retrieval) | ハイブリッド検索とリランキング | ruri + ChromaDB + BM25 + RRF (Cross-encoder) |
| 変換層 (インデクサ) | ファイル監視と自動チャンク分割 | watchdog による監視、メタデータ伝播 |
| データ層 (Vault) | 物理分離とメタデータ制御 | 対象・非対象ディレクトリの分離 |
The Distillation Pipeline: 4段階の精製プロセス
2,345 件の未精製ログを高純度なナレッジに変換する、4段階の精製プロセスです。各ステージの工数とコスト目安も示します。
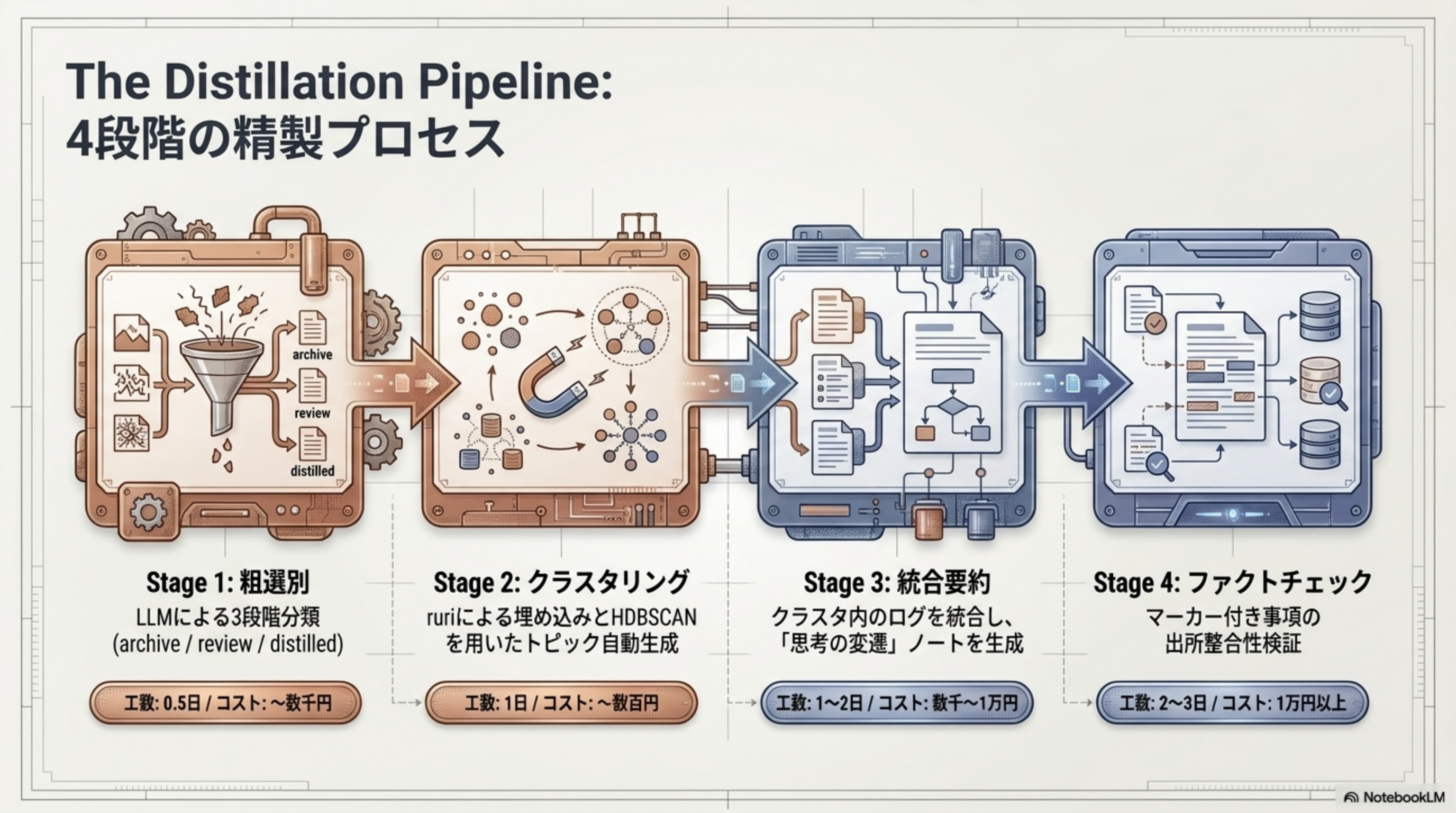
| Stage | 処理内容 | 工数 | コスト |
|---|---|---|---|
| 1. 粗選別 | LLM による3段階分類(archive / review / distilled) | 0.5 日 | 〜数千円 |
| 2. クラスタリング | ruri による埋め込みと HDBSCAN を用いたトピック自動生成 | 1 日 | 〜数百円 |
| 3. 統合要約 | クラスタ内のログを統合し、「思考の変遷」ノートを生成 | 1〜2 日 | 数千〜1 万円 |
| 4. ファクトチェック | マーカー付き事項の出所整合性検証 | 2〜3 日 | 1 万円以上 |
Execution Results: 2,345のノイズから7つの「結晶」へ
精製パイプラインを実行した結果、2,345 件の未整理ログから 7つの高純度トピック(結晶)が抽出されました。

| # | トピック(結晶) |
|---|---|
| 1 | AI-コーディング |
| 2 | AI-モデル基礎 |
| 3 | RAG-ナレッジ管理 |
| 4 | 業務-EC-決済 |
| 5 | 法務-税務-行政 |
| 6 | 社会-交通 |
| 7 | その他 |
Vault Restructuring: 情報アーキテクチャの再構築
精製プロセスに合わせ、Vault のディレクトリ構造も再設計しました。「目的不明の肥大化」から「役割が明確な階層構造」への転換です。
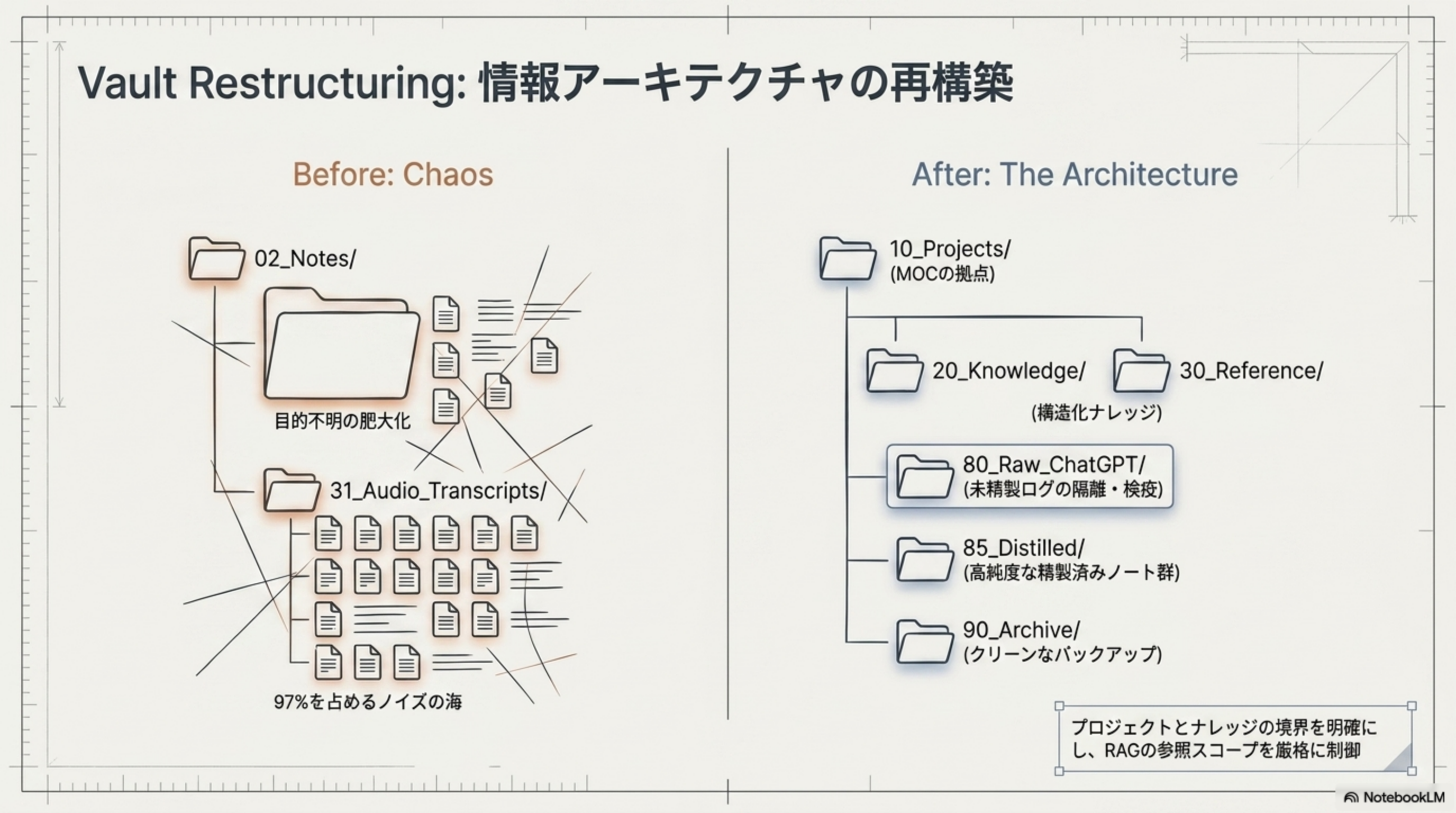
| ディレクトリ | 役割 |
|---|---|
10_Projects/ | MOC の拠点(Map of Content) |
20_Knowledge/ | 構造化ナレッジ |
30_Reference/ | 参照資料 |
80_Raw_ChatGPT/ | 未精製ログの隔離・検疫 |
85_Distilled/ | 高純度な精製済みノート群 |
90_Archive/ | クリーンなバックアップ |
プロジェクトとナレッジの境界を明確にし、RAG の参照スコープを厳格に制御します。80_Raw_ChatGPT/ を検索対象から除外することで、ハルシネーションの汚染を防ぎます。
Structural Epiphany:「失われたナレッジ」の発見
システム構築の過程で、システム自体が抱える最大の死角(盲点)が浮き彫りになりました。それは「水面下」に沈んでいた最も重要な知識の不在です。
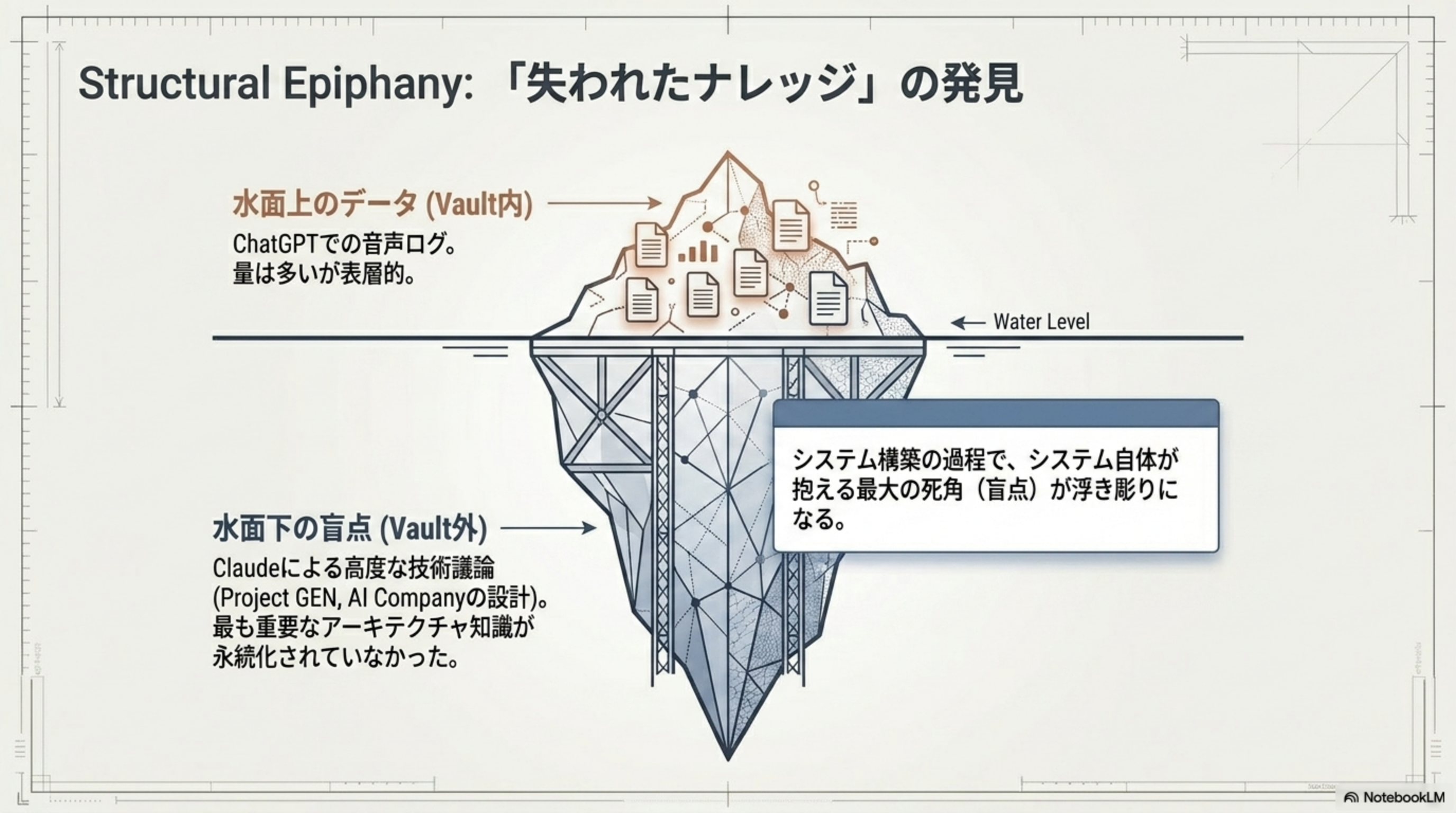
| 領域 | 内容 | 特徴 |
|---|---|---|
| 水面上 (Vault 内) | ChatGPT での音声ログ | 量は多いが表層的 |
| 水面下 (Vault 外) | Claude による高度な技術議論(Project GEN, AI Company の設計) | 最も重要なアーキテクチャ知識が永続化されていなかった |
Claude の履歴エクスポートと Vault への統合が急務です。最も価値の高い知識が検索対象に含まれていないという、システムの根本的な盲点が明らかになりました。
Quality Control: ファクトチェックにおける「2つの次元」
ファクトチェック(Stage 4)には2つの異なる次元があります。パイプラインの責任分界点を明確にすることが品質管理の鍵です。

| 次元1: 転写忠実性 (Transcription Fidelity) | 次元2: 事実検証 (Fact Verification) | |
|---|---|---|
| 対象 | 精製ノート vs 生の音声書き起こし | 精製ノート vs 外部世界 (Web/現実) |
| 目的 | AI が要約時に新たな捏造(創作)をしていないかの確認 | ユーザーが発言した元のアイデア自体が真実であるかの担保 |
| ステータス | Stage 4 にて実装・完了(文字列の整合・出所チェック) | Stage 4b(別レイヤー)へ移行・待機中 |
Stage 4 のスコープを「転写忠実性」に限定することで、パイプラインの責任分界点を明確化しています。
Normalizing Metrics: レポートの精緻化
初期実行時のメトリクスにはノイズが含まれていました。「Unknown」は検証対象外(該当なし)であったため、分母から除外するロジック修正を行い、100% のクリーンな状態に到達しました。
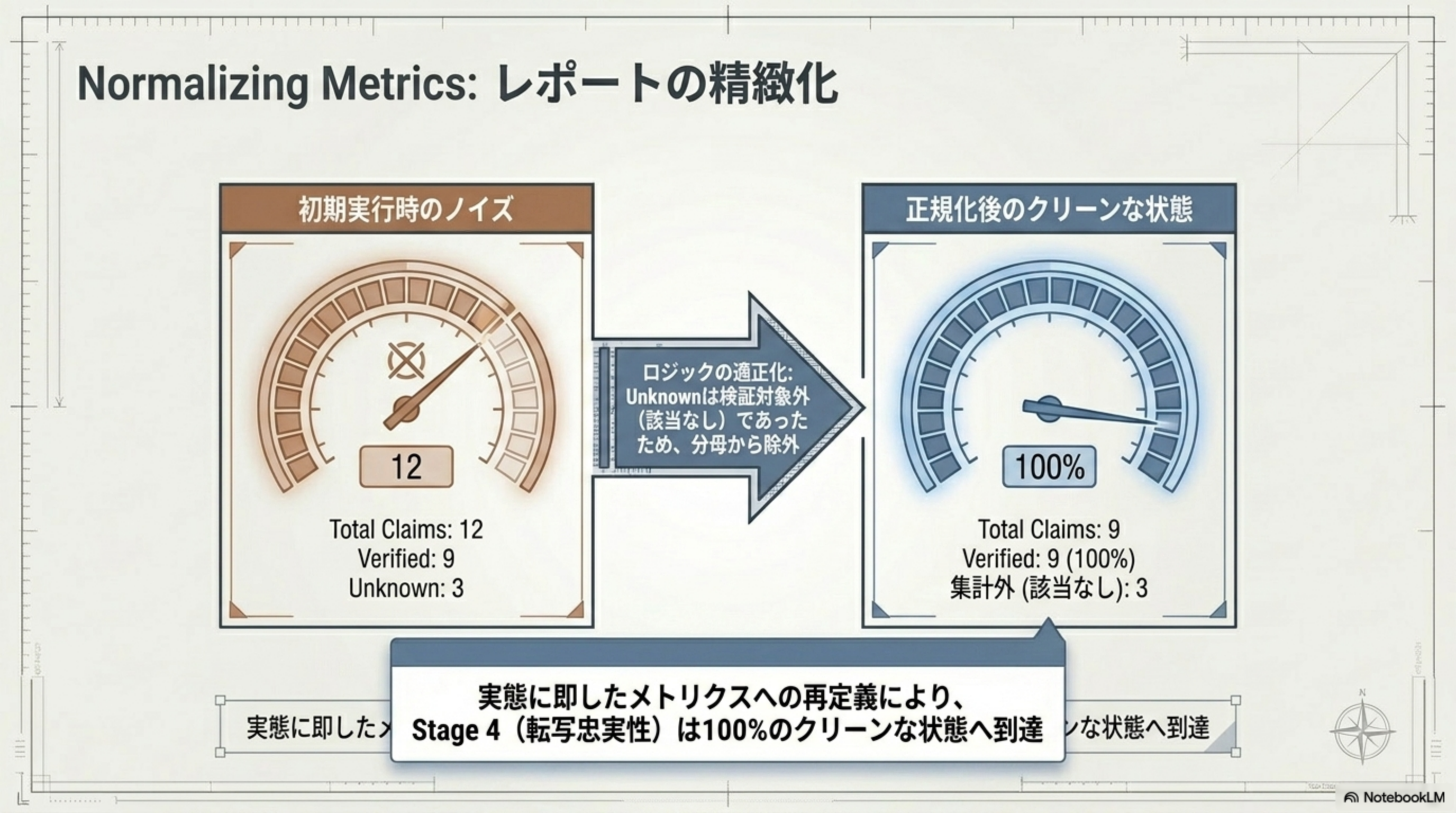
| 初期実行時のノイズ | 正規化後のクリーンな状態 | |
|---|---|---|
| Total Claims | 12 | 9 |
| Verified | 9 | 9 (100%) |
| Unknown | 3 | 集計外(該当なし): 3 |
Next Steps: 進化のロードマップ
現在地から段階的にシステムを進化させるロードマップです。
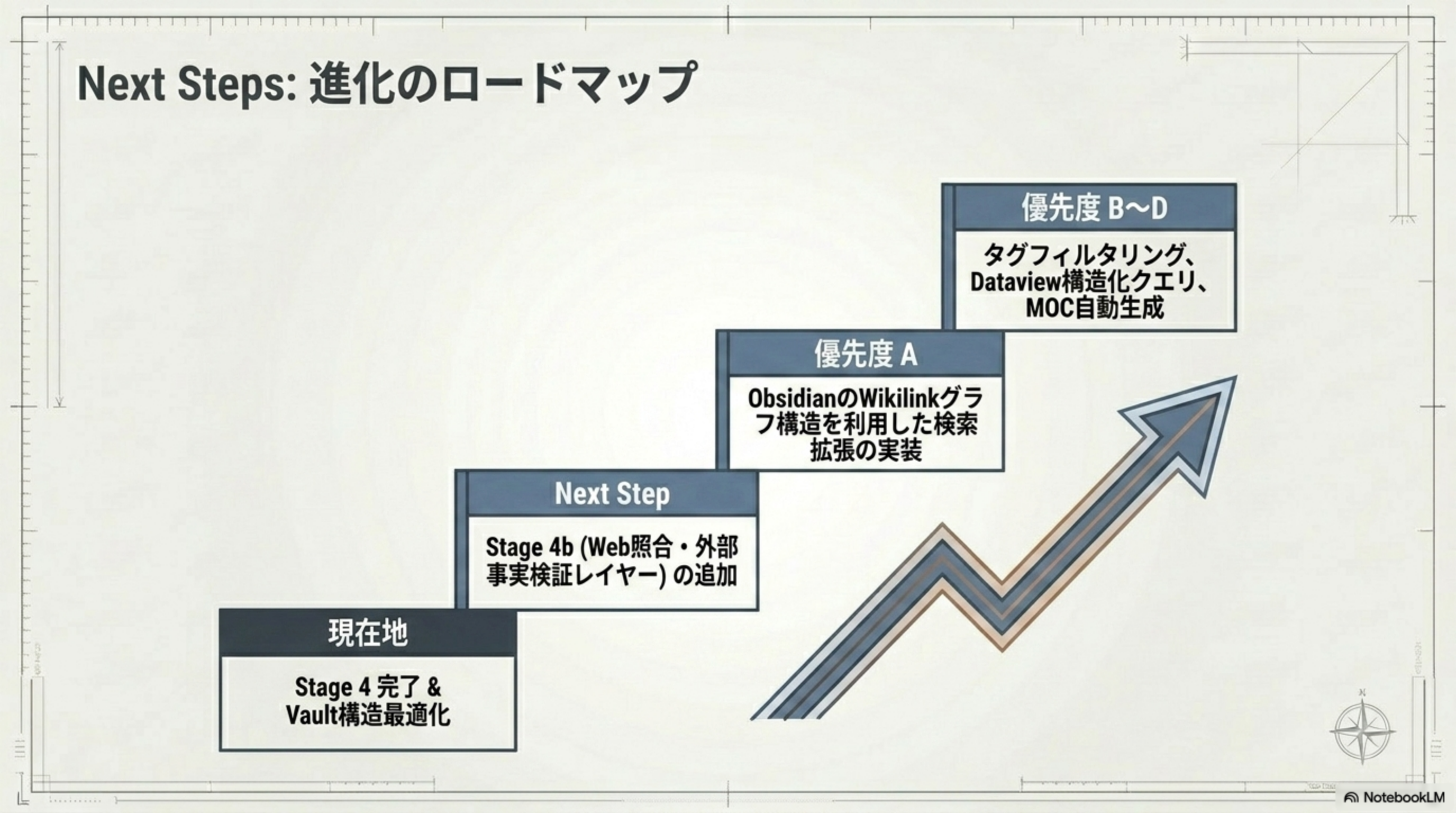
| 段階 | 内容 |
|---|---|
| 現在地 | Stage 4 完了 & Vault 構造最適化 |
| Next Step | Stage 4b (Web 照合・外部事実検証レイヤー) の追加 |
| 優先度 A | Obsidian の Wikilink グラフ構造を利用した検索拡張の実装 |
| 優先度 B〜D | タグフィルタリング、Dataview 構造化クエリ、MOC 自動生成 |
Handover Summary
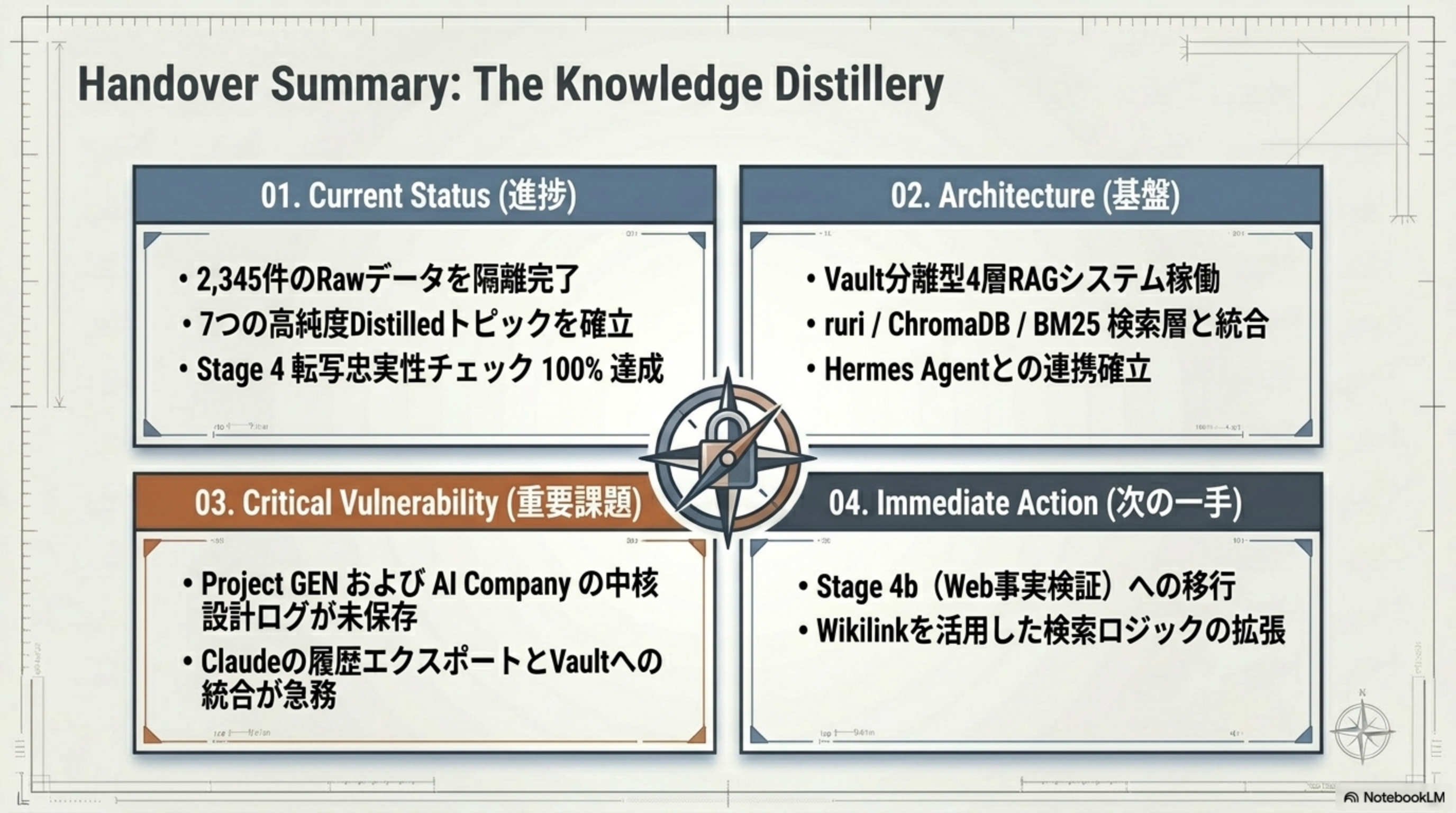
- 2,345 件の Raw データを隔離完了
- 7つの高純度 Distilled トピックを確立
- Stage 4 転写忠実性チェック 100% 達成
- Vault 分離型4層 RAG システム稼働
- ruri / ChromaDB / BM25 検索層と統合
- Hermes Agent との連携確立
- Project GEN および AI Company の中核設計ログが未保存
- Claude の履歴エクスポートと Vault への統合が急務
- Stage 4b(Web 事実検証)への移行
- Wikilink を活用した検索ロジックの拡張
まとめ:蒸留が変える知識管理の未来
The Knowledge Distillery は、「とりあえず保存」の知識管理から「精製して活用」への転換を実現するアーキテクチャです。ハルシネーションの自己強化ループという致命的リスクを可視化し、4段階の精製プロセスでそれを断ち切ります。
- RAG の基礎理論(RAGアーキテクチャ設計)
- LLM のメモリ構造(LLMメモリ・アーキテクチャ)
- Hermes Agent の構築(Hermes Agent 完全構築設計図)
- エージェント設計の基礎(AIエージェント設計図)
元のスライド一覧
クリックで拡大表示できます